Version 1.5 of the Annotation Lab overhauls the ability to train NLP models, apply active learning to train models automatically as new labels are available, and use pre-annotation to accelerate domain experts’ work. Here are the highlights of how this works.
Models Training
We are shipping the models training feature for Clinical NER projects. A Project Owner or a Manager can use annotated text (completions) for training a new Spark NLP NER model. The training component can be found on the Setup page.
The “Train Now” button (See Arrow 6) can be used to trigger training of a new NER model when no other trainings or preannotations are in progress. Otherwise, the button is disabled. Information on the training progress is shown in the top right corner of the Model Training tab (See 5). Here the user can get indications on the success or failure message depending on how the last training ended.
Training Failure can occur because of:
- Insufficient and poor completions/extractions quality
- Wrong training parameters (more on this below)
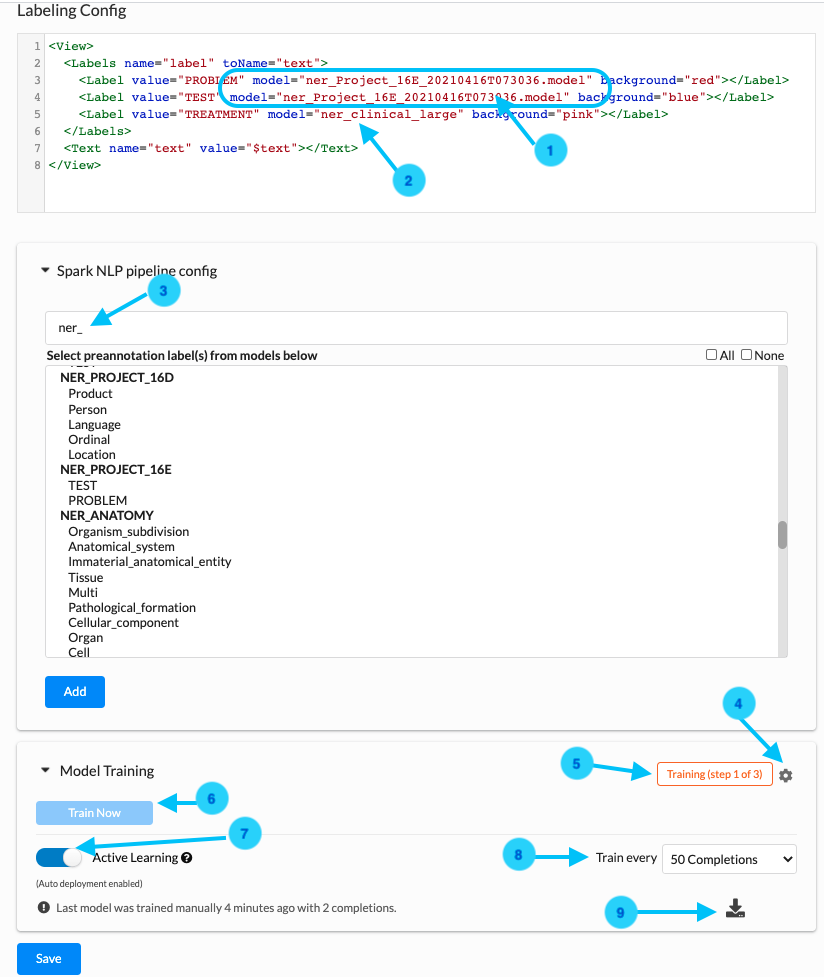
When triggering the training, users are prompted to choose either to immediately deploy models or just do training. If immediate deployment is chosen, then the Labeling config is updated according to the name of the new model (1).
It is possible to download training logs by clicking on the download logs icon (9) of the recently trained NER model which includes information like training parameters and TF graph used along with precision, recall, f1 score, etc.
Training parameters
It is possible to tune the most common training parameters (Validation split ratio, Epoch, Learning rate, Decay, Dropout, and Batch) using the window which can be viewed by clicking on the gear icon (4).
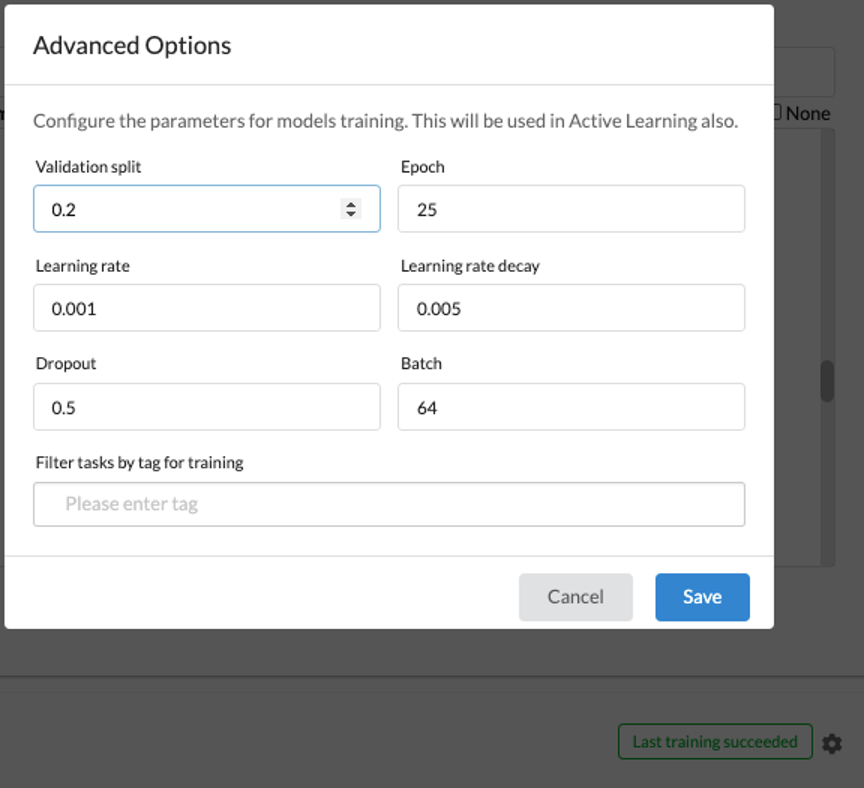
It is also possible to only use some tasks for training by selecting the Tags using the feature present at the end of the window.
Selection of Completions
During the annotation project lifetime, normally not all tasks/completions are ready to be used as a training dataset. So, the training process selects completions based on their status. Here is how selection happens:
- Filter tasks by tags (if defined in Training Parameters window, otherwise all tasks are selected)
- For completed tasks, completions to be taken into account are also filtered based on
- If a task has a completion accepted by a reviewer this is selected for training and all others are ignored
- Reviewer rejected completions are not used for training
- If no reviewer is assigned to a task that has multiple submitted completions the most recent completion is selected for training purpose
Active Learning
Project Owners or Managers can enable the Active Learning feature by clicking on the corresponding Switch (7) available on Model Training tab. If this feature is enabled, the NER training gets triggered automatically on every 50 new completions (the completions are counted as mentioned in the above section). It is also possible to change the completions frequency by dropdown (8) which is visible only when Active Learning is enabled.
While enabling this feature, users are asked whether they want to deploy the newly trained model right after the training process or not.
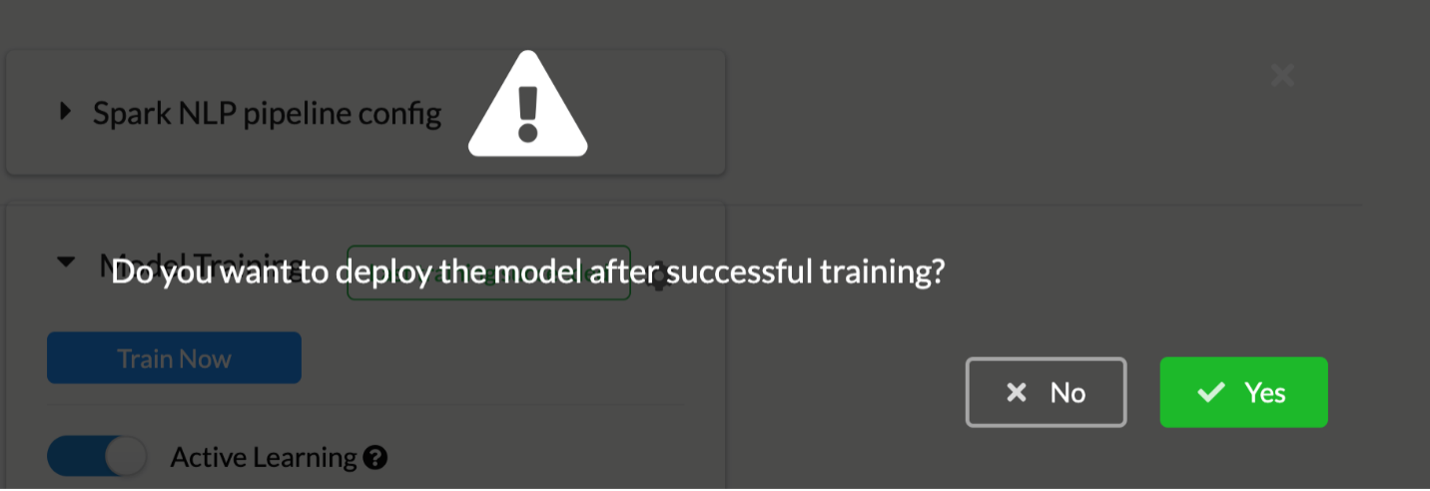
If the user chooses not to automatically deploy the newly trained model, this can be done on demand by navigating to the Spark NLP pipeline config and filtering the model by name of the project (3) and select that new model trained by Active Learning. This will update the Labeling Config (name of the model in tag is changed). Hovering on each trained model will show the training date and time.
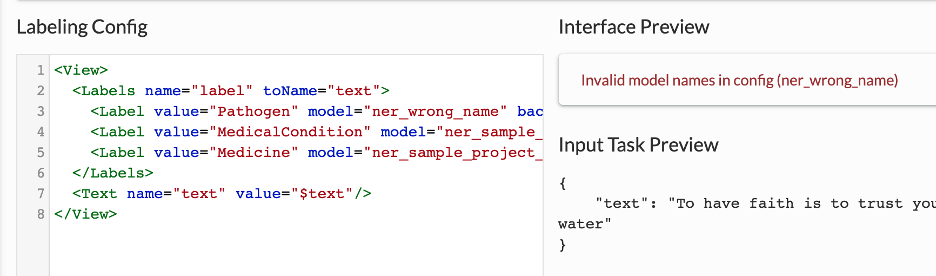
If the user opts for deploying the model after the training, the Project Configuration is automatically updated for each label that is not associated with a pretrained Spark NLP model, the model information is updated with the name of the new model.
If there is any mistake in the name of models, the validation error is displayed in the Interface Preview Section present on the right side of the Labeling Config area.
Preannotation
For running preannotation on one or several tasks, the Project Owner or the Manager must select the target tasks and can click on the Preannotate Button from the upper right side of the Tasks List Page. This will display a popup with information regarding the last deployment including the list of models deployed and the labels they predict.
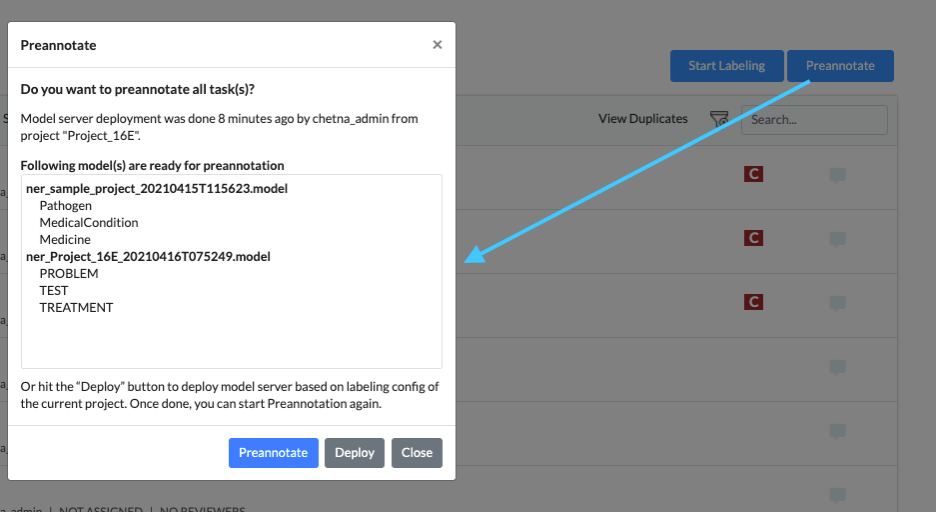
This information is very important, especially when multiple users are doing training and deployment in parallel. So before doing annotations on your tasks, carefully check the list of currently deployed sets of models and their labels.
If needed, users can redeploy the models based on the Labeling Config of the current project by hitting the “Deploy” button from the same window. After the deployment is complete, the preannotation can be started again.