
























































Generative AI in Healthcare: 2024 Surveyby
The 2024 Generative AI in Healthcare Survey was conducted online for a period of 33 days, spanning from February 12 to March 15, 2024. The survey includes responses from a total of 304 participants, among which 196 individuals are employed by organizations actively engaged in evaluating, utilizing, or deploying Generative AI (GenAI) technologies. The respondents were recruited through various channels, including online advertising campaigns, social media platforms, the Gradient Flow Newsletter, and collaborations with industry partners.
Survey Demographics and Segments
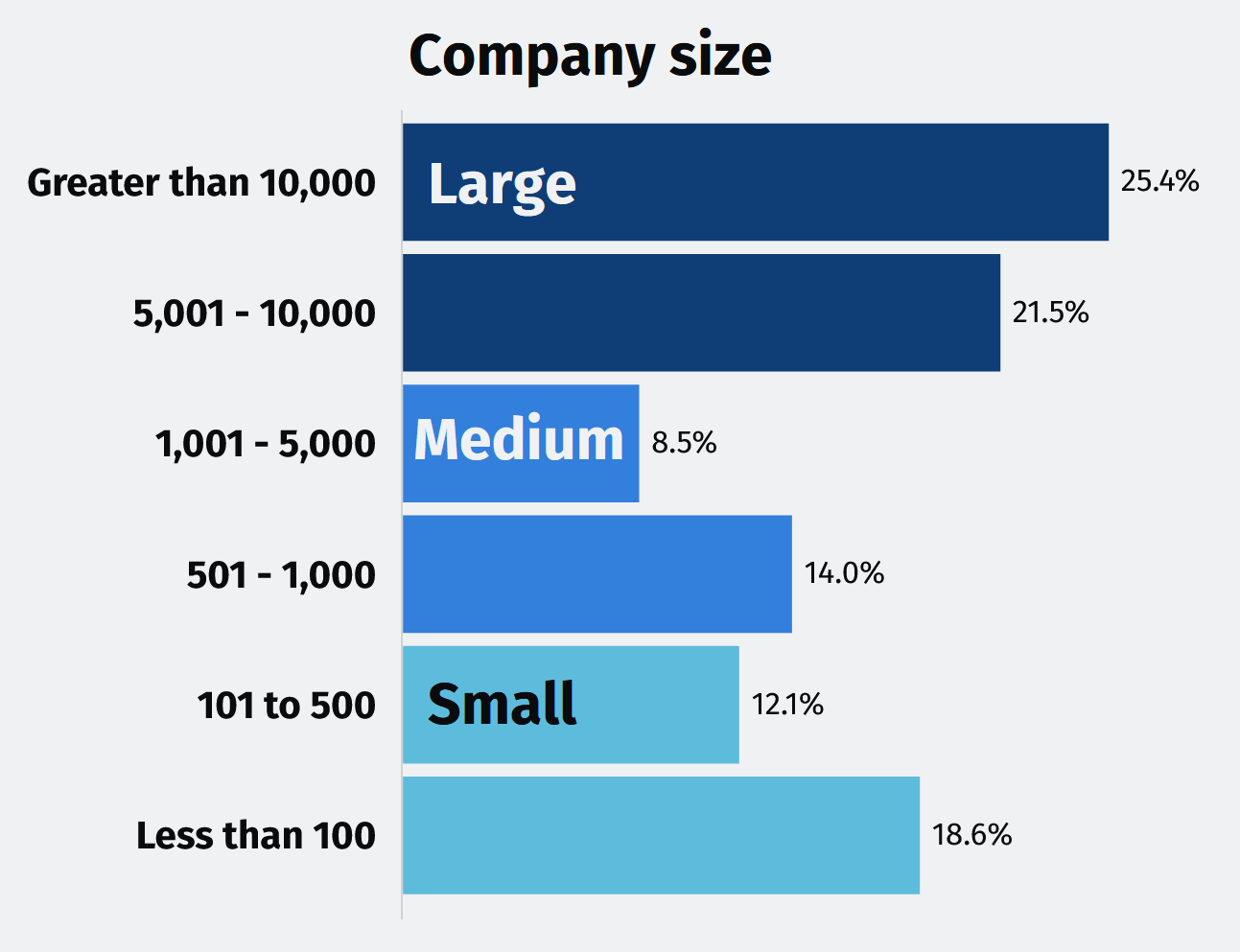
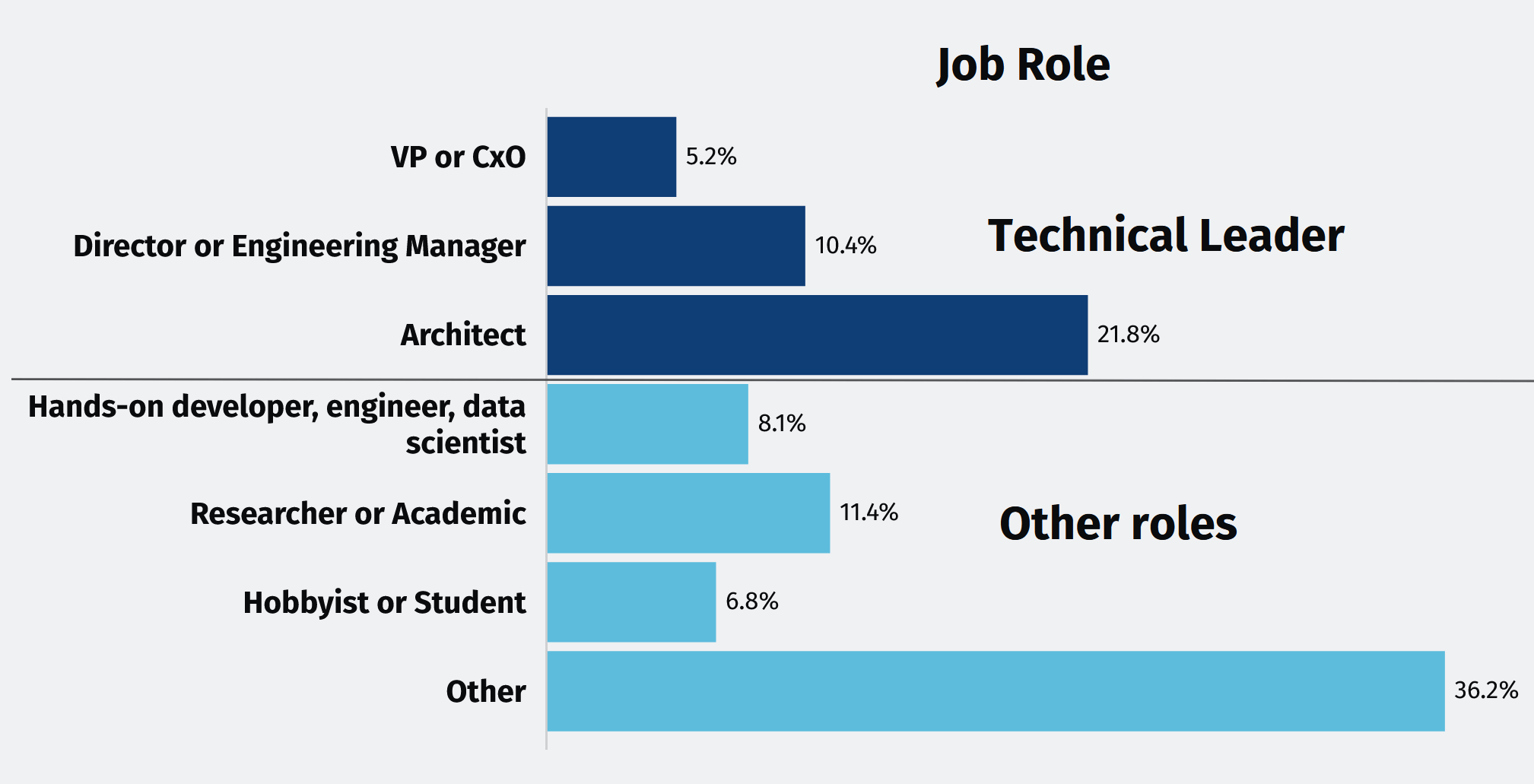
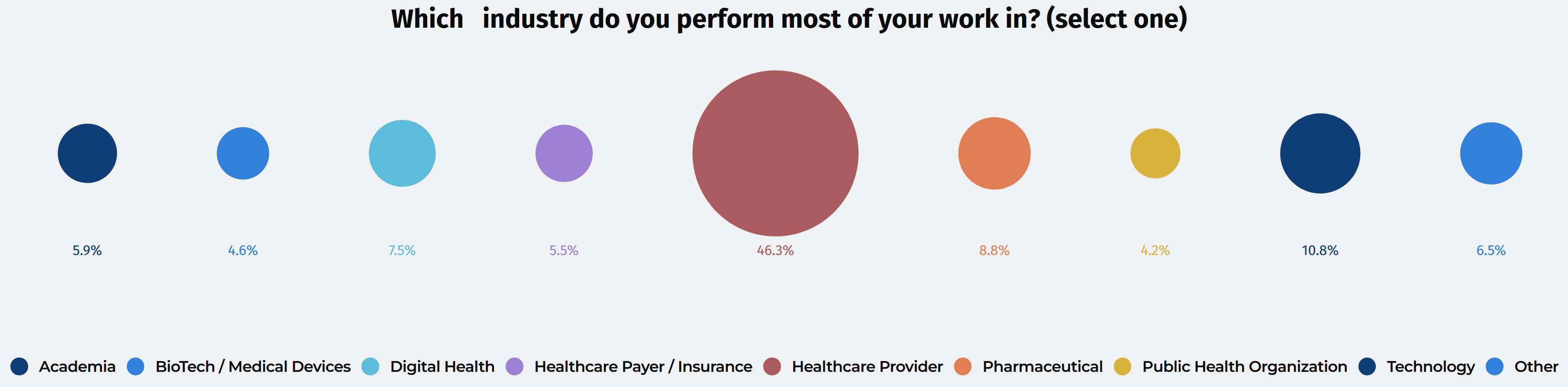
The survey results were analyzed based on the respondents’ roles and company sizes. A significant portion of the respondents—37%—hold leadership positions (Technical Leaders), and their responses will be emphasized throughout this report. The respondents are also categorized according to the size of their organizations:
- Large companies: Nearly half of the respondents (47%) work for organizations with more than 5,000 employees.
- Medium-sized companies: Almost a quarter of the respondents (23%) are employed by organizations with between 501 and 5,000 employees.
- Small companies: The remaining 30% of respondents work for organizations with 500 or fewer employees. Additionally, a substantial proportion of the respondents (46%) are employed by healthcare providers.
Additionally, a substantial proportion of the respondents (46%) are employed by healthcare providers.
Summary
- Adoption variances across roles and sizes: Adoption of GenAI varies among different roles and company sizes, with Technical Leaders showing higher adoption rates compared to other roles, and large companies more likely to be evaluating use cases.
- Year-over-year budget increase: There’s a significant increase in GenAI budgets across the board, with close to one-fifth of all Technical Leaders witnessing a more than 300% budget growth, reflecting strong advocacy and investment. Compared to 2023, 34% of all respondents report a 10-50% increase, and 22% report a 50-100% increase. Technical Leaders and medium-sized companies are experiencing the most significant budget increases.
- Preference for healthcare-specific language models: There’s a clear preference for custom-built, task-specific language models. These targeted models address specific needs within the healthcare domain, unlike general-purpose LLMs. Survey results show this preference, with 36% of All Respondents utilizing healthcare-specific small models. Open source LLMs (24%) and open source small models (21%) follow behind. Interestingly, Technical Leaders are more likely to leverage all language model types, demonstrating a broader exploration of this technology.
- Broad applications of LLMs: The most common use cases for LLMs in healthcare are answering patient questions (21%), medical chatbots (20%), and information extraction/data abstraction (19%). Technical Leaders prioritize information extraction/data abstraction and biomedical research.
- Expected high impact areas: Respondents believe LLMs will have the most positive impact on transcribing doctor-patient conversations, medical chatbots, and answering patient questions over the next 2-3 years. Smaller companies have higher expectations for LLMs compared to larger companies.
- Top evaluation criteria: In addition to healthcare-specific language models, accuracy, security, and privacy risks are the most important criteria when evaluating LLMs. Cost is considered the least important factor.
- Major adoption roadblocks: Lack of accuracy and potential for major legal or reputational risks are the most significant limitations or roadblocks to the adoption of current GenAI technology.
- Enhancement strategies emphasize human oversight: “Human in the loop” is the most common step taken to test and improve LLM models (55%), followed by supervised fine-tuning (32%) and interpretability tools and techniques (25%).
- Testing focuses on fairness, explainability, and privacy: Fairness, explainability, and private data leakage are the most commonly tested requirements for LLM solutions.
- Reflecting specific needs and resources: Testing priorities for LLM solutions vary based on company size, with large companies focusing on fairness and private data leakage, small companies on bias and freshness, and medium-sized companies on explainability and hallucinations/disinformation. Technical Leaders’ focus on private data leakage and hallucinations/disinformation reflects a deeper understanding of the technical risks associated with LLMs.
Stage of Adoption
The adoption of GenAI varies among different groups and company sizes. When considering “All Respondents,” 35% are not actively considering GenAI as a business solution, while 21% are evaluating use cases, and 19% are experimenting and developing AI models but have not yet put them into production. Only 14% are in the early stages of adoption, with a first solution running in production, and 11% are in the mid-stage, with multiple solutions now running in production.
Technical Leaders show a higher level of adoption: among Technical Leaders, 27% are in the early stages of adoption, and 17% are in the mid-stage. Only 17% of Technical Leaders are not actively considering GenAI, compared to 41% of those in “Other Roles.”
When comparing company sizes, large companies have the highest percentage (26%) evaluating GenAI use cases, while medium-sized companies have the highest percentage (24%) experimenting and developing AI models. Small companies have the highest percentage (39%) not actively considering GenAI as a business solution.
The results suggest that the adoption of GenAI is influenced by both the role of the individual within the company and the size of the company itself. Technical Leaders are more likely to be actively involved in the adoption process, possibly due to their expertise and understanding of the technology’s potential. Large companies, with greater resources and potentially more diverse use cases, are more likely to be evaluating GenAI. Medium-sized companies, which may have more flexibility and agility compared to large companies, are more likely to be experimenting and developing AI models. Small companies, possibly due to limited resources or a lack of immediate need, have the highest percentage not actively considering GenAI as a business solution.
These findings highlight the importance of considering the unique needs and capabilities of different groups and company sizes when promoting the adoption of GenAI. Tailored strategies and support may be necessary to encourage adoption among those in non-technical roles and smaller companies, while larger companies and those with technical expertise may require guidance in moving from evaluation to implementation stages.
To align with the survey’s focus on Generative AI usage, the remainder of the analysis will focus on the responses from the 196 participants whose organizations are actively evaluating, utilizing, or deploying these technologies.
Budget Trends for Generative AI Projects: 2024 vs 2023
The survey reveals a significant increase in GenAI budgets across organizations. Compared to 2023, a majority of respondents report a budget hike. Notably, 34% of All Respondents saw a 10-50% increase, followed by 22% with a 50-100% jump.
Technical Leaders are leading the charge, with 18% experiencing a staggering increase of over 300% and another 16% witnessing a 100-300% rise. This suggests a strong awareness among technical leadership of GenAI’s capabilities and potential, driving them to advocate for significant investment.
When comparing the results based on company size, medium-sized companies have the highest percentage of respondents (36%) reporting an increase of 50-100%. Large companies have a higher percentage of respondents (12%) reporting an increase of more than 300%, compared to medium-sized (7%) and small companies (6%). Small companies have the highest percentage of respondents (39%) reporting an increase of 10-50%. The increased budget allocation for GenAI projects across various company sizes and roles suggests a growing recognition of the potential benefits and applications of this technology. The higher percentage of Technical Leaders reporting significant budget increases may indicate that they are more aware of the capabilities and potential of GenAI and are advocating for increased investment in this area. As organizations continue to explore and implement GenAI solutions, it is likely that budget allocations will continue to grow to support these initiatives.
Overview of Current Language Model Usage
Healthcare favors focused models: survey respondents primarily leverage healthcare-specific, “small” task-oriented language models (36%). Open source LLMs (24%) and open source “small” models (21%) follow closely behind. Proprietary LLMs accessed through cloud services (SaaS APIs) and custom models see lower adoption (18% and 11%, respectively). Single-tenant or on-premise proprietary LLMs have the least adoption (7%).
Technical Leaders champion all models: Technical Leaders are more likely to use all language model types compared to other roles. Nearly half (49%) utilize both healthcare-specific “small” models and open source LLMs. They also show significantly higher use of open source “small” models (40%) and cloud-based proprietary LLMs (42%) compared to the overall average. When considering company size, large and medium-sized companies have a higher adoption rate of healthcare-specific “small” task-specific models (54% and 57%, respectively) compared to small companies (34%). Small companies have a slightly lower usage of open source LLMs (27%) and proprietary LLMs through SaaS APIs (17%) compared to their larger counterparts. The dominance of healthcare-specific “small” models across all categories suggests they effectively address the industry’s unique needs. The popularity of open source models, both large and small, highlights a preference for cost-effective and adaptable solutions. Technical Leaders’ higher adoption likely stems from their deeper understanding of the technology’s potential. Lower adoption of proprietary LLMs, particularly on-premise solutions, could be due to cost and maintenance burdens.
Current Use Cases of LLMs
LLMs are gaining traction in healthcare, with a diverse range of applications. The survey reveals that answering patient questions (21%) is the most common use case, followed closely by medical chatbots (20%) and information extraction/data abstraction (19%).These findings highlight LLMs’ potential to improve patient communication and streamline clinical workflows.
Technical Leaders are at the forefront of LLM adoption. They more highly prioritize information extraction/data abstraction (38%) and biomedical research (33%) compared to the general survey population. This suggests a focus on leveraging LLMs for data analysis and research advancements. Compared to all respondents, Technical Leaders show a higher adoption rate across most use cases, suggesting that they are more likely to be at the forefront of implementing LLMs in their organizations. Company size also influences LLM adoption patterns. Smaller companies favor using LLMs for patient-facing applications like answering questions (38%) and medical chatbots (36%). Conversely, medium-sized companies lean toward clinical coding/chart audit (36%) and drug development (25%), potentially reflecting their emphasis on operational efficiency and R&D.
The results suggest that LLMs are being utilized across a wide range of use cases in the healthcare industry, with a focus on improving patient interactions, streamlining clinical processes, and advancing research. The higher adoption rates among Technical Leaders indicate that they are driving the implementation of these technologies within their organizations. The variations in use case adoption based on company size may reflect the different priorities and resources available to organizations of different scales.
Projected Impact of LLMs on Various Use Cases
Based on the survey results, respondents believe that LLMs will have a positive impact on various healthcare use cases over the next 2-3 years. On a scale of 1 to 5, with 5 being the highest impact, survey respondents rate “Transcribing Doctor-Patient Conversations” the highest at 3.85, followed by “Medical Chatbots” at 3.72, and “Answering Patient Questions” at 3.7. Technical Leaders show even higher expectations for these use cases, with ratings of 4.07, 4.22, and 3.87, respectively.
Interestingly, the survey reveals smaller companies have higher expectations for LLMs. They rate “Synthetic Data Generation” and “Transcribing Doctor-Patient Conversations” the highest at 3.91 and 4.0, respectively. This could be attributed to their greater agility in adopting new technologies like LLMs, potentially seeking a competitive advantage in the market. The findings suggest a shared belief that LLMs will have the most transformative impact on patient-facing applications such as transcribing conversations, providing medical chatbots, and answering patient questions. This aligns with the growing need for accessible and efficient healthcare, complemented by the advancements in LLMs’ natural language processing abilities.
Importance Ratings for Evaluating LLMs
Based on the survey results, respondents rate accuracy as the most important criterion when evaluating LLMs, with a mean response of 4.14 out of 5. This is followed closely by security and privacy risk (4.12) and healthcare-specific models (4.03). Technical Leaders place even greater emphasis on these three criteria, with mean responses of 4.2, 4.27, and 4.18, respectively. Interestingly, Technical Leaders also rate legal and reputation risk (4.15) and reproducible and consistent answers (4.02) as more important than the overall respondents do. Cost is considered the least important factor by both All Respondents (3.8) and Technical Leaders (3.91).
When comparing the results based on company size, small companies generally place higher importance on most of the criteria options compared to medium-sized and large companies. However, the differences are relatively minor, with the exception of reproducible and consistent answers, which small companies rate notably higher (4.11) than large (3.8) and medium-sized companies (3.68). The survey results suggest that accuracy, security, and privacy are the top priorities for healthcare professionals when evaluating LLMs. The higher importance placed on these criteria by Technical Leaders may indicate a deeper understanding of the potential risks and benefits associated with these models. The emphasis on healthcare-specific models highlights the need for tailored solutions that cater to the unique requirements of the healthcare industry. Finally, the relatively lower importance assigned to cost suggests that healthcare professionals are willing to invest in high-quality language models that prioritize accuracy, security, and privacy.
Evaluating Generative AI Roadblocks
Based on the survey results, All Respondents and Technical Leaders alike consider the lack of accuracy as the most significant limitation or roadblock to their roadmap for GenAI technology, with mean responses of 3.78 and 3.82, respectively. The second most important concern for both groups is the potential for major legal or reputational risks, with scores of 3.62 and 3.75.
Technical Leaders place slightly more importance on the technology falling short on bias and fairness requirements (3.71) compared to All Respondents (3.48). Both groups rank the technology not being designed specifically for healthcare and life science as the third most significant limitation, with scores of 3.65 and 3.60, respectively. When considering company size, respondents from large companies generally rate the limitations higher than those from medium-sized and small companies. However, small company respondents view the technology being too expensive as a more significant roadblock (3.56) compared to their counterparts in large (3.40) and medium-sized (2.86) companies.

The survey results suggest that the current state of GenAI technology faces challenges in meeting the accuracy, fairness, and industry-specific requirements needed for widespread adoption. The potential for legal and reputational risks also appears to be a major concern for organizations considering implementing these technologies. Additionally, the perceived high costs associated with GenAI may be a barrier for smaller companies looking to leverage these tools.
LLM Model Enhancement Strategies
Based on the survey results, the most common step taken by All Respondents to test and improve LLM models is “human in the loop” at 55%. This trend is consistent among Technical Leaders, with 58% of them employing this method. Other popular techniques include supervised fine-tuning (32% for All Respondents, 36% for Technical Leaders), interpretability tools and techniques (25% for All Respondents, 22% for Technical Leaders), and adversarial testing (23% for All Respondents, 29% for Technical Leaders).
Technical Leaders seem to prioritize de-biasing tools and techniques more than other roles, with 31% of them using these methods compared to only 18% of other roles. They also appear to favor red teaming slightly more than other roles (25% vs. 18%). When considering company size, small companies tend to focus more on supervised fine-tuning (39%) compared to large (26%) and medium-sized companies (25%). Medium-sized companies show a higher adoption of quantization and/or pruning techniques (36%) compared to large (14%) and small companies (17%). The use of guardrails is also more prevalent in medium-sized companies (30%) compared to large (15%) and small companies (23%). The high percentage of respondents using “human in the loop” suggests that human oversight and intervention remain crucial in ensuring the quality and performance of LLM models. The varying adoption rates of different techniques across company sizes may indicate that the choice of testing and improvement methods is influenced by factors such as available resources, data volume, and specific use cases. The higher emphasis on de-biasing tools and techniques among Technical Leaders reflects a growing awareness of the importance of addressing bias in LLM models.
Evaluation of LLM Solutions Against Key Requirements
The survey results reveal that among All Respondents, the most commonly tested requirements for LLM solutions are Fairness (32%), followed by Explainability (27%) and Private Data Leakage (27%). Bias, Hallucinations/Disinformation, and Freshness are each tested by about a quarter of respondents (26%, 26%, and 24%, respectively). The least tested requirements are Sycophancy (8%) and Prompt Injection (11%).
Technical Leaders show a somewhat different pattern, with Private Data Leakage (35%), Hallucinations/Disinformation (33%), and Bias (31%) being the most frequently tested. They are less likely than other roles to test for Fairness (22% vs. 35%) and more likely to test for Toxicity (18% vs. 9%). Company size also plays a role in testing priorities. Large companies are more likely to test for Fairness (31%) and Private Data Leakage (28%), while small companies focus more on Fairness (34%) and Bias (30%). Medium-sized companies stood out for their emphasis on Explainability (39%) and Hallucinations/Disinformation (32%). These results suggest that organizations are prioritizing different aspects of LLM performance based on their specific needs and concerns. The emphasis on Fairness, Explainability, and Private Data Leakage among All Respondents indicates a broad recognition of the importance of ethical and transparent AI. Technical Leaders’ focus on Private Data Leakage and Hallucinations/Disinformation may reflect a deeper understanding of the technical risks associated with LLMs.
Closing Thoughts
This survey provides valuable insights into the current state and future prospects of Generative AI in the healthcare industry. Through the lens of Technical Leaders and diverse organizational perspectives, we glean insights into the evolving landscape, where innovation, investment, and implementation strategies coalesce to redefine healthcare delivery and research. The survey results highlight the growing adoption of GenAI technologies, with Technical Leaders at the forefront of this trend. The significant projected increase in budget allocations for GenAI projects across various company sizes and roles suggests a growing recognition of the potential benefits and applications of this technology. Respondents indicate a clear preference for healthcare-specific, task-oriented language models, which more effectively address the industry’s unique needs. The popularity of open source models, both large and small, highlights a preference for cost-effective and adaptable solutions. Technical Leaders’ higher adoption rates across various language model types and use cases demonstrate their deeper understanding of the technology’s potential and their role in driving its implementation within their organizations. GenAI is being utilized across a wide range of use cases in the healthcare industry, with a focus on improving patient interactions, streamlining clinical processes, and advancing research. The shared belief that LLMs will have the most transformative impact on patient-facing applications, such as transcribing conversations, providing medical chatbots, and answering patient questions, aligns with the growing need for accessible and efficient healthcare.
The respondents’ emphasis on potential patient impacts of LLMs and GenAI supports the overwhelming trend to include human-in-the-loop approaches to GenAI implementations. In industries where regulations, data privacy, and high-stakes consequences are primary concerns, we’ll likely see humans and AI working together for the foreseeable future. However, the survey also highlights the challenges and concerns associated with the adoption of GenAI in healthcare. Healthcare professionals prioritize three key factors when evaluating GenAI for healthcare: ensuring accuracy, mitigating legal and reputational risks, and finding models specifically tailored to the unique needs of the healthcare industry. As the technology continues to evolve, it is crucial for healthcare organizations to address the limitations and roadblocks identified in the survey, such as the lack of accuracy, potential for bias, and industry-specific requirements. The emphasis on human oversight and intervention, as well as the varying adoption rates of different testing and improvement methods across company sizes, suggests that the development and deployment of GenAI in healthcare will require a collaborative effort between technical experts and domain specialists. Looking ahead, the future of GenAI in healthcare appears promising, with the potential to revolutionize patient care, streamline operations, and accelerate research. However, the success of this technology will depend on the ability of healthcare organizations to navigate the challenges associated with its adoption, prioritize ethical considerations, and ensure the development of accurate, secure, and privacy-preserving solutions tailored to the unique needs of the healthcare industry. With continued investment, collaboration, and thoughtful implementation, GenAI stands to redefine healthcare in ways we are only beginning to imagine.
Acknowledgements
Thanks to John Snow Labs for sponsoring this survey. This survey was conducted by Gradient Flow; see our Statement of Editorial Independence.
