






















































The latest version of TextMatcher in Healthcare NLP introduces powerful linguistic enhancements such as lemmatization, stemming, stopwords removal, and token shuffling. These new features provide a flexible yet efficient way to perform high-quality phrase matching in unstructured text.
Text matching is a critical component in many NLP pipelines — from clinical concept recognition to entity extraction in unstructured text. But traditional methods often fall short when dealing with the fluid and inconsistent nature of language. Inflected words, reordered tokens, irrelevant stopwords, or domain-specific noise can easily cause exact-match systems to overlook valuable information.
With the latest update to Healthcare NLP, the TextMatcher module introduces a smarter, more linguistically aware text matching engine. It brings support for lemmatization, stemming, token shuffling, customizable stopword handling, and fine-grained control over matching behavior — all designed to significantly improve both recall and precision in complex or noisy text.
In this post, we’ll walk through each of the new capabilities, show how they work in practice, and explain how they help you build more resilient and context-aware NLP systems.
Named Entity Recognition (NER) Methods and Tools - Healthcare NLP
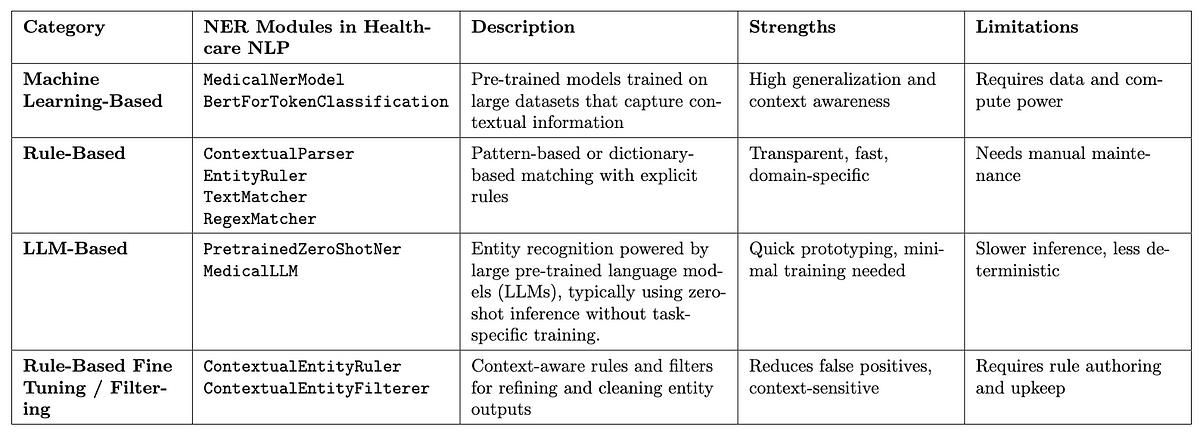
Healthcare NLP offers three main approaches for extracting entities from clinical and medical text: Machine Learning-based, Rule-Based, and LLM-based methods. Each approach has its own advantages depending on the use case and requirements.
Additionally, tools like ContextualEntityRuler and ContextualEntityFilterer provide fine-tuning and output filtering capabilities to enhance rule-based pipelines. This comprehensive ecosystem enables both high accuracy and flexibility.
If you’d like to explore the practical use of NER models in Healthcare NLP, check out the following resources:
- Hands-on NER tutorial notebook: Clinical NER with Healthcare NLP
- Performance benchmark: Comparing De-identification Performance: Amazon vs Azure vs Healthcare NLP
The table below summarizes these methods, models, and tools with brief descriptions, along with their strengths and limitations.
What is TextMatcher in Healthcare NLP?
TextMatcher is one of the core annotators in Healthcare NLP, designed to match exact phrases within unstructured text. It works by comparing tokenized input against a predefined list of phrases — typically loaded from an external file — and returns matching segments as CHUNK annotations.
Unlike fuzzy or model-based approaches, TextMatcher operates with high precision by relying on token-level exact matching, making it ideal for use cases where matching consistency and interpretability are essential — such as identifying known drug names, procedure codes, or policy phrases.
Internally, TextMatcher uses a SearchTrie-based algorithm, which enables fast and efficient lookup of multi-token phrases across large documents and vocabularies.
To run, TextMatcher requires the following inputs:
DOCUMENT: the full text to processTOKEN: the tokenized version of the input
Its output:
CHUNK: the matched phrases found within the text
This makes TextMatcher both lightweight and highly scalable — perfect for high-volume information extraction pipelines that require exact term recognition without the overhead of deep learning.
In the next section, we’ll see how TextMatcher builds upon this foundation to support flexible, linguistically-informed matching for more real-world robustness.
What’s New in TextMatcher?
TextMatcher has evolved beyond simple exact matching to support a range of linguistically informed and customizable options. These new capabilities are designed to improve both recall and precision when dealing with messy, variable, or naturally flexible language
Here’s an overview of what’s new in the latest version:
Lemmatization & Stemming
Enable normalization of word forms so that variations like “running” and “run”, or “stressors” and “stressor” can be matched correctly.
setEnableLemmatizer(True): reduces words to their dictionary base formsetEnableStemmer(True): trims suffixes to match root forms
Example:
"running"→ matches"run""studies"→ matches"study"
Token Shuffling
Match phrases even when the word order changes slightly.
setShuffleEntitySubTokens(True): enables all permutations of token order for each entity phrase
Example:
Entity: "sleep difficulty"
Matches:"difficulty sleeping", "sleep difficulty"
This is especially useful when word order varies across different sentence constructions.
Stopword Handling
Reduce false negatives caused by unimportant words such as “and”, “of”, “about”.
setCleanStopWords(True): removes common stopwords from both source text and entity listsetStopWords([...]): provide a custom stopword listsetSafeKeywords([...]): preserve important domain-specific stopWordssetCleanKeywords([...]): remove custom noise terms (e.g.,"note","type")setExcludePunctuation(True): drop punctuation during matching
Example:
"evaluation of psychiatric state"→ matches"evaluation psychiatric state"
Augmentation Controls
Control how much automatic variation the matcher performs on source text and entities.
setSkipMatcherAugmentation(True): disables augmentation of entity phrasessetSkipSourceTextAugmentation(True): disables augmentation on input text
Use these settings to optimize for performance when needed.
Match Output Control
Specify the format of the returned chunks.
setReturnChunks("original"): returns the phrase as it appears in the inputsetReturnChunks("matched"): returns the normalized matched form (after stemming/lemmatization)
Note: Regardless of this setting, the begin and end character offsets always refer to the original text.
Enhanced Text Matching in Action: A Comparative Look
In this section, we demonstrate how enabling these options significantly improves text matching by comparing a baseline matcher with a fully enhanced configuration.
Example Input:
text = """ Patient was able to talk briefly about recent life stressors during evaluation of psychiatric state. She reports difficulty sleeping and ongoing anxiety. Denies suicidal ideation. """
And a list of phrases we want to detect:
test_phrases = """
stressor
suicidal deny
sleep difficulty
evaluation psychiatric state
anxiety
"""
with open("test-phrases.txt", "w") as file:
file.write(test_phrases)
We define two versions of TextMatcher: one with default (basic) settings, and one with all enhancements enabled.
# Basic matcher: exact token matching only
text_matcher_basic = TextMatcherInternal()\
.setInputCols(["sentence","token"])\
.setOutputCol("matched_text_basic")\
.setEntities("./test-phrases.txt")
# Enhanced matcher with all advanced options enabled
text_matcher_enhanced = TextMatcherInternal()\
.setInputCols(["sentence","token"])\
.setOutputCol("matched_text_enhanced")\
.setEntities("./test-phrases.txt")\
.setEnableLemmatizer(True)\
.setEnableStemmer(True)\
.setCleanStopWords(True)\
.setBuildFromTokens(False)\
.setReturnChunks("matched")\
.setShuffleEntitySubTokens(True)
Results: Basic Matcher
+------+-----+---+-------+ |entity|begin|end|result | +------+-----+---+-------+ |entity|146 |152|anxiety| +------+-----+---+-------+
Results: Enhanced Matcher
+------+-----+---+----------------------------+-------------------------------+ |entity|begin|end|matched_text |original | +------+-----+---+----------------------------+-------------------------------+ |entity|69 |99 |evaluation psychiatric state|evaluation of psychiatric state| |entity|52 |60 |stressor |stressors | |entity|146 |152|anxiety |anxiety | |entity|114 |132|difficulty sleep |difficulty sleeping | |entity|155 |169|deni suicidal |Denies suicidal | +------+-----+---+----------------------------+-------------------------------+
With the advanced settings enabled:
- Stemming/Lemmatization allows matching
"stressors"to"stressor"and"sleeping"to"sleep". - Stopword Cleaning enables
"evaluation psychiatric state"to match"evaluation of psychiatric state". - Token Shuffling ensures
"suicidal deny"matches"Denies suicidal"even if the token order is reversed. - The
matched_textcolumn shows the raw matched text from the input, making it easy to trace.
Combining TextMatcher with MedicalNerModel
While pretrained clinical NER models are powerful for extracting standardized biomedical entities, they may not always capture context-specific or custom phrases. That’s where TextMatcher complements the NER model — by allowing you to inject custom vocabulary and domain-specific expressions into your extraction pipeline.
In this example, we use both models in the same pipeline to demonstrate their synergy.
Example Input:
text = """ HYPERBILIRUBINEMIA: At risk for hyperbilirubinemia due to prematurity. Mother is A+ and infant delivered for decreasing fetal movement and preeclampsia. Long fingers and toes were detected.Cardiac evaluation revealed evidence of bidirectional shunting, suggestive of transitional circulatory dynamics. Additionally, a persisting patent ductus arteriosus (PDA) was noted during cardiac-related assessments, which is quite common in this demographic. """
Pipeline Components:
# Pretrained clinical NER model for phenotype/gene recognition
clinical_ner = MedicalNerModel.pretrained(
"ner_human_phenotype_gene_clinical_langtest",
"en", "clinical/models"
).setInputCols(["sentence", "token", "embeddings"]) \
.setOutputCol("ner")
# Custom text matcher with flexible matching logic
text_matcher = TextMatcherInternal()\
.setInputCols(["sentence", "token"])\
.setOutputCol("matcher_chunk")\
.setEntities("./test-phrases.csv")\
.setDelimiter("#")\
.setEnableLemmatizer(True)\
.setEnableStemmer(False)\
.setCleanStopWords(True)\
.setBuildFromTokens(True)\
.setReturnChunks("original")\
.setExcludePunctuation(True)\
.setShuffleEntitySubTokens(False)
NER Model Output:
+------+-----+---+----------------------+
|entity|begin|end|result |
+------+-----+---+----------------------+
|HP |33 |50 |hyperbilirubinemia |
|HP |127 |134|movement |
|HP |230 |251|bidirectional shunting|
|HP |337 |353|ductus arteriosus |
+------+-----+---+----------------------+
TextMatcher Output:
+------+-----+---+-------------------------+ |entity|begin|end|result | +------+-----+---+-------------------------+ |HPO |33 |50 |hyperbilirubinemia | |HPO |140 |151|preeclampsia | |HPO |110 |134|decreasing fetal movement| |HPO |154 |165|Long fingers | |HPO |230 |251|bidirectional shunting | +------+-----+---+-------------------------+
Additionally, the matcher identified extra mentions such as preeclampsia, Long fingers, and decreasing fetal movement, which were not detected by the NER model.
We can combine the outputs of the pretrained NER model and the custom text matcher using ChunkMergeModel.
# Merge chunks from NER and TextMatcher into a single column
chunk_merger = ChunkMergeModel()\
.setInputCols("ner_chunk", "matcher_chunk")\
.setOutputCol("hpo_terms")
Result:
+------+-----+---+-------------------------+ |entity|begin|end|result | +------+-----+---+-------------------------+ |HPO |33 |50 |hyperbilirubinemia | |HPO |110 |134|decreasing fetal movement| |HPO |140 |151|preeclampsia | |HPO |154 |165|Long fingers | |HPO |230 |251|bidirectional shunting | |HPO |337 |353|ductus arteriosus | +------+-----+---+-------------------------+

Example Usage
To see TextMatcher in action, including how to configure it for different scenarios using stemming, lemmatization, stopword cleaning, and token shuffling, check out the official Healthcare NLP notebook below:
TextMatcher Example — GitHub Notebook
This notebook walks you through:
- How to load and prepare entity phrases
- How to configure matcher parameters
- Practical clinical text matching examples
It’s a great starting point for building your own matcher pipeline or experimenting with different matching behaviors on real-world data.
Conclusion
TextMatcher bridges the gap between fast, rule-based phrase recognition and the linguistic flexibility often needed in real-world NLP. By combining tools like lemmatization, stemming, stopword handling, token shuffling, and customizable augmentation, it empowers practitioners to build more accurate and resilient matchers without sacrificing performance.
Together, these features make TextMatcher a powerful tool for any NLP task that demands flexible, accurate, and domain-adapted text matching
Whether you’re working on information extraction, rule-based tagging, or clinical decision support, this upgrade brings matching one step closer to true language understanding.



