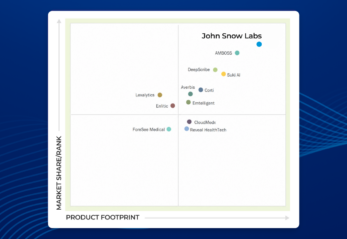
John Snow Labs is making its licensed libraries for state-of-the-art natural language processing – Spark NLP for Healthcare and Spark OCR – available under a free license for academic researchers, educators, and students. This includes over 1,000 pre-trained models as well as the entire catalog of over 2,220 expert-curated datasets in its Data Library.
You can get a free personal license if you are doing academic research that will be publicly published under open-access, open-source, and open-data principles. If you are teaching a course that makes use of the library, you and your students can get a free license for it. We can also provide you with learning materials – from Python notebooks to slides & exercises.
The free license includes the full capabilities of the software, all pre-trained models, and regular updates. Its goal is to enable you to easily reuse, reproduce, and improve production-grade, state-of-the-art NLP in your research & teaching.
Start here to apply for your free license. Please use your university’s email address and briefly explain how you will use the academic license. If you have more questions, feel free to reply to this email with your questions or proposed times for a call.
The full Spark NLP for Healthcare gives you access to state-of-the-art pretrained models and pipelines for:
- Clinical named entity recognition – train your own or use pre-trained models to extract clinical facts (symptoms, diagnoses, treatments, procedures), drug facts (name, strength, dosage, route, frequency, duration), and biomedical terms (organism, tissue, gene, gene product, chemical, etc.).
- Assertion status detection – telling between positive assertions (“patient has diabetes”), negative assertions (“no fever”), uncertain assertions (“shows indications of depression”), or assertions about other people (“family history of lung cancer”).
- Entity resolution – train your own or use pre-trained models to resolve recognized entities to SNOMED-CT, ICD-10-CM, ICD-10-PCS, CPT, or RxNorm.
- De-identification – Anonymize either structured tables or unstructured free text including all HIPAA-required fields and then either remove, mask, or obfuscate PHI.
- Relation extraction – use pretrained models to automatically identify relations between entities such as drugs, dosage, duration, frequency, clinical events among many others.

Spark OCR library accurately transforms PDF and image files to digital text and includes a set of built-in algorithms for:
- image pre-processing (binarizer, thresholding, erosion, scaling, skew correction),
- image cleansing (noise scorer, remove objects, morphology), and
- handling of complex document layouts (LayoutAnalyzer, SplitRegions, DrawRegions, PositionFinder).
![]()

The newly launched medical datasets will give you immediate access to more than 2,200 expert-curated databases. For downloading any dataset as well as its metadata in PDF and JSON formats you just need to register with a valid email. You will also receive immediate access to all datasets and to all updates as soon as they are published on the website.
Inspired by Dr. John Snow – the medical doctor who helped stop the outbreak of cholera in 1854 London by analyzing data – our company’s main focus is that of empowering many more like him in the 21st century. You have our commitment and support to help you succeed in your academic project or research paper.