Patient Registry Automation
Patient registries are foundational infrastructure for cancer surveillance, quality improvement, regulatory compliance, and clinical research. Yet traditional registry development remains one of healthcare's most resource-intensive operational challenges — requiring months of manual chart abstraction by certified, specialized staff who extract hundreds of data points per patient from fragmented, multimodal clinical documentation. Patient Journey Intelligence transforms registry operations from a chronically under-resourced manual burden into an automated, continuously updated asset. By combining multimodal AI, oncology-specific agentic workflows, and structured human oversight, Patient Journey Intelligence achieves expert-level accuracy at scale - building registries that reflect every patient's reality and update daily, with less fatigue and fewer errors.
What Is a Patient Registry?
A patient registry is a systematic, population-level collection of standardized data about patients with a specific condition, treatment exposure, or clinical characteristic. Registries capture demographics, diagnosis details, disease characteristics (e.g., tumor morphology and behavior, TNM staging), treatment protocols, and long-term outcomes.

They power critical functions across the healthcare ecosystem:
- Public health policy and resource allocation: Monitoring cancer incidence, survival trends, and population-level outcomes over time
- Clinical research cohort infrastructure: Identifying and following patient populations for retrospective studies and clinical trials
- Quality of care measurement: Benchmarking institutional performance against national standards and peer institutions
- Regulatory reporting and accreditation: Meeting mandatory reporting requirements to state registries, national programs, and accreditation bodies
- International comparations between effectiveness of care: Enabling cross-institutional and cross-national analysis of treatment patterns and outcomes
What Registries Can and Cannot Answer
Well-maintained registries answer questions about disease frequency (which cancers occur most often, how are they distributed by age and gender), epidemiological trends (how is incidence changing, are certain cancers more common in specific regions), health risks (survival rates, risk of recurrence, long-term complications), and quality of care (regional variation, institutional benchmarking).
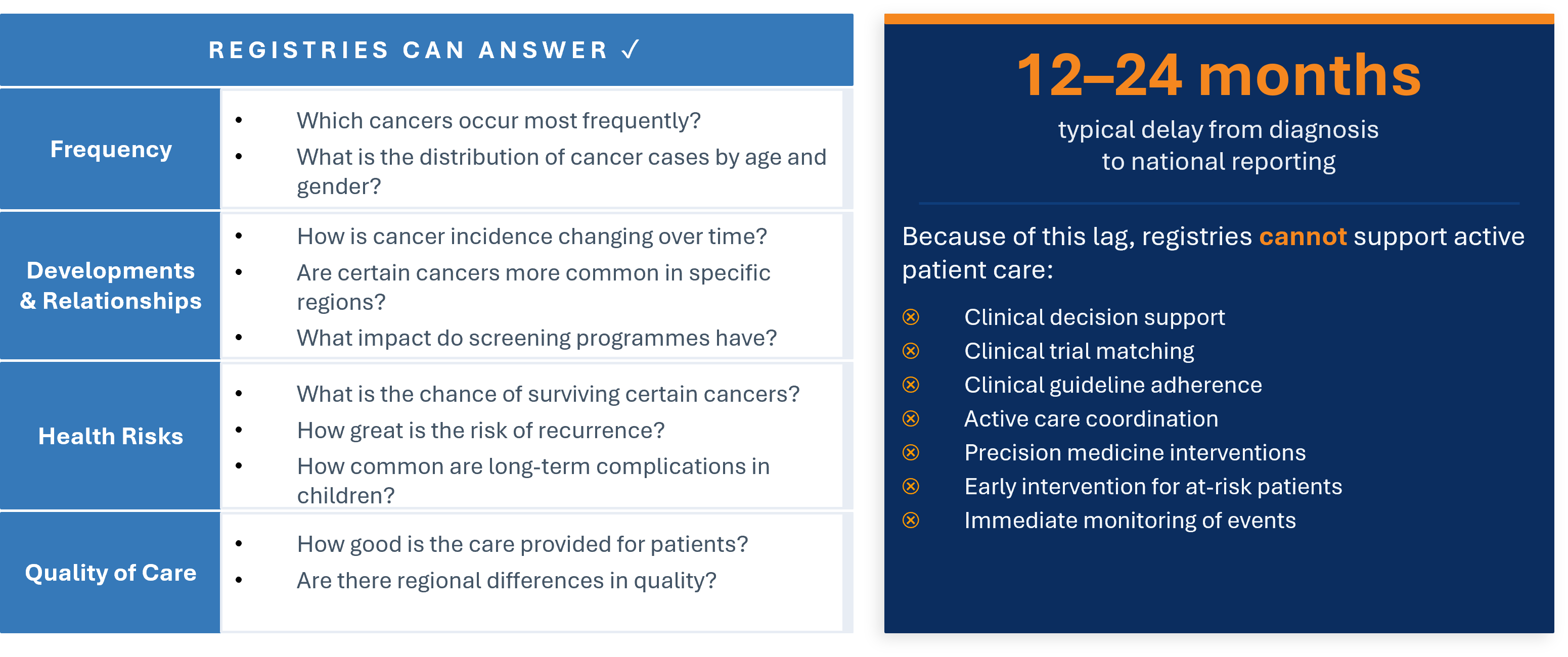
However, traditional registries suffer from a critical structural limitation: a 12–24 month typical delay from diagnosis to national reporting. Because of this lag, conventional registries cannot support active patient care:
| Capability | Traditional Registry | Patient Journey Intelligence |
|---|---|---|
| Clinical decision support | ✗ | ✓ |
| Clinical trial matching | ✗ | ✓ |
| Guideline adherence monitoring | ✗ | ✓ |
| Active care coordination | ✗ | ✓ |
| Precision medicine interventions | ✗ | ✓ |
| Early intervention for at-risk patients | ✗ | ✓ |
| Immediate monitoring of clinical events | ✗ | ✓ |
Patient Journey Intelligence closes this gap by delivering near-real-time registry data that actively supports all seven clinical use cases above.
The Registry Challenge: Manual, Specialized, and Chronically Under-Resourced
The problem with traditional registries is not that the data is wrong. It is that the process of building and maintaining them is manual, slow, and structurally under-resourced.
Manual Chart Abstraction is Prohibitively Slow
Registry abstraction requires trained staff to manually review clinical charts and extract standardized data elements. Industry studies reveal the time investment required:
- Trauma registries: 70-90 minutes per chart on average, with complex cases taking up to 2 hours (ImageTrend TRRR study)
- Cardiovascular registries: Up to 1 hour per chart for experienced abstractors working with ACC-NCDR registries like CathPCI (with over 270 data elements)
- Time varies significantly based on case complexity, documentation quality, and abstractor experience

Cancer registry abstraction requires an average of ~2 hours per case of manual chart review. A typical Oncology Data Specialist (ODS) processes 6–8 cases per day, while carrying a load of 15,000+ cases per year. Against an industry standard requiring 90% of cases to be reported within 12 months of diagnosis, only 14% of registries meet this NPCR timeliness target. The average national reporting lag stands at 23 months.
The financial burden compounds the operational one: ODS salaries range from $60,000–$90,000 annually, and each retiring specialist effectively requires the resources of three new hires to maintain the same throughput.
Specialized Training and Certification Requirements
Registry abstractors require extensive education and ongoing certification:
- CTR (Certified Tumor Registrar): Requires more than 2 years of work experience to sit for NCRA certification exam, plus 20 hours of continuing education every 2 years to maintain certification
- Cardiovascular registries: Prefer nurses or staff with 2+ years of cath lab experience
- Limited talent pool: Specialized knowledge requirements create staffing challenges and high labor costs
The Guidelines Complexity and Continuous Update
Cancer registry standards are extraordinarily demanding. The NAACCR data dictionary, combined with AJCC and SEER guidelines, spans 2,500+ pages of rules. The NAACCR data model itself contains over 750 data fields, with 200–250 required for a typical adult case. AJCC staging system revisions (published every 6–8 years) each introduce changes to staging criteria, new biomarker requirements, and revised anatomic classifications, and registrars must master every edition. The 2018 specification changes alone doubled abstracting time per case.
Incomplete Case Capture
Manual identification processes inevitably miss cases:
- Abstractors rely on diagnosis codes and procedure flags that may be incomplete or delayed
- Cases documented primarily in clinical notes rather than structured fields go undetected
- Patients treated across multiple facilities may not be captured in all relevant registries
Why Naive AI Approaches Fail for Automatic Cancer Registry Abstraction

The intuitive response to the above challenges would be to feed all documents for a patient into a large language model. This does not work in practice for several fundamental reasons:
-
Context window limitations: A 1M-token context window corresponds to approximately 1,000 pages. A single cancer patient's complete record often exceeds 5,000 pages. The NAACCR/SEER/AJCC guidelines alone exceed this limit. Furthermore, model performance degrades substantially as context length increases (the "context rot" phenomenon), making large-window approaches unreliable even when technically feasible.
-
Regulatory rigor: General-purpose LLMs lack the specialized reasoning layers required to apply 2,500+ pages of SEER/AJCC coding rules consistently and correctly across diverse cancer types and clinical scenarios.
-
Multimodal clinical data: Cancer cases require integrating pathology reports (text and tables), radiology reports, genomic test results, and physician notes. Single-modality models systematically miss cross-referencing cues that are essential for accurate staging.
-
Deterministic inference: Registry data must be reproducible. The same patient record must produce the same abstraction result regardless of when or how it is processed. Stochastic LLM outputs fail this requirement.
-
Auditability: Registries require that every data element be traceable to a specific source document and text span. Black-box LLM outputs are rejected by regulatory reviewers.
Why Patient-Level Reasoning Is Required
A cancer patient cannot be considered as a collection of documents. Naively combining extracted fields from multiple documents produces structurally incorrect data for three reasons:
-
Temporal conflict: A pre-surgical clinical staging estimate may be superseded by the pathologic stage determined after resection. Without temporal ordering, both values receive equal weight and the result is wrong.
-
Assertion revision: A mass flagged on imaging may subsequently be biopsied and proven benign. A preliminary histology may be upgraded after immunohistochemistry. Without assertion tracking, outdated diagnoses persist alongside corrections.
-
Deduplication: Multiple documents from the same clinical encounter will reference the same event. Naive stacking creates artificial duplication of evidence, inflating confidence in incorrect values.
Patient Journey Intelligence resolves all three challenges through chronological encounter grouping, assertion tracking, and deterministic conflict resolution under NAACCR/SEER/AJCC rules.
How Patient Journey Intelligence Automates Registry Development
Patient Journey Intelligence eliminates the tradeoff between manual abstraction quality and operational scale by combining multimodal AI, oncology-specific agentic workflows, and structured human oversight across four integrated layers:
1. Data Curation and Extraction
Multimodal AI unifies diverse clinical sources: pathology reports, radiology findings, genomic tests, or physician notes, into structured, standardized formats. Healthcare-specific small language models (SLMs) deployed locally filter more than 96% of low relevance documents (the noise) before abstraction begins, ensuring that only clinically relevant documents proceed to downstream reasoning. Every extracted field is linked to its source text span with a confidence score and extraction timestamp.
2. Patient-Level Reasoning
Through agentic workflows and auto-consolidation, the system automatically reconciles partial or conflicting records in real time according to standardized NAACCR/SEER/AJCC rules. Temporal ordering of encounters, assertion revision tracking, and cross-document deduplication are handled automatically, enabling staff to focus on "review by exception" rather than manual data consolidation.
3. Registry Specific AI Agents
Purpose-built AI agents select guideline logic by registry type and translate guidelines rules and flowcharts into executable, deterministic decision graphs. e.g. for staging, histology, biomarker status, and treatment classification. Results are compiled against standard ontologies such as NAACCR, ICD-O-3, and AJCC TNM, ensuring every abstracted value follows the correct coding pathway.
4. UI for Validation and Feedback
A structured validation interface gives registrars, auditors, and clinical coders the workflows they actually need: supporting and contradictory evidence displayed side by side, complete audit trails, team collaboration features, and a learning loop that continuously improves model performance over time through human corrections.
Traditional registry development forces organizations to choose between hiring specialized abstractors for manual chart review or accepting incomplete data. Patient Journey Intelligence eliminates this tradeoff by providing pre-configured registry templates that combine automated case finding, AI-powered clinical data extraction, expert review workflows, and regulatory reporting, all built on standardized OMOP CDM data.
Architecture: Delivering Accuracy, Scale, and Governance
The Patient Journey Intelligence pipeline follows a five-stage architecture designed for regulatory-grade accuracy and data security:

The platform handles the heavy lifting of data extraction and case identification, freeing your clinical experts to focus on what humans do best: validating complex cases, resolving ambiguities, and ensuring quality. Instead of spending hours manually abstracting each chart, your team reviews AI-extracted data that's already coded, structured, and ready for validation.
From Configuration to Regulatory Submission
The Automated Registry Workflow
Configure Target Cohort
Define inclusion/exclusion criteria, required data elements (e.g. your ontology), and quality measures based on registry specifications (NAACCR, ACC-NCDR, custom requirements)
Automated Case Finding
AI algorithms scan clinical data to identify potential cases using diagnosis codes, procedures, pathology findings, and clinical notes, capturing cases that manual processes miss
AI-Powered Data Extraction
John Snow Labs Medical Language Models automatically extract required registry data elements (e.g. staging, treatment, outcomes) from structured and unstructured sources with confidence scores and full provenance tracking
Expert Review & Validation
Clinical experts review AI-extracted data through structured workflows, validate accuracy, and resolve ambiguous cases. Inter-rater reliability tracking ensures quality.
Quality Validation & Reporting
Run quality checks, generate required reports, and submit to regulatory bodies in compliant formats (NAACCR, CDC, state registries)
Automate Case Finding, Data Extraction, and Regulatory Reporting End-to-End
Behind this streamlined workflow are six integrated capabilities that work together to transform registry operations. Think of these as your automated registry team, each handling a specific aspect of the abstraction and reporting process that would otherwise require significant manual effort.
Identify Cases Automatically Across All Data Sources
AI algorithms continuously scan your clinical data, EHR fields, clinical notes, pathology reports, imaging studies, to identify potential registry cases the moment they're documented, ensuring 100% case capture without manual chart review.
Extract Registry Data from Structured and Unstructured Sources
The platform reads clinical documentation like an experienced abstractor, automatically extracting staging, treatment details, outcomes, and quality metrics. Every extraction includes confidence scores and full provenance tracking back to source documents.
Validate Data Through Streamlined Expert Review
Clinical experts review AI-extracted data through intuitive interfaces designed for efficiency. Structured review forms, consensus workflows for disagreements, and inter-rater reliability tracking ensure quality while reducing time spent per case by 80-90%.
Generate Submission-Ready Reports for Regulatory Bodies
The platform generates exports in exactly the format regulatory bodies require, NAACCR for cancer registries, CDC for public health surveillance, state-specific formats for regional compliance. Built-in quality validation catches errors before submission.
Monitor Registry Quality with Real-Time Dashboards
Track case completeness, timeliness of abstraction, data accuracy rates, and compliance with reporting requirements. Spot issues early and demonstrate quality to auditors with comprehensive metrics and audit trails.
Keep Registries Current with Continuous Automated Updates
The platform monitors for new cases and data updates in real-time, incrementally processing changes as they arrive. No more batch updates or falling behind, your registry stays current automatically without manual intervention.
Addressing the Three Fundamental Challenges of Clinical Data for Secondary Use
The Data Accuracy Gap
Up to 40% of critical diagnoses exist only in unstructured clinical notes, they are never coded into structured EHR fields. Treatment rationale, disease progression, and clinical reasoning are documented as free text, invisible to traditional analytics. Patient Journey Intelligence's Medical Language Models extract this hidden context, ensuring registry initiatives work from complete patient pictures.
The Data Engineering Gap
Organizations spend 10+ FTE-years annually rebuilding similar data pipelines for each registry, cohort, or AI model. Patient information is scattered across EHR fields, clinical notes, PDFs, imaging reports, and lab systems with no unified foundation. Patient Journey Intelligence's Build Once, Use Everywhere pipeline eliminates this redundancy, standardizing all data to OMOP CDM v5.4.
The AI Readiness Gap
FDA guidance on Real-World Evidence requires every clinical AI decision to be traceable to its source document: claims data and ICD codes alone will not pass regulatory scrutiny. Patient Journey Intelligence preserves full provenance for every extracted fact: source document, extraction timestamp, ML confidence score, and transformation lineage, meeting FDA reliability and relevance requirements out of the box.
The Impact: Measurable Benefits of AI-Powered Registries
By automating the most time-intensive aspects of registry maintenance, case finding, chart abstraction, and data extraction, Patient Journey Intelligence fundamentally transforms registry operations from a manual, labor-intensive burden into a streamlined, continuously updated asset. Organizations shift their specialized staff from repetitive data entry to high-value activities like quality validation, complex case review, and strategic analysis. The result is not just efficiency gains, but a fundamental improvement in registry completeness, accuracy, and timeliness that directly impacts regulatory compliance, quality measurement, and research capabilities.
80-90% Reduction in Manual Effort
Eliminate repetitive chart abstraction and data entry tasks through AI-powered automation. Staff focus on quality validation and complex cases instead of manual data extraction.
Months to Days
Deploy functional registries in days instead of months of manual configuration and testing. Pre-built templates accelerate time-to-value.
100% Case Capture
Automated scanning across structured and unstructured data ensures no cases are missed, improving registry completeness and reducing penalties for incomplete reporting.
Improved Accuracy
AI-assisted extraction with expert validation ensures high-quality, consistent data capture. Provenance tracking and confidence scores enable quality control.
Always Current
Continuous monitoring keeps registries up-to-date without manual intervention. New cases are automatically identified and processed as clinical data arrives.
Available Registries
Patient Journey Intelligence offers pre-configured registry templates designed for the most common healthcare use cases, each built on the same automated foundation but tailored to specific regulatory requirements and reporting standards. Whether you're maintaining cancer registries for state reporting, building research cohorts for clinical trials, or tracking cardiovascular outcomes for quality measures, these templates accelerate deployment from months to days while ensuring compliance with industry standards like NAACCR, ACC-NCDR, and IRB requirements.
De-identified OMOP
Purpose-built for secondary use research with automated de-identification, OMOP CDM standardization, and IRB-ready datasets for retrospective studies and clinical trial feasibility
Learn more →
Cancer Registry
NAACCR-compliant cancer registry with automated case finding, AJCC staging, treatment tracking, and outcomes monitoring with state/national registry submissions
Learn more →
Cardiovascular Registry
Comprehensive CVD registry for outcomes tracking, quality measures, and research cohorts
Coming soon
Rare Disease Registry
Specialized registry for rare and orphan diseases with longitudinal tracking and natural history studies
Coming soon
Registry Applications Across Healthcare
Patient registries powered by Patient Journey Intelligence support critical use cases across quality measurement, research, public health, and regulatory compliance.
Quality Measurement & Reporting
Healthcare organizations face constant pressure to demonstrate quality performance across multiple reporting frameworks. Patient registries power these quality programs by:
- Hospital quality metrics: Systematically capture standardized data required for CMS and Joint Commission measures
- Specialty quality programs: Support NSQIP for surgical outcomes, STS for cardiac surgery, ACC for cardiovascular care
- Payer quality reporting: Generate HEDIS reports that impact reimbursement and health plan ratings
Research & Clinical Trials
Clinical research depends on identifying the right patients and collecting comprehensive longitudinal data. Patient registries accelerate research by:
- Disease-specific cohorts: Create retrospective study populations that examine treatment patterns and outcomes over time
- Clinical trial feasibility: Quickly identify how many eligible patients exist in your population for trial planning
- Real-world evidence: Generate RWE that complements traditional clinical trials by capturing outcomes in routine clinical practice
Public Health Surveillance
Public health agencies rely on timely, accurate registry data to track disease trends and protect populations. Patient registries fulfill critical public health functions by:
- State and national disease registries: Monitor cancer incidence, trauma outcomes, and chronic disease prevalence
- Reportable conditions tracking: Alert authorities to infectious diseases and potential outbreaks
- Outbreak monitoring: Quickly identify clusters of cases that might indicate emerging public health threats
Regulatory Compliance
Many healthcare providers face mandatory reporting obligations that carry significant penalties for non-compliance. Patient registries streamline regulatory compliance by:
- Mandatory reporting requirements: Automate submissions for conditions like cancer, trauma, and stroke that must be reported to state and federal agencies
- Device and implant registries: Track patient safety and support post-market surveillance as required by the FDA
- Safety surveillance: Identify adverse events and unusual patterns requiring investigation or intervention
Technical Foundation
Built on OMOP CDM v5.4
All registry data is stored in standardized OMOP format, enabling:
- Interoperability: Compatible with research tools and analytics platforms
- Reproducibility: Consistent definitions across institutions
- Flexibility: Easy to extend with custom data elements
- Research-ready: Direct integration with cohort building and analytics
AI-Powered Extraction
Leverages John Snow Labs Medical Language Models trained on millions of clinical documents:
- Named Entity Recognition: Extract conditions, medications, procedures, findings from unstructured text
- Relation Extraction: Identify relationships between clinical concepts (e.g., medication treats condition)
- Assertion Detection: Capture negation, uncertainty, temporal context (e.g., "no evidence of metastasis")
- Document Classification: Route documents to appropriate extraction pipelines based on content type
Custom Registry Development
Beyond pre-built registries, Patient Journey Intelligence supports custom registry development for:
- Institutional quality improvement initiatives
- Disease-specific research cohorts
- Clinical specialty registries
- Novel outcome tracking programs
Custom development process:
- Requirements gathering: Define registry scope, data elements, workflows
- Case finding logic: Configure inclusion/exclusion criteria and algorithms
- Extraction rules: Customize data extraction and validation logic
- Review workflows: Set up expert review and adjudication processes
- Reporting templates: Design required reports and exports
- Pilot & validation: Test with sample cases and validate accuracy
- Production deployment: Scale to full patient population
Need a Custom Registry?
Contact the Patient Journey Intelligence team to discuss custom registry development for your specific needs. Most custom registries can be deployed in 6-8 weeks.
Deploy Your First Registry
Launch Your First Registry
Choose Registry Type
Select from available registries or request custom development
Configure Parameters
Define date ranges, inclusion criteria, and required data elements
Run Initial Case Finding
Execute automated case identification on historical data
Validate & Review
Clinical experts review sample cases to validate accuracy
Enable Continuous Monitoring
Activate automated updates for ongoing case identification