We define Contract Understanding as the process of automatically checking an agreement and understanding the information contained in it. What has been mainly a manual process, can now be automatised (partially, with a human-in-the-loop philosophy) or even totally, using Natural Language Processing.
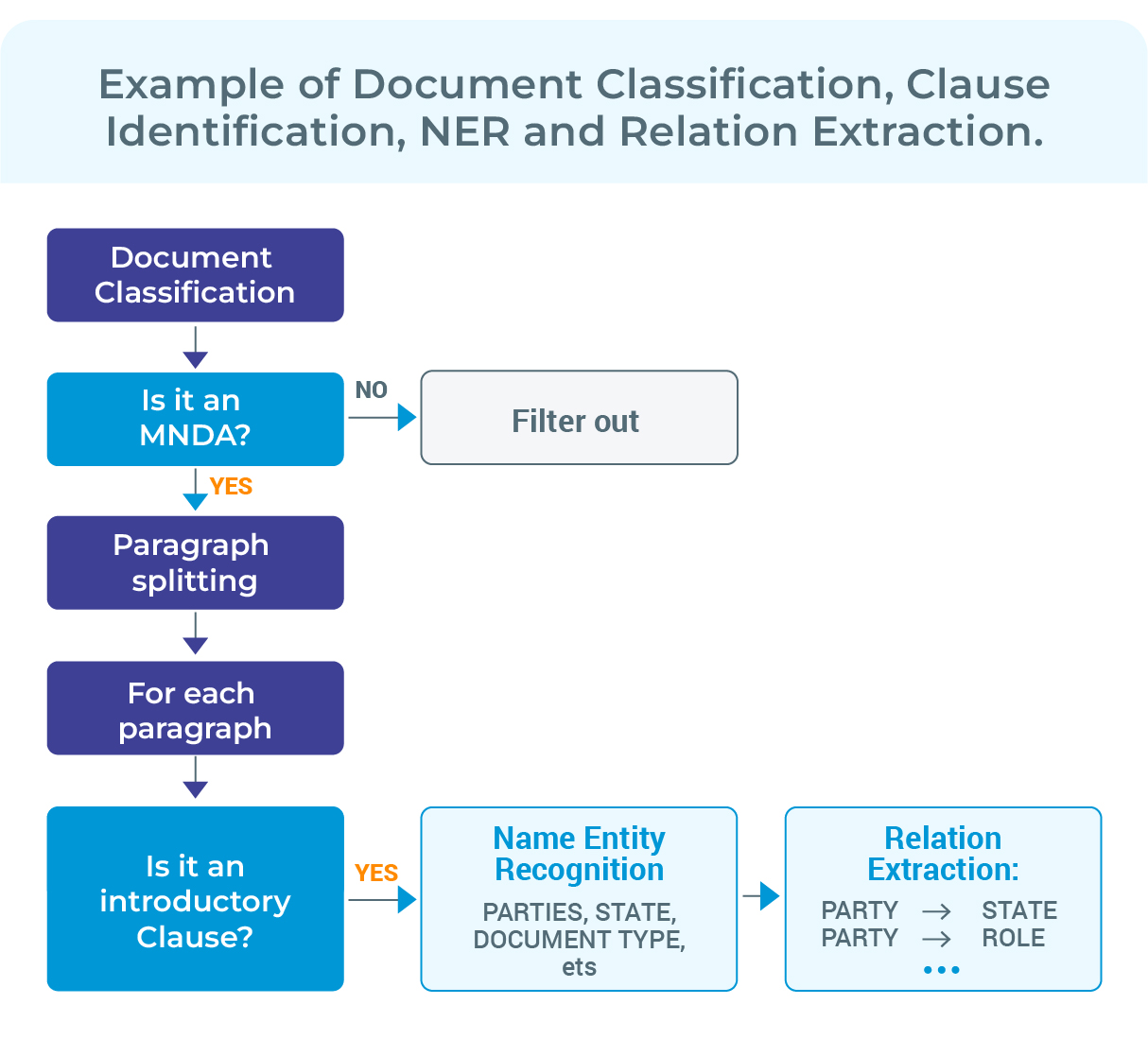
An NLP pipeline for legal processing of agreements usually include the following stages:
- Classification of the type of document. Filtering in/out types of documents you may have depending on their type is crucial, to remove everything you don’t want to process, and focus on only those documents which are relevant for your use case.
- Identification of the clauses in them.Agreements may have common clauses, or document-specific ones. You will always find an introductory clause talking about the parties, the effective date, and the type of agreement, but you will only find Return of Confidential Information clauses in, for example, NDA.
- Extracting information from clauses. After identifying a clause, you know what information to expect. If you are processing a section classified as Dispute Resolution,you already know you will find some Courts and ways to resolve the dispute (mediation, arbitration, litigation…)
- Extracting relations. If we come back to the first “introductory” clause where the names of the parties, very often we find that they come with their state or country (… a Delaware corporation…), their Alias or Role (… also known as “Borrower”…), etc. Knowing which specific Party is the Borrower, where that Party is located, etc. is crucial to automate the decision making.
 Let’s see how to carry out all of those steps with Legal NLP, an NLP library specialised in Legal Texts, part of the Spark NLP Ecosystem.
Let’s see how to carry out all of those steps with Legal NLP, an NLP library specialised in Legal Texts, part of the Spark NLP Ecosystem.
Installation
Installing Legal NLP is as simple as
! pip install -q johnsnowlabs
from johnsnowlabs import * nlp.install(force_browser=True)
You will connect to my.johnsnowlabs.com to retrieve your license, and the library will take care of the rest!
Starting a Spark Session
Legal NLP runs on top of Spark, a scalable, cluster-ready data analytics platform. To run a spark cluster, you only need to do:
nlp<span class="hljs-selector-class">.start</span>()
Stage 1: Document Classification
Let’s get 4 documents: two commercial lease agreements, one loan agreement and one credit agreement, and look for the commercial lease as an example.
<span class="hljs-attr">documents</span> = [commercial_lease,credit_agreement,loan_agreement,commercial_lease_2] <span class="hljs-comment"># We create a dataframe [[text1], [text2], ...]</span> <span class="hljs-attr">documents_df</span> = [[i] for i in documents]
document_assembler = nlp.DocumentAssembler()\
.setInputCol(<span class="hljs-string">"text"</span>)\
.setOutputCol(<span class="hljs-string">"document"</span>)
embeddings = nlp.BertSentenceEmbeddings.pretrained(<span class="hljs-string">"sent_bert_base_cased"</span>, <span class="hljs-string">"en"</span>)\
.setInputCols(<span class="hljs-string">"document"</span>)\
.setOutputCol(<span class="hljs-string">"sentence_embeddings"</span>)
doc_classifier = legal.ClassifierDLModel.pretrained(<span class="hljs-string">"legclf_commercial_lease"</span>, <span class="hljs-string">"en"</span>, <span class="hljs-string">"legal/models"</span>)\
.setInputCols([<span class="hljs-string">"sentence_embeddings"</span>])\
.setOutputCol(<span class="hljs-string">"category"</span>)
nlpPipeline = nlp.Pipeline(stages=[
document_assembler,
embeddings,
doc_classifier])
df = spark.createDataFrame(documents_df).toDF(<span class="hljs-string">"text"</span>)
model = nlpPipeline.fit(df)
result = model.transform(df)
result.select('category.result').show(truncate=False)
These are the components we have used:
- DocumentAssembler just assembles the text into Document type, necessary for Legal NLP to run NLP pipelines at scale.
- BertSentenceEmbeddings, our Language Model, maps text to a mathematical space, capturing all the meaning of the words. This will send those numerical coordinates of the text to the Classifier.
- ClassifierDLModel: our embeddings-based classifier.
And these are the results we get:

Ok, we know documents 1 and 4 are commercial leases, while 2 and 3 are something else! Let’s now try to find some specific clauses on them.
Stage 2: Splitting a document into smaller parts
Agreements are very long and contain several clauses in them. How to properly identify them?
- If we split by pages and do classification at page level, we may be getting more than one clause in a page.
- If we do classification at sentence level, there may not be much information to identify a clause.
The optimal splitting of agreements for clause identification is paragraphs. You can achieve Paragraph Splitting using TextSplitter:
document_assembler = nlp.DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
splitter = nlp.TextSplitter() \
.setInputCols(["document"]) \
.setOutputCol("paragraphs")\
.setCustomBounds(["\n\n"])\
.setUseCustomBoundsOnly(True)\
.setExplodeSentences(True)
nlp_pipeline = nlp.Pipeline(stages=[
document_assembler,
splitter])
As a result, you will have all the paragraphs of your document in the column “paragraphs”.
Stage 3: Identifying clauses
Let’s try to identify the “Introductory” clause, which usually looks like this:

Example of “Introductory” clause
To do that, we will add two new components:
- Again, BertSentenceEmbeddings, our Language Model, but now instead of sending the whole document, we send just paragraphs.
- ClassifierDLModel will now help us to classify not the document, but the clauses. Since we are sending now paragraphs, and using Clause Classifiers, we can say this is “clause classification”, compared to “document classification” of step 1.
documentAssembler = nlp.DocumentAssembler() \
.setInputCol("paragraphs") \
.setOutputCol("document")
embeddings = nlp.BertSentenceEmbeddings.pretrained("sent_bert_base_cased", "en") \
.setInputCols("document") \
.setOutputCol("sentence_embeddings")
docClassifier = legal.ClassifierDLModel.pretrained("legclf_introduction_clause", "en", "legal/models")\
.setInputCols(["sentence_embeddings"])\
.setOutputCol("category")
nlpPipeline = nlp.Pipeline(stages=[
documentAssembler,
embeddings,
docClassifier])
The results are the following:

It has clearly identifying some paragraphs containing information about the parties (“introduction”) in the paragraphs 1, 3 and 4.
Now we now where Introduction information is, let’s do specific NER on them!
Stage 4: Clause-specific NER
Legal NLP NER models run mainly at clause level. That means you should first identify where to run those NER models. Why? Because extracting Parties name everywhere in a document, as an example, may retrieve a lot of false positives about third parties mentioned in the document which are not directly related to this agreement. Identifying Parties in the proper place is key to minimize false positives and also, improves performance and computation times.
This time, we are going to use, instead of one annotator for NER added to a pipeline, a PretrainedPipeline, trained and uploaded before hand. This way, you don’t need to create the pipeline yourself, it’s already done for you and available in our Models Hub.
legal_pipeline = nlp.PretrainedPipeline("legpipe_ner_contract_doc_parties_alias_former", "en", "legal/models")
This pipelines uses NER and ZeroShotNer to retrieve for you:
- DOC_TYPE: Type of the agreement
- PARTY: Names of the parties
- ALIAS: Aliases or Roles of the parties (…also known as “Borrower”…)
- EFFDATE: Effective Date of the contract.
- FORMER_NAME: Former names of the parties (…previously known as …)
You can run Pretrained Pipelines just by using annotate command on a text:
result = legal_pipeline.fullAnnotate(text)[0]
Let’s use our Spark NLP Visualization Library to show the NER results:
from johnsnowlabs import viz ner_viz = viz.NerVisualizer() ner_viz.display(result, label_col='ner_chunk')
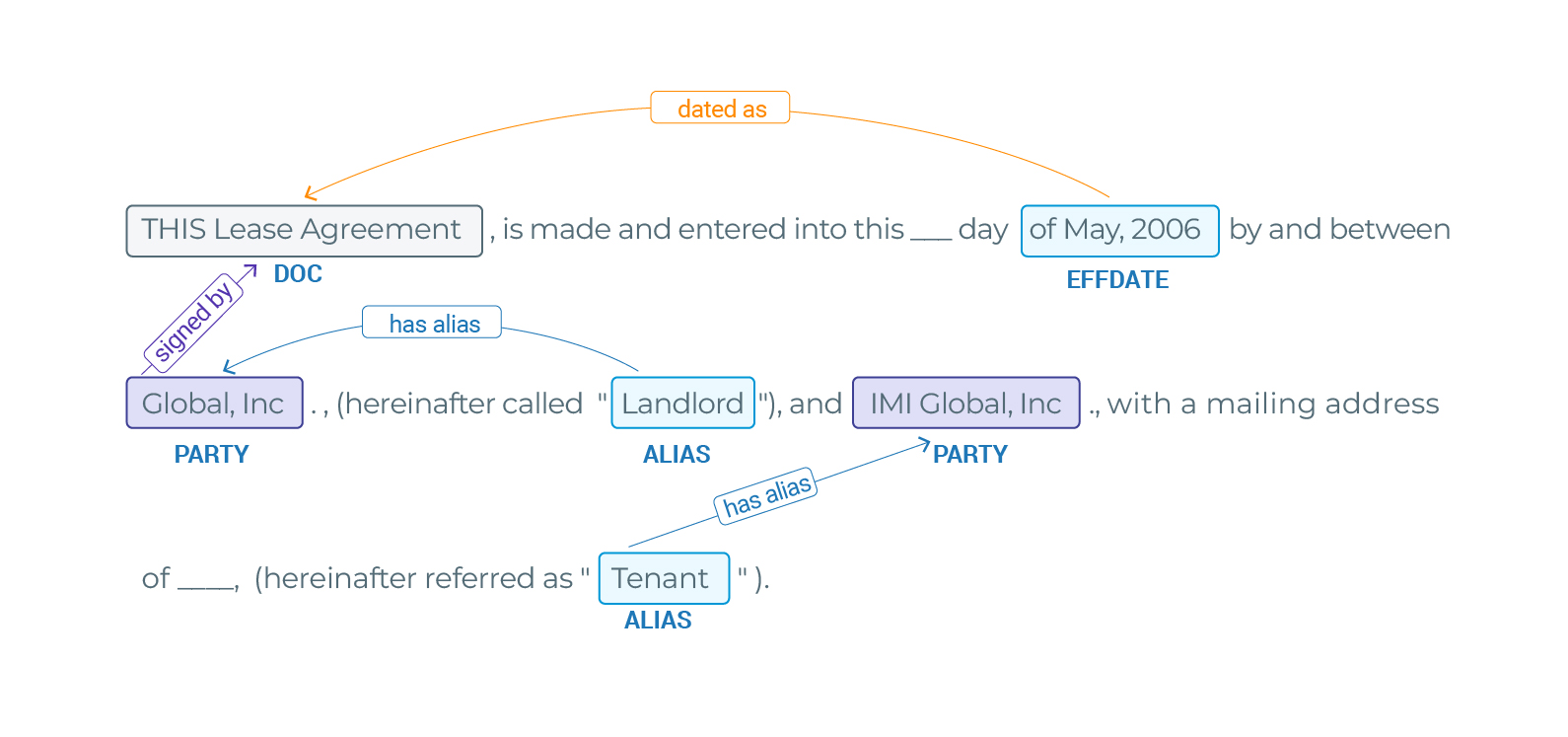
The results are the following: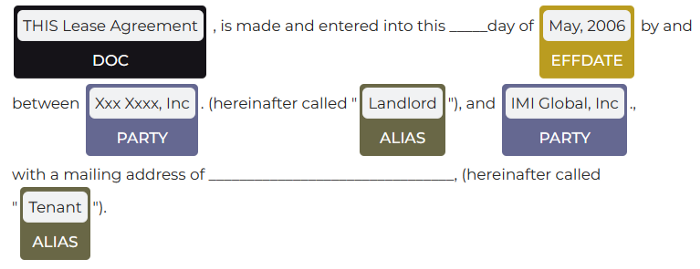
Stage 5: Clause-specific Relation Extraction
Again, as with NER, Relation Extraction models should be run on their specific clauses. Introductory-clause relation extraction should be run on the results of Introductory NER of Introductory clauses. Make sense, right?
Again, we are going to use, instead of a custom pipeline, a PretrainedPipeline, trained and uploaded before hand. This way, you don’t need to create the pipeline yourself, it’s already done for you and available in our Models Hub. It carries out NER and RE on introductory clauses to extract relations between:
- Document Types and the Parties;
- Document Types and the Effective Date;
- Parties and their Roles / Aliases;
from sparknlp.pretrained import PretrainedPipeline
pipeline = nlp.PretrainedPipeline("legpipe_re_contract_doc_parties_alias", "en", "legal/models")
You can run Pretrained Pipelines just by using fullAnnotate command on a text, as we did with NER…
result = legal_pipeline.fullAnnotate(text)[0]
… and after, visualize the results with Spark NLP Display library…
from sparknlp_display import RelationExtractionVisualizer re_vis = viz.RelationExtractionVisualizer() re_vis.display(result = result[0], relation_col = "relations", document_col = "document", exclude_relations = ["other"], show_relations=True)
 You can check how to manually create all the pipelines to customize parameters as acceptable confidence rates in the notebook below.
You can check how to manually create all the pipelines to customize parameters as acceptable confidence rates in the notebook below.
Notebook
Here you can find this notebook so that you run and check the previous results and also check the manual creation of the NER+RE pipeline in case you want to modify something.
About Legal NLP
Legal NLP is a John Snow Lab’s product, launched 2022 to provide state-of-the-art, autoscalable, domain-specific NLP on top of Spark.
With more than 600 models, featuring Deep Learning and Transformer-based architectures, Legal NLP includes:
- Annotators to carry out Name Entity Recognition, Relation Extraction, Assertion Status / Understanding Entities in Context, Data Mapping to external sources, Deidentification, Question Answering, Table Question Answering, Sentiment Analysis, Summarization and much more, both training andinference!
- Zero-shotName Entity Recognition and Relation extraction;
- 600+ pretrained Deep Learning / Transformer-based models;
- Fully integration with Databricks, AWS or Azure;
- 33+ notebooks and 25+ demos ready to showcase its features.
- Full integration with NLP Lab (former Annotation Lab) for managing your annotation projects and train your legal models in a zero-code fashion.
- Compatiblity with Visual NLP, to combine OCR/Visual capabilities, as Signature Extraction, Form Recognition or Table detection, to Legal NLP.
How to run
Legal NLP is very easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
from johnsnowlabs import * nlp.install(force_browser=True) nlp.start()
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our legal team of technical and SME. Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!