
























































What is regulatory-grade de-identification in healthcare?
Regulatory-grade de-identification refers to the process of systematically transforming or removing Protected Health Information (PHI) to comply with laws like HIPAA and GDPR. It extends beyond simple redaction, supporting longitudinal data integrity, multimodal data formats, and traceability. This enables the use of rich real-world medical data in research, analytics, and AI development without compromising patient privacy.
Why is longitudinal authentication critical in healthcare data?
Longitudinal authentication ensures that patient data remains linkable across different encounters, timeframes, and document formats. Whether linking multiple clinical notes or matching radiology reports to claims data, referential consistency is crucial. For instance, a patient’s name obfuscated in one record as “Anne Boleyn” must remain “Anne” in all future instances. This allows researchers to track conditions, treatments, and outcomes accurately.
How does consistent obfuscation protect privacy while preserving utility?
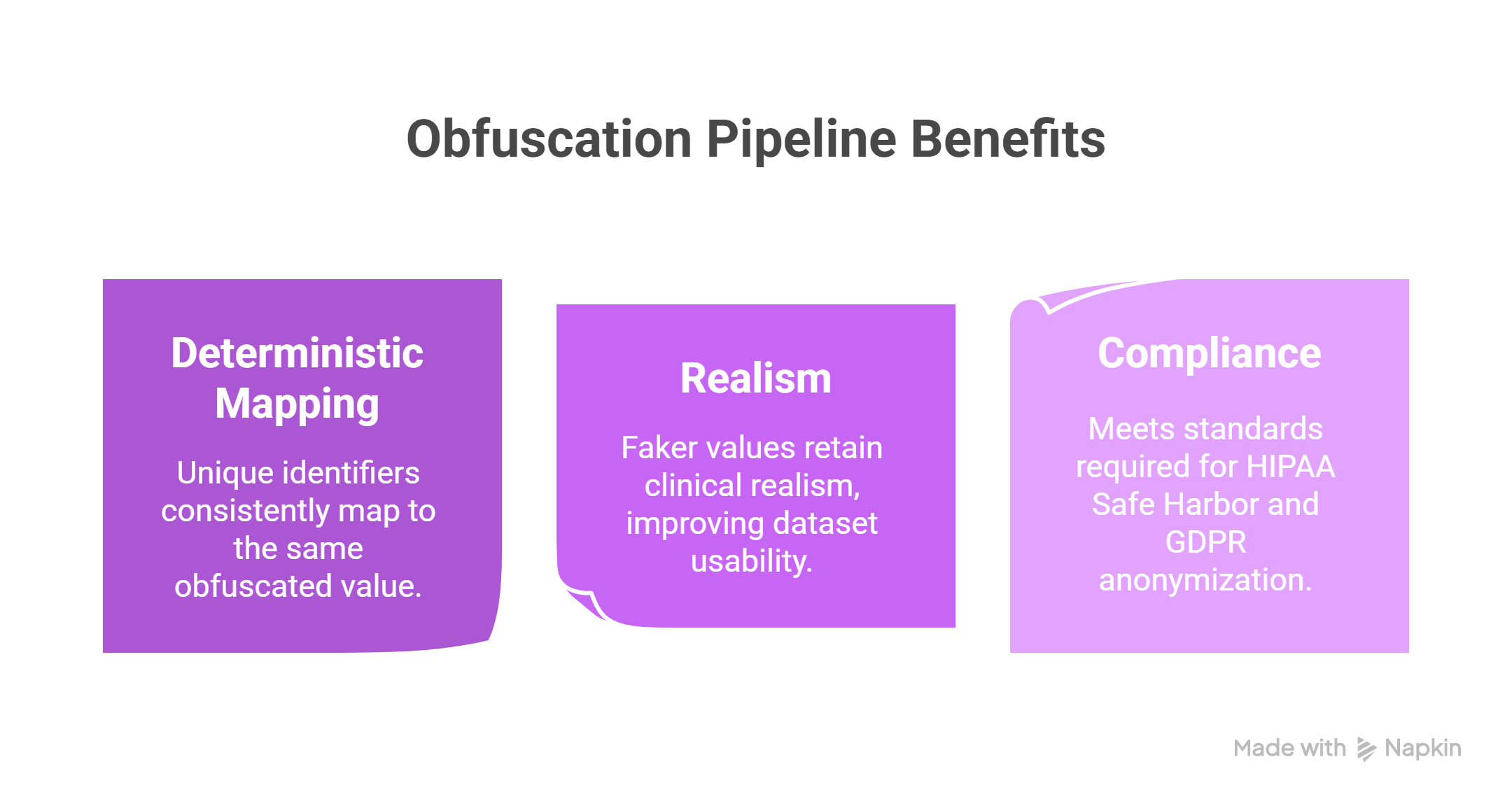
John Snow Labs’ obfuscation pipeline safeguards patient privacy by replacing Protected Health Information (PHI) with synthetic values that are both realistic and context-aware. This process maintains key contextual elements such as gender, temporal accuracy, and semantic relevance, ensuring that obfuscated data remains clinically usable. Each unique identifier, such as a patient name or date, is consistently mapped to the same fictitious value across all records to support longitudinal consistency. The generated faker values resemble authentic medical data, preserving usability for research and analysis. This approach complies with regulatory standards, meeting the requirements of HIPAA Safe Harbor and GDPR anonymization.
What is deterministic tokenization and why does it matter?
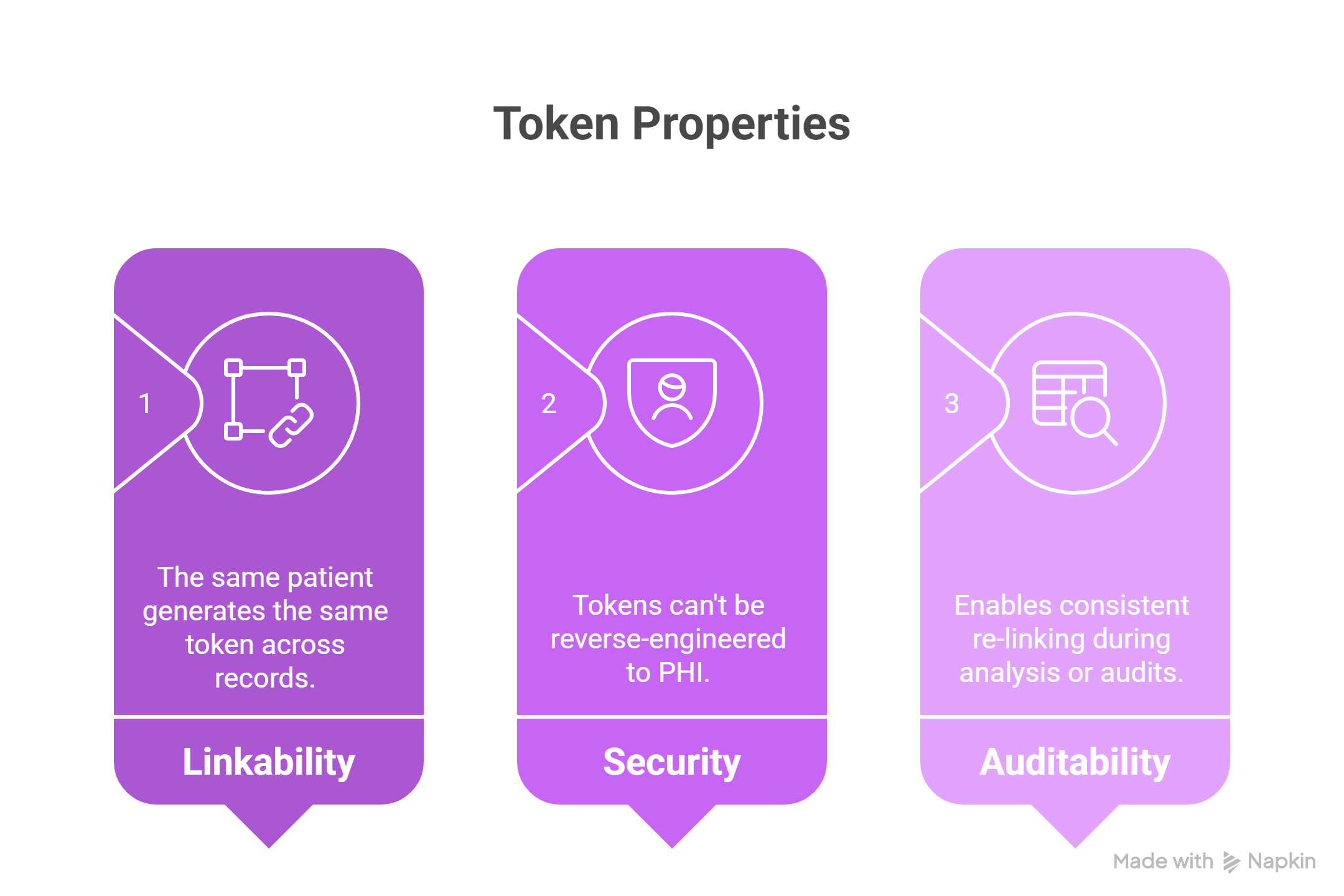
Deterministic tokenization converts identifiers such as medical record numbers or composite attributes into irreversible cryptographic tokens. This process ensures that data from the same patient consistently produces the same token across all records, allowing reliable linkage over time. Because these tokens cannot be reverse-engineered, they offer strong protection against re-identification. At the same time, they support auditability by enabling consistent re-linking for analysis or compliance reviews without revealing any underlying PHI.
How does multimodal linking work across formats like text and images?
Medical data exists in diverse formats:
- Unstructured text (notes)
- Structured data (tables, CSVs)
- Scanned images (DICOM)
- PDFs (selectable and scanned)
John Snow Labs enables seamless integration by applying the same de-identification logic across all modalities. For example:
- A birth date in a clinical note and a DICOM image is obfuscated identically.
- Hospital names in PDFs and claims data receive the same fake substitute.
This allows longitudinal studies and AI training across heterogeneous data while ensuring complete privacy.
How does John Snow Labs outperform other de-identification tools?
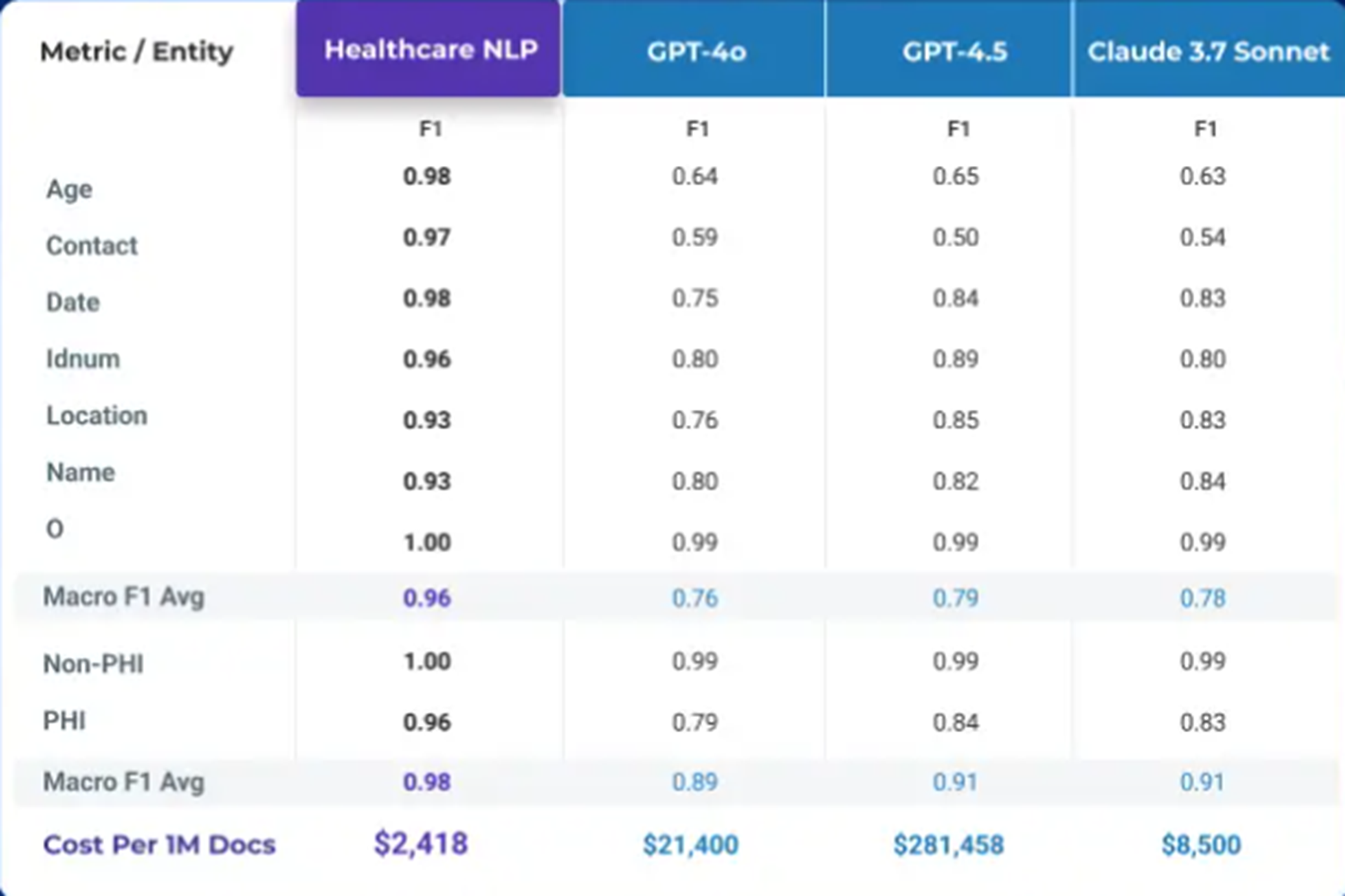
The John Snow Labs Healthcare NLP pipeline leverages Spark NLP to achieve state-of-the-art PHI detection and obfuscation. In recent peer-reviewed benchmarks, it outperformed several alternatives at a fraction of the cost:
- AWS Comprehend Medical
- Azure Health Data Services
- OpenAI GPT-4o and GPT-4.5
- Claude Sonnet 3.7
For instance, John Snow Labs Healthcare NLP achieved a F1 average of 0.98 for deidentification of PHI being superior to GPT-4.5 with a F1 average of 0.91. Most importantly the cost of deidentifying 1 million documents was estimated on $2,418 for the John Snow Labs solution while it reached $281,458 for the OpenAI LLM. These results demonstrate regulatory-grade accuracy exceeding human expert performance, making it the most robust choice for privacy-compliant research.
How can teams customize or extend the de-identification pipeline?
Organizations can take advantage of pre-trained Named Entity Linking (NEL) models that are ready to deploy or choose to train custom models tailored to their proprietary datasets. They can also integrate audit trails and traceability logs to enhance transparency and regulatory alignment. Additionally, the de-identification pipeline can be scaled efficiently across cloud-based or on-premise infrastructure. This flexibility allows the solution to adapt to diverse compliance frameworks while preserving high performance and reliability.
How does this support AI innovation in healthcare?
Accurate, longitudinally-authenticated, and multimodally-linked datasets fuel better model training and real-world evidence generation. By maintaining referential integrity without risking re-identification, John Snow Labs helps unlock the potential of:
- Clinical outcome prediction
- AI-assisted diagnostics
- Personalized treatment planning
Who led this webinar and what expertise was shared?
Youssef Mellah, Ph.D., Senior Data Scientist and ML Engineer at John Snow Labs, led the session. With over 8 years of experience in AI, NLP, and LLMs, Dr. Mellah specializes in deploying privacy-preserving machine learning solutions for life sciences and healthcare. He shared practical workflows, live demos, and performance metrics illustrating how organizations can meet compliance while advancing data science.
Watch the webinar recording here.
FAQs
What makes obfuscation “consistent” in John Snow Labs’ pipeline?
Each PHI element deterministically maps to a unique synthetic counterpart, ensuring repeatability across documents and formats.
Is the tokenization reversible for internal linking?
No. Tokenization uses one-way hashes, but the system enables consistent token assignment to the same input.
Can it handle scanned PDFs and DICOM images?
Yes. The pipeline supports OCR-based processing for scanned formats and metadata parsing in DICOM.
Is this solution compliant with HIPAA and GDPR?
Yes. It meets and exceeds Safe Harbor and Expert Determination standards under HIPAA, and anonymization standards under GDPR.
How does this help longitudinal patient tracking?
By ensuring consistent obfuscation and tokenization, patient journeys remain linkable over time without exposing identity.
Additional Questions
Can this be deployed on-premise for secure environments?
Yes. John Snow Labs supports on-premise, private cloud, and hybrid deployments for maximum data security and compliance.
How does this compare to human annotators?
In benchmarking studies, the solution exceeded human accuracy in PHI detection while maintaining higher throughput and consistency.
For more insights, explore John Snow Labs Healthcare NLP or contact us for a tailored demo.



