Medical reasoning: turning fragmented EHR data into a trustworthy patient timeline
Healthcare data arrives broken. A single patient on one medication generates six records across four systems. A pneumonia diagnosis appears as "rule out pneumonia" in an ED note, "right lower lobe infiltrate" in a radiology report, and "community-acquired pneumonia, resolved" in a discharge summary - each in a different system, with a different timestamp, and a different level of clinical certainty. An emergency visit generates three separate encounter records as the patient moves from triage to treatment to inpatient admission.
None of this is a data entry failure. It is the normal output of a healthcare system designed for care delivery, not for research. The problem is what happens when you try to use that data analytically: duplicate medication records inflate exposure counts, conflicting diagnoses make cohort definitions unreliable, and temporal impossibilities - a discharge date before admission, a lab result before the order - break any downstream logic that depends on sequence.
Medical Reasoning is the module that fixes this automatically, at ingestion, before any of these inconsistencies reach a researcher, a report, or an AI agent. It applies specialized logic to deduplicate entities, resolve conflicts between sources, reconstruct accurate timelines, and record every decision with full provenance - so you know not just what the data says, but why it was resolved that way.
Why data quality problems are unavoidable - and why they must be fixed before analysis
To understand why medical reasoning is necessary, consider a patient prescribed metformin for type 2 diabetes. Over a single year, this one medication appears in your data as:
| Record | Source | Date |
|---|---|---|
| Metformin 1000mg BID | Pharmacy order | Jan 15 |
| Metformin 1000mg twice daily | EHR medication list | Jan 15 |
| Metformin 1g BID | Discharge summary | Jan 20 |
| Metformin 500mg BID | Progress note (dose reduced) | Feb 10 |
| Metformin 500mg twice daily | Pharmacy order | Feb 10 |
| Metformin 1000mg BID | Data entry error | Feb 15 |
Without reasoning, you have six separate medication records. You cannot determine the actual exposure history, identify when the dose changed, or detect the erroneous Feb 15 entry that contradicts the documented dose reduction five days earlier.
With reasoning, the Jan 15 duplicates merge, the Feb 10 dose change is established as a clinical event, the Feb 15 entry is flagged as a conflict (a 1000mg dose after a documented reduction to 500mg cannot be correct without a new prescriber action), and you end up with an accurate, sourced medication timeline - with provenance linking every decision back to its original records.
This same pattern repeats across diagnoses, lab results, procedures, and visit records. Every clinical entity that lives in multiple forms across your data ecosystem needs this kind of reconciliation. Medical Reasoning applies it automatically and at scale, across every patient and every source system connected to the platform.
Core reasoning capabilities
Medical Reasoning runs automatically during data ingestion, applying five categories of logic to every clinical entity before it is written to the OMOP CDM:
Entity deduplication
Identify and merge duplicate clinical entities across data sources - same medication, same lab, same diagnosis documented in multiple systems - preserving all source provenance while producing a single canonical record.
Conflict resolution
Detect contradictions when multiple sources provide incompatible information for the same clinical fact, and resolve them using a transparent, auditable hierarchy of decision rules.
Temporal reasoning
Establish the correct chronological order of clinical events, detect temporal impossibilities (discharge before admission, medication start after documented stop), and reconstruct accurate patient timelines.
Confidence scoring
Assign reliability scores to every extracted clinical fact based on source type, extraction method, and consistency with corroborating evidence - enabling downstream filtering by confidence threshold.
Provenance tracking
Maintain complete lineage from original source documents to the final standardized OMOP record, recording the source system identifier, extraction timestamp, and resolution method for every decision.
Specialized reasoning profiles
Different clinical entities present different data quality challenges. The platform provides pre-configured reasoning profiles for the three most common problem categories:
Medication reconciliation
Medications are the highest-volume data quality problem in most EHR environments. The same drug appears in pharmacy orders, EHR medication lists, progress notes, and discharge summaries - often with minor but structurally significant differences in how dose and frequency are recorded.
Example: three records, one clinical event
Source 1 (Pharmacy, 08:30): Lisinopril 10mg, ordered 2024-01-15
Source 2 (EHR medication list, 09:00): Lisinopril 10 MG Oral Tablet, recorded 2024-01-15
Source 3 (Discharge summary, Jan 20): Lisinopril 10mg PO daily, documented 2024-01-20
What the reasoning engine does:
- Merges all three into a single medication exposure - they all refer to the Jan 15 start event
- Resolves representation differences: "10mg" vs "10 MG" vs "10mg PO daily" are the same dose
- Establishes source sequence: pharmacy order (08:30) preceded EHR entry (09:00); discharge summary documents the same start date retrospectively
- Produces one record: lisinopril 10mg/day, start Jan 15, with provenance linking all three sources
Diagnosis consolidation
Diagnoses are documented progressively. What starts as "rule out pneumonia" in an ED note may become a confirmed diagnosis the next day and a resolved condition a week later. Without consolidation, these become three separate diagnosis records - with conflicting assertion statuses - for a single clinical episode.
Example: one episode across four documents
Source 1 (ED note, Jan 10): "Rule out pneumonia" → Assertion: Hypothetical
Source 2 (Chest X-ray report, Jan 10): "Right lower lobe infiltrate consistent with pneumonia"
Source 3 (Problem list, Jan 11): "Pneumonia" → Assertion: Present
Source 4 (Discharge summary, Jan 15): "Community-acquired pneumonia, resolved"
What the reasoning engine does:
- Tracks assertion progression: hypothetical (Jan 10) → confirmed by imaging (Jan 10) → added to problem list (Jan 11) → resolved (Jan 15)
- Deduplicates the condition: all four references describe the same pneumonia episode
- Establishes clinically meaningful dates: suspected Jan 10, confirmed Jan 11, resolved Jan 15
- Assigns primary diagnosis status to the hospitalization
Visit consolidation
A patient admitted through the ED generates an ED encounter record, an ADT admission event, and an inpatient billing record - three records for one continuous episode of care. Without consolidation, visit counts are inflated and care continuity is invisible to analytics.
Example: one hospitalization, three source records
Source 1 (ED system): Visit ID 12345, arrived 2024-02-20 14:30, discharged 2024-02-20 18:00
Source 2 (ADT feed): Admission 2024-02-20 17:45, floor 5 West
Source 3 (Billing): Inpatient stay 2024-02-20 to 2024-02-23
What the reasoning engine does:
- Detects the temporal overlap: ED visit (14:30–18:00) overlaps with inpatient admission (17:45)
- Links records: same patient, continuous care, ED visit directly preceded admission
- Merges into a single care episode: ED arrival 14:30 Feb 20 → inpatient discharge Feb 23
- Preserves component types: the unified episode contains an ED visit component and an inpatient stay component, both queryable
How the conflict resolution hierarchy works
When two sources disagree on the same clinical fact, the reasoning engine does not pick arbitrarily. It applies a four-tier decision hierarchy in sequence, stopping at the first tier that produces a clear answer:
Source priority
Trust the authoritative system for the data type: the pharmacy system for medication orders, the lab system for test results, the radiology PACS for imaging findings. When a conflict exists between an authoritative source and a secondary one, the authoritative source wins.
Recency
When sources have equal authority, prefer the most recent information. An updated diagnosis supersedes a prior entry. A recent lab result reflects current patient status better than one from six months ago.
Confidence score
When both sources are equally recent, prefer the higher-confidence extraction. Structured data fields carry higher baseline confidence than NLP-extracted values from free text. Estimated or approximate values ('BP approximately 140/90') are scored lower than precise measurements.
Clinical logic
Apply domain rules that no source priority or timestamp can override: drug dosages must fall within safe physiological ranges, temporal sequences must be logically consistent (discharge cannot precede admission), diagnoses must align with documented clinical evidence.
Example: three blood pressure readings, one resolution
Nursing flowsheet (14:23): 145/92 mmHg - structured data, high confidence
Progress note (14:30): "BP approximately 140/90" - NLP extraction, medium confidence (estimated value)
Discharge summary (next day): "BP 130/85" - NLP extraction, high confidence, but from the following day
Decision: Nursing flowsheet wins on source priority (authoritative for vital signs) and confidence (structured vs. NLP). The progress note is retained as corroborating evidence. The discharge summary BP is linked to the following day's assessment - a different clinical timepoint, not a conflicting reading.
The hierarchy is transparent by design. Every resolved conflict records which tier produced the decision and why, so a researcher auditing a specific value can trace the full reasoning chain.
Merge and deduplication pipeline architecture
The diagram below shows how the merge and deduplication process is executed (step 6 of the Data Ingestion flow). Each source system initially lands data in its own temporary OMOP schema. The pipeline then consolidates those schemas, applies entity-level deduplication and merge rules, resolves foreign key relationships across sources, and upserts the resulting records into the Gold OMOP schema - recording provenance and publishing progress metrics at each stage.
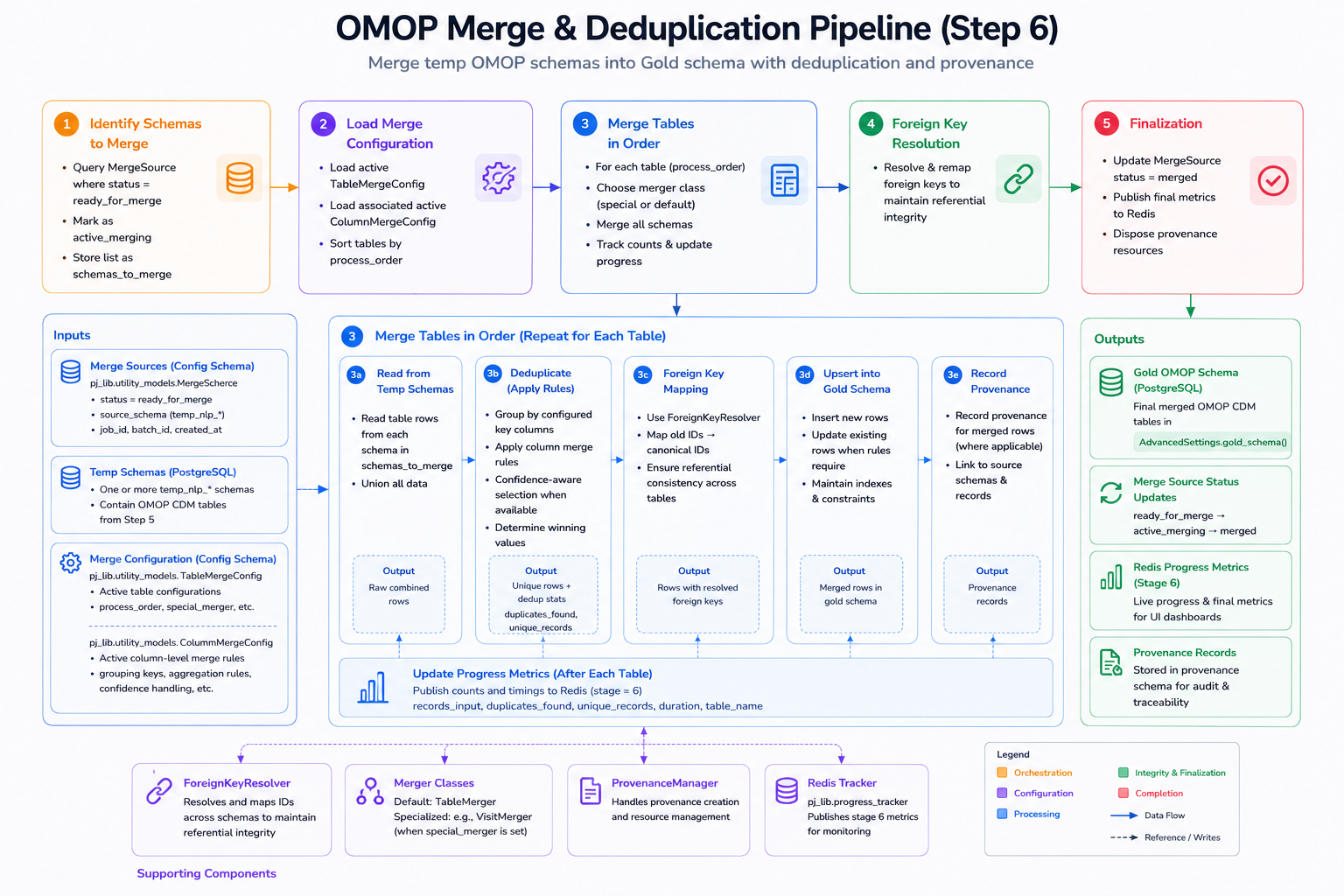
Merge and deduplication pipeline: temporary per-source OMOP schemas are consolidated, entity-level deduplication and merge rules are applied, foreign keys are resolved across sources, and deduplicated records are upserted into the Gold OMOP schema with full provenance.
The Gold schema is the authoritative output of this process. Every record in it has already been extracted by the NLP pipeline, normalized by the Medical Terminology Server, conflict-resolved by the reasoning engine, and deduplicated here - producing a single, consistent, auditable view of each patient's clinical history.
Provenance and auditability
Every reasoning decision - every merge, every conflict resolution, every temporal reordering - leaves a permanent audit record. The OMOP CDM stores:
Source system identifiers
Original record IDs from every contributing system. A merged medication record retains the pharmacy order ID, the EHR record ID, and the discharge note reference - enabling direct tracing back to source documents for validation or dispute.
Extraction timestamps
When each fact was extracted or recorded, distinguishing data capture time from clinical event time. Critical for understanding whether a 'current' value reflects today's measurement or a note written six weeks ago.
Confidence scores
Reliability assessment for each extracted fact, enabling downstream analyses to filter by confidence threshold. A pharmacovigilance study can restrict to high-confidence medication records; an exploratory analysis can include the full distribution.
Resolution method applied
The specific tier and rule that determined the retained value: source priority, recency, confidence, or clinical logic. Transparent decision-making that satisfies audit requirements for HIPAA, 21 CFR Part 11, and IRB protocol documentation.
This audit trail is not optional overhead - it is what makes the platform suitable for regulated research. When an IRB reviewer asks how a cohort was constructed, or a regulator asks why a specific lab value appears in a submission, every answer is in the provenance record.
What clean data makes possible
The practical impact of medical reasoning compounds across every downstream use of the data:
For research cohorts: Deduplicated diagnoses and accurate medication timelines mean your inclusion and exclusion criteria are evaluated against the clinical reality, not an artifact of how many times something was documented across systems.
For AI agents: Agents that query the OMOP CDM to answer clinical questions need clean, non-contradictory data. A patient with simultaneous "pneumonia" and "no pneumonia" records produces unreliable agent outputs. Resolved records produce reliable ones.
For regulatory submissions: Full provenance with source identifiers, timestamps, and resolution rationale satisfies 21 CFR Part 11 electronic record requirements and supports IRB documentation without additional data preparation.
For longitudinal analytics: Accurate event sequences - when a diagnosis was first suspected, confirmed, and resolved; when a medication was started, dose-changed, and stopped - are the foundation of any time-series analysis, survival study, or treatment trajectory model.
It applies a four-tier decision hierarchy in sequence: source priority (pharmacy system beats a clinical note for medication data), recency (newer information supersedes older when authority is equal), confidence score (structured data beats NLP-extracted estimates), and clinical logic (physiological and temporal rules that no source can override). Every decision records which tier resolved it and why.
No. Source records are never modified or deleted. The reasoning engine produces a resolved representation in the Gold OMOP schema while preserving all original source records with their identifiers intact. The provenance link from the resolved record back to every contributing source record is permanent.
Assertion-status tracking follows the progression of each diagnosis across documents and timestamps. A condition documented as hypothetical ("rule out") on day one, confirmed on day two after imaging, and resolved on day seven produces a single condition record with three temporal milestones: suspected date, confirmed date, and resolution date - all sourced and auditable.
Irresolvable conflicts are flagged rather than silently resolved. Both values are retained in the OMOP CDM with a conflict indicator, a confidence score for each, and the reasoning engine's assessment of why the conflict could not be resolved. Downstream analysts can filter these records out, review them manually, or include both values with appropriate uncertainty handling.
Yes. The source priority tier is configurable per organization. If your institution's EHR medication module is more reliable than the pharmacy feed for a specific drug class, you can set that preference in the source priority configuration. The other tiers (recency, confidence, clinical logic) are fixed but their thresholds can be adjusted.
Medical Reasoning operates on the identified data before de-identification runs. The Gold OMOP schema produced by the reasoning engine is the source for both the identified and the continuously synchronized de-identified OMOP dataset. De-identification applies to the already-reasoned, already-clean records - so the de-identified dataset inherits all the data quality improvements without any additional reconciliation step.