Medical terminology: normalizing every clinical concept to standard vocabularies
Every healthcare organization speaks its own language. A cardiologist documents "MI". A hospitalist writes "AMI". The discharge summary says "myocardial infarction", and the billing team codes it as "heart attack". Four phrases. One condition. And if your analytics platform treats them as four separate entities, every cohort you build is wrong before you even start querying.
The same fragmentation runs through medications, lab tests, procedures, and diagnoses. A pharmacy system uses "ACEI-10" while the EHR lists "lisinopril 10mg tabs" for the same drug. Lab results arrive labeled "HGB-A1C", "A1c", and "Hemoglobin A1c" - three labels for a single LOINC code. Without a common language, these variations accumulate into a dataset that is analytically unreliable and impossible to share with external partners.
The Medical Terminology Server solves this automatically. It resolves every clinical concept - whether extracted from free text by the NLP pipeline or read from a structured field - to a standard vocabulary code. The result is a single, consistent representation across every source system in your organization, stored in the OMOP CDM and ready for querying, research, and regulatory reporting.
Medical Terminology Server in action: resolving a chunk of clinical text to all available coding systems simultaneously, and performing entity resolution in context - identifying the correct concept even when the same term carries different meanings depending on clinical setting.
Why a single vocabulary layer changes everything
Consider what happens when you run a cohort query for "patients with type 2 diabetes" against an unnormalized dataset. You would need to explicitly search for every variant your clinicians have ever used:
- Diabetes mellitus
- Type 2 diabetes
- T2DM
- NIDDM
- DM2
- Adult-onset diabetes
- Non-insulin dependent diabetes mellitus
- ...and dozens more variants across clinical notes, problem lists, encounter diagnoses, and billing records
Miss even a handful, and your cohort is wrong. Worse, you cannot know how wrong - because you cannot enumerate what you missed.
With terminology normalization, all of these variants resolve automatically to SNOMED CT concept 44054006 (Diabetes mellitus type 2). One query. Complete capture. The same principle applies to every drug, lab test, procedure, and finding in your dataset - and it happens in the background, at ingestion, before any researcher ever runs a query.
This is not just an analytics convenience. It is the foundation of interoperability: the reason your data can participate in multi-site research networks, satisfy regulatory reporting requirements, and feed AI agents that reason across patient populations rather than institution-specific code lists.
Supported standard vocabularies
The terminology server normalizes clinical concepts to five core terminologies, each the authoritative standard for its clinical domain:
SNOMED CT
Comprehensive clinical terminology for conditions, findings, procedures, and anatomical structures. The broadest clinical vocabulary and the foundation of OMOP concept mapping.
Example: "Congestive heart failure" → SNOMED 42343007
RxNorm
Standardized drug names, ingredients, strengths, and dose forms maintained by the National Library of Medicine. The standard for medication interoperability.
Example: "Lisinopril 10mg tablets" → RxNorm 314076
LOINC
Universal codes for laboratory tests, clinical measurements, and observations. Required for most lab result interoperability and quality reporting.
Example: "Hemoglobin A1c" → LOINC 4548-4
ICD-10-CM
Diagnosis codes for regulatory reporting, billing interoperability, and population health. The required standard for most US payer and regulatory submissions.
Example: "Type 2 diabetes with neuropathy" → ICD-10 E11.40
CPT
Procedure codes maintained by the AMA for billing, quality measurement, and outcomes tracking. Essential for surgical and procedural research.
Example: "Coronary artery bypass graft" → CPT 33533
40+ additional vocabularies
Extended support for specialized terminologies: NDC, HCPCS, MedDRA, HPO, UMLS, NCI Thesaurus, MeSH, ICD-O-3, ICD-10-PCS, ATC, CVX, and more - covering oncology, genomics, rare disease, immunization, and global reporting.
How concept resolution works
Step 4: concept resolution and enrichment
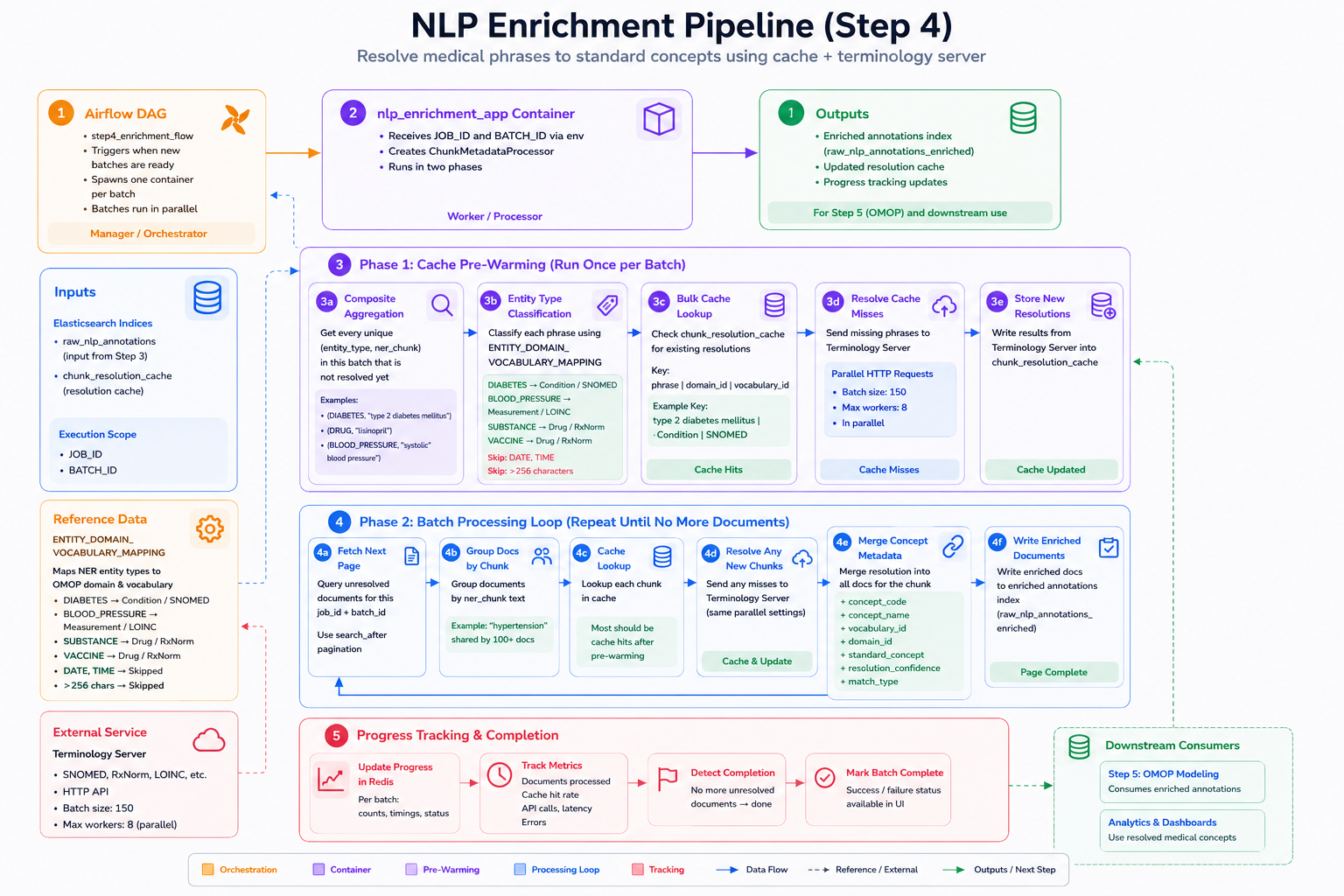
Step 4 resolves extracted medical phrases to standard vocabularies using cache pre-warming, entity-type classification, terminology server lookups, and batched processing. Enriched annotations are written back for OMOP modeling and downstream analytics.
Every clinical concept - whether the NLP pipeline extracted it from a clinical note or a structured field delivered it from an EHR - passes through the same four-step resolution sequence:
Receive the clinical concept
NLP extracts 'metformin 1000mg BID' from a clinical note, or a structured field carries the local institutional code 'MET-1000' from the pharmacy system.
Search the terminology server
The server queries across all vocabularies simultaneously, matching by name, synonym, abbreviation, or code. Entity-type classification narrows the search: a drug phrase queries RxNorm first; a diagnosis phrase queries SNOMED CT and ICD-10.
Resolve to standard code
The best match is selected using semantic similarity and clinical context. Result: RxNorm 861007 - Metformin 1000 MG Oral Tablet.
Store in OMOP CDM
The resolved concept_id is persisted in the OMOP CDM alongside provenance metadata: source value, vocabulary version, and resolution confidence. Every downstream query operates on standard codes.
The entire process runs in the background during ingestion. By the time a researcher opens the platform, every concept is already normalized.
Key capabilities
Concept search
You can search the terminology server directly by name, code, synonym, or clinical shorthand. The server understands abbreviations and spelling variations without requiring exact matches.
- Search "hypertension" → Returns SNOMED concepts for essential hypertension, secondary hypertension, pulmonary hypertension, and related conditions, ranked by clinical frequency
- Search "A1c" → Returns all LOINC codes for hemoglobin A1c tests across whole blood, serum, and multiple measurement methodologies
- Search "ace inhibitor" → Returns the RxNorm drug class and every individual ACE inhibitor product, enabling class-level queries without listing each drug
Results are ranked by relevance and semantic similarity, so the most clinically appropriate match surfaces first.
Concept mapping
Your institution's internal codes don't disappear - they're mapped to standard concepts so both representations coexist. Queries using the standard concept automatically capture data coded with local institutional codes, with no separate translation layer required at query time.
Local pharmacy codes:
"ACEI-10mg"→ RxNorm 314076 (Lisinopril 10 MG Oral Tablet)"STATIN-HIGH"→ RxNorm 859424 (Atorvastatin 80 MG Oral Tablet)
Local diagnosis codes:
"HTN-benign"→ SNOMED 59621000 (Essential hypertension)"CHF-systolic"→ SNOMED 441530006 (Chronic systolic heart failure)
Local lab codes:
"HGB-A1C"→ LOINC 4548-4 (Hemoglobin A1c/Hemoglobin.total in Blood)"TROP-I"→ LOINC 10839-9 (Troponin I.cardiac [Mass/volume] in Serum or Plasma)
Concept relationships
Clinical concepts exist in hierarchies and networks. Knowing that metformin is a biguanide, which is an antidiabetic agent, means a query for "patients on antidiabetic agents" should capture metformin automatically - without the researcher needing to list every drug. The terminology server encodes these relationships and makes them available to cohort queries and AI agents.
Hierarchical (IS-A):
- Metformin IS-A Biguanide IS-A Antidiabetic agent
- Query for "antidiabetic agents" automatically includes all metformin products
Synonym (Maps-To):
- SNOMED 44054006 (Diabetes mellitus type 2) Maps to ICD-10 E11.9 (Type 2 diabetes without complications)
- Enables cross-vocabulary queries and regulatory reporting from a single source fact
This relational structure powers advanced queries like "patients on any ACE inhibitor or ARB" without manually listing every drug product - and it enables the Medical Reasoning module to detect drug class interactions, contraindications, and treatment gaps automatically.
Vocabulary versions
Vocabulary standards update continuously. ICD-10-CM codes change every October. LOINC releases biannually. RxNorm updates monthly. The terminology server tracks version metadata for every resolved concept, so your historical analyses remain reproducible even after a vocabulary update.
- SNOMED CT: US Edition, updated annually
- RxNorm: Monthly updates from the National Library of Medicine
- LOINC: Biannual updates (January and July releases)
- ICD-10-CM: Annual updates (effective October 1)
- CPT: Annual updates from the AMA
When a vocabulary update retires or maps a concept to a new code, the server maintains backward compatibility for existing data while making the new code available for forward-looking queries.
How the terminology server fits into the broader pipeline
The terminology server is not a standalone tool - it runs transparently inside every data transformation in the platform. You do not explicitly call it. It is embedded in three places where clinical concepts are created or transformed:
Information Extraction
Every entity the NLP pipeline extracts from clinical text - diagnoses, medications, lab results, procedures - is immediately resolved to its standard vocabulary code before being written to the OMOP CDM.
Medical Reasoning
The inference engine uses concept relationships from the terminology server to identify drug classes, disease hierarchies, and related conditions when deduplicating entities and resolving conflicts across sources.
OMOP CDM transformation
All clinical facts in the OMOP CDM reference standard concept_ids. The terminology server is the mechanism that makes this possible for both structured fields and NLP-extracted entities.
The practical effect: every cohort query, research export, and AI agent prompt operates on standard vocabulary codes, regardless of how the original data was documented.
What terminology normalization makes possible
The downstream benefits are concrete and measurable:
- Complete cohorts: "Patients with type 2 diabetes" captures every patient, regardless of whether their clinician wrote T2DM, NIDDM, or the full SNOMED term - rather than only those whose documentation matches your search string exactly.
- Consistent analytics across teams: Two researchers running the same query at different times get the same cohort, because they are both querying the same concept_id rather than a curated list of strings that diverges as documentation practices change.
- Multi-site interoperability: Your OMOP dataset speaks the same language as every other OMOP network site. Federated queries, cross-institutional studies, and PCORnet participation become operationally straightforward.
- Regulatory readiness: Data is already mapped to ICD-10-CM, CPT, and other required code sets. Regulatory submissions do not require a separate ETL step.
- AI agent grounding: Agents querying the platform reason over standard concept_ids rather than free-text strings, which eliminates the ambiguity that causes language models to hallucinate or miss relevant patients.
They are preserved. The OMOP CDM stores both the original source value (your local code) and the resolved standard concept_id. Queries using the standard concept automatically capture data coded with local codes, and you can still filter or audit by source value when needed.
Entity-type classification runs before the vocabulary lookup. The NLP pipeline assigns each extracted entity to a category (drug, diagnosis, lab test, procedure, anatomy) based on the surrounding sentence context. The terminology server then restricts its search to the appropriate vocabulary for that entity type, which eliminates most cross-domain ambiguity. Terms that remain ambiguous are flagged with multiple candidate concepts and a confidence score.
Yes. For concepts that have no standard equivalent - institution-specific composite codes, local care protocols, internal risk categories - you can define custom mappings. These are stored in the OMOP CDM using the non-standard concept mechanism and remain queryable alongside standard concepts.
Every resolved concept_id is stored with its vocabulary version at resolution time. When a vocabulary updates and a concept is remapped, historical records retain their original concept_id. You can query by concept at any historical version, or use the mapping tables to translate historical records to current codes for prospective consistency.
The server supports 40+ vocabularies in total, including NDC (National Drug Code), HCPCS, MedDRA, HPO (Human Phenotype Ontology), UMLS, NCI Thesaurus, MeSH, ICD-O-3 (oncology morphology), ICD-10-PCS (inpatient procedures), ATC (drug classification), and CVX (vaccines). The full list follows the OMOP vocabulary catalog maintained by OHDSI.
No. The server uses cache pre-warming for frequently occurring concepts and batched processing for high-throughput workloads. In practice, terminology resolution adds negligible latency to the overall ingestion pipeline, which is already bounded by source system query and data transfer times.