
























































Re-engineering clinical practice guideline delivery with structured NLP and domain-tuned language models.
Modern guideline developers spend years curating evidence, yet the final product often lands on a busy clinician’s screen as a static PDF. General-purpose large language models (LLMs) promise an easier interface, but real-world studies show high miss rates and shallow reasoning when faced with multi-morbid patients or shifting contraindications [1][2]. The gap between written guidance and bedside action remains.
When guidelines and patient data share a structured language, AI moves from summarizing text to supporting judgment, quietly lifting cognitive load instead of adding another screen.
Why generic LLMs fall short
- Limited patient memory: everything hinges on what the user types.
- Text-level retrieval: models quote guidelines but struggle with thresholds, exceptions, or time-dependent logic.
- Fluency without depth: confident prose can mask clinical inaccuracies, creating silent risk [3].
A structured alternative
John Snow Labs proposes stitching together structured patient timelines with computable guidelines:
| Generic LLM + RAG | John Snow Labs Structured Pipeline | |
| Patient context | Free-text prompt | Longitudinal graph built from Spark NLP (NER, assertion status, temporal links) |
| Guideline handling | Paragraph snippets | Machine-readable rules mirrored from source guideline text |
| Reasoning depth | Single-turn Q&A | Graph-aware LLM draws on history, labs, and coded terminologies |
| Outcome | Fluent but brittle | Transparent, patient-specific justification |
Key building blocks
- Healthcare NLP – 200+ annotators capture entities, temporal cues, negation, and map terms to SNOMED CT, RxNorm, and other ontologies.
- Temporal & causal extraction – components such as TemporalRelationExtractor order events, letting the system weigh “GI bleed after apixaban” correctly.
- Medical-Reasoning LLM 14B – tuned on curated clinical corpora, it outperforms GPT-4 on OpenMed treatment planning tasks, especially where comorbid kidney and cardiovascular disease intersect.
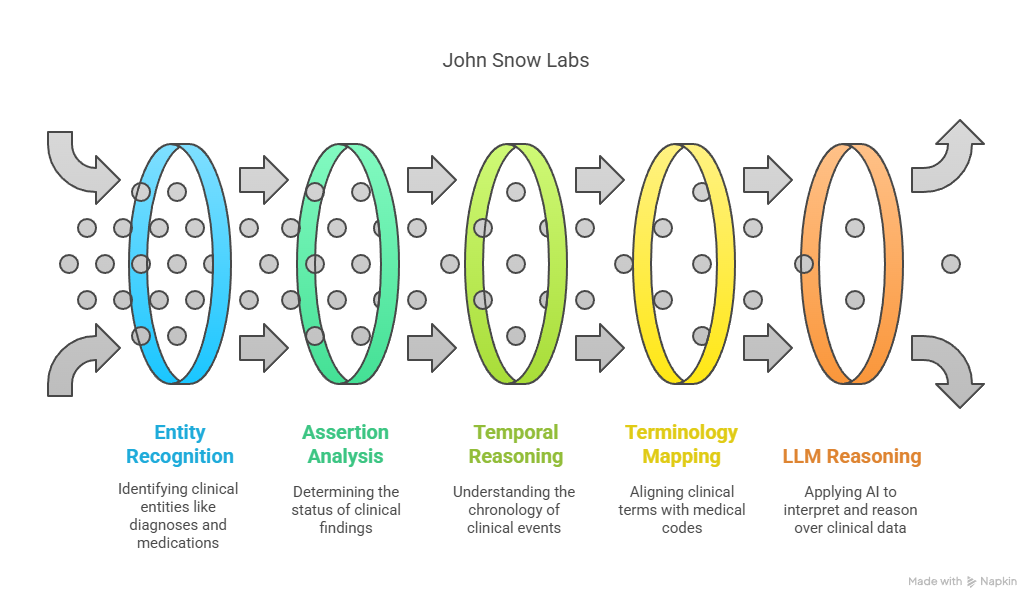
Implications for guideline creators
- Author once, compute many times. Converting narrative text to logic enables automated consistency checks and multi-guideline interaction analysis [6].
- Shorten the translation loop. A computable format allows instant simulation of how a new threshold echoes through clinical scenarios.
- Benchmark on real patient journeys, not synthetic prompts. Structured representations open the door to large-scale, de-identified replay of electronic health record episodes during guideline drafting.
- Incremental rollout. JSL components run inside common Spark clusters letting teams pilot one specialty before scaling.
For a more detailed analysis, you can read the full article here.
References
[1] S. Beck, M. Kuhner, M. Haar, A. Daubmann, M. Semmann, and S. Kluge, “Evaluating the accuracy and reliability of AI chatbots in disseminating the content of current resuscitation guidelines: a comparative analysis between the ERC 2021 guidelines and both ChatGPTs 3.5 and 4,” Scand J Trauma Resusc Emerg Med, vol. 32, no. 1, p. 95, Sep. 2024, doi: 10.1186/s13049-024-01266-2. [2] S. Pandya, T. E. Bresler, T. Wilson, Z. Htway, and M. Fujita, “Decoding the NCCN Guidelines With AI: A Comparative Evaluation of ChatGPT-4.0 and Llama 2 in the Management of Thyroid Carcinoma,” The American SurgeonTM, vol. 91, no. 1, pp. 94–98, Jan. 2025, doi: 10.1177/00031348241269430. [3] M. Balas, E. D. Mandelcorn, P. Yan, E. B. Ing, S. A. Crawford, and P. Arjmand, “ChatGPT and retinal disease: a cross-sectional study on AI comprehension of clinical guidelines,” Canadian Journal of Ophthalmology, vol. 60, no. 1, pp. e117–e123, Feb. 2025, doi: 10.1016/j.jcjo.2024.06.001. [4] Y. Wang, S. Visweswaran, S. Kapoor, S. Kooragayalu, and X. Wu, “ChatGPT-CARE: a Superior Decision Support Tool Enhancing ChatGPT with Clinical Practice Guidelines,” Aug. 13, 2023. doi: 10.1101/2023.08.09.23293890. [5] S. Kresevic, M. Giuffrè, M. Ajcevic, A. Accardo, L. S. Crocè, and D. L. Shung, “Optimization of hepatological clinical guidelines interpretation by large language models: a retrieval augmented generation-based framework,” npj Digit. Med., vol. 7, no. 1, p. 102, Apr. 2024, doi: 10.1038/s41746-024-01091-y. [6] V. Zamborlini et al., “Analyzing interactions on combining multiple clinical guidelines,” Artificial Intelligence in Medicine, vol. 81, pp. 78–93, Sep. 2017, doi: 10.1016/j.artmed.2017.03.012.



