

































Identifying opioid-related adverse events from unstructured text in electronic health records using rule-based algorithms and deep learning methods



























Speed up data labeling, train, tune, test and improve your models — all within one unified, scalable, and HIPAA compliant platform.
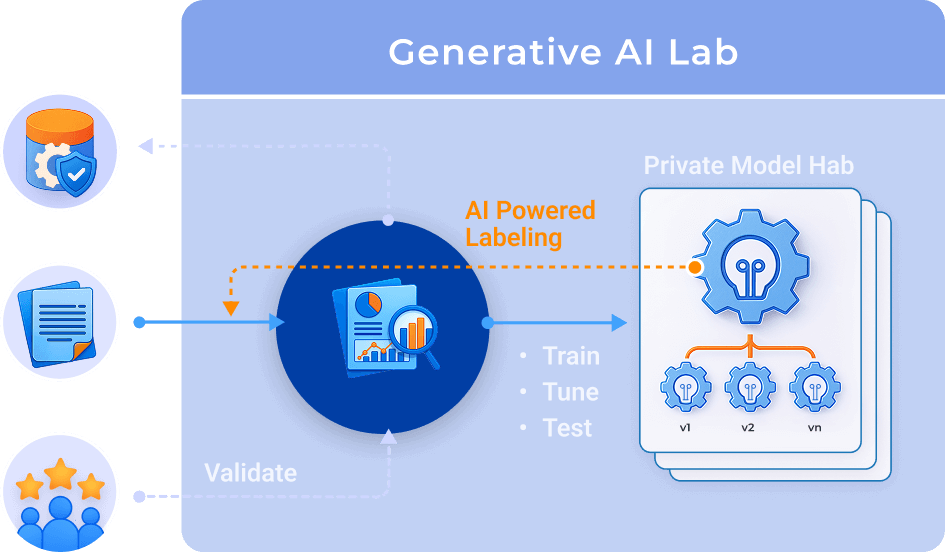













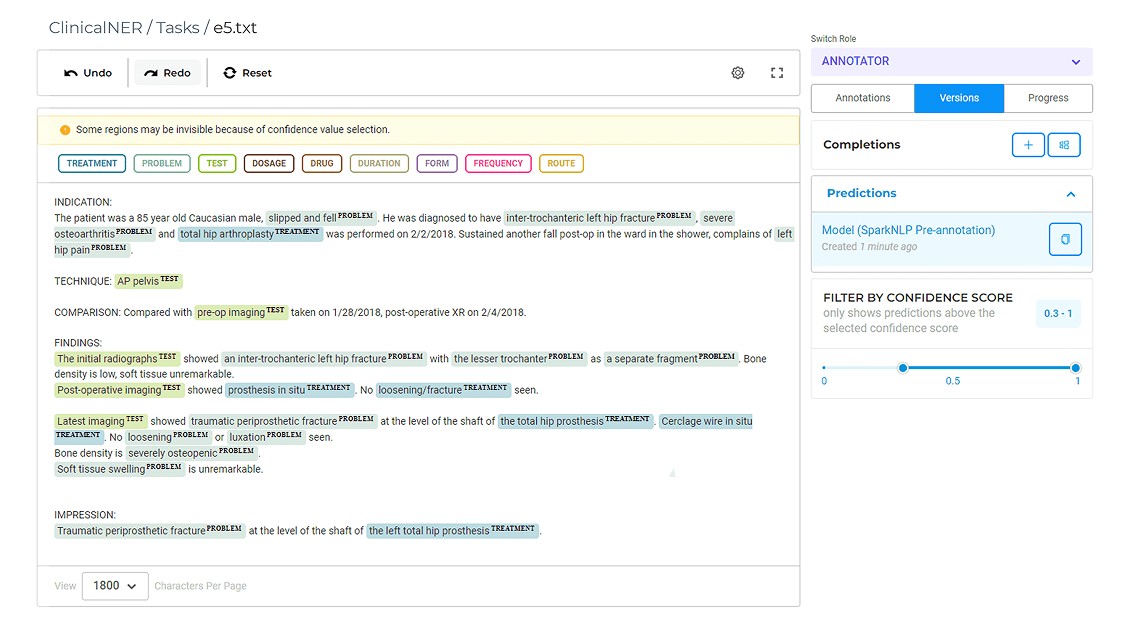
Eliminate manual spreadsheets and annotate thousands of documents daily with built-in Quality Assurance.
Speed up annotation without compromising quality — whether you’re labeling medical records, coding diagnoses, or preparing training data.
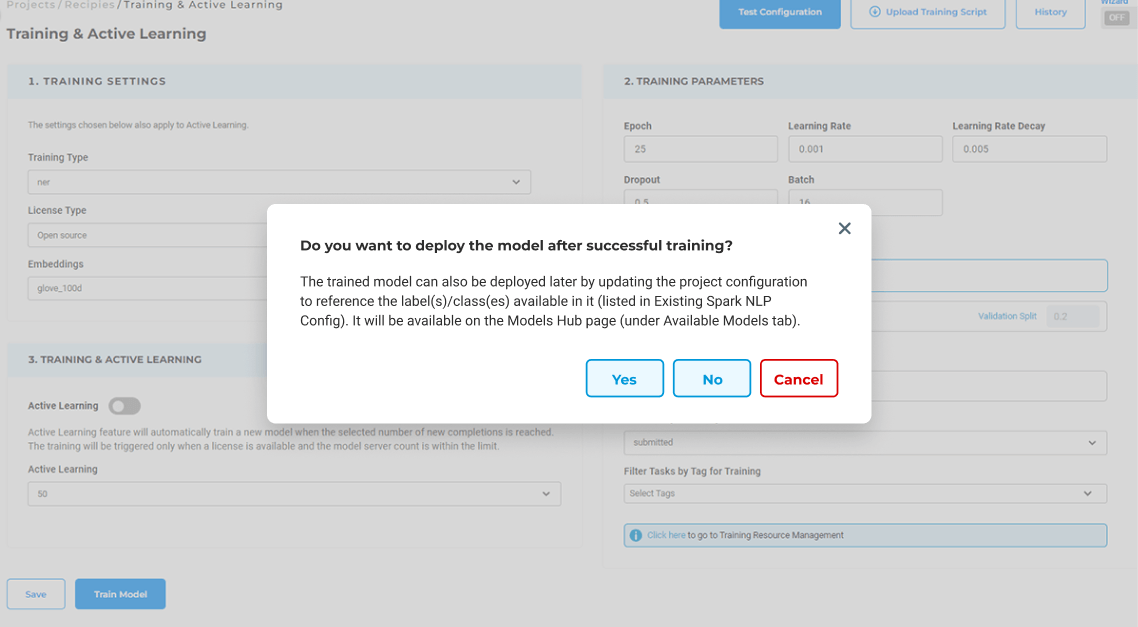
Fine-tune models based on domain-specific data — no ML engineering required.
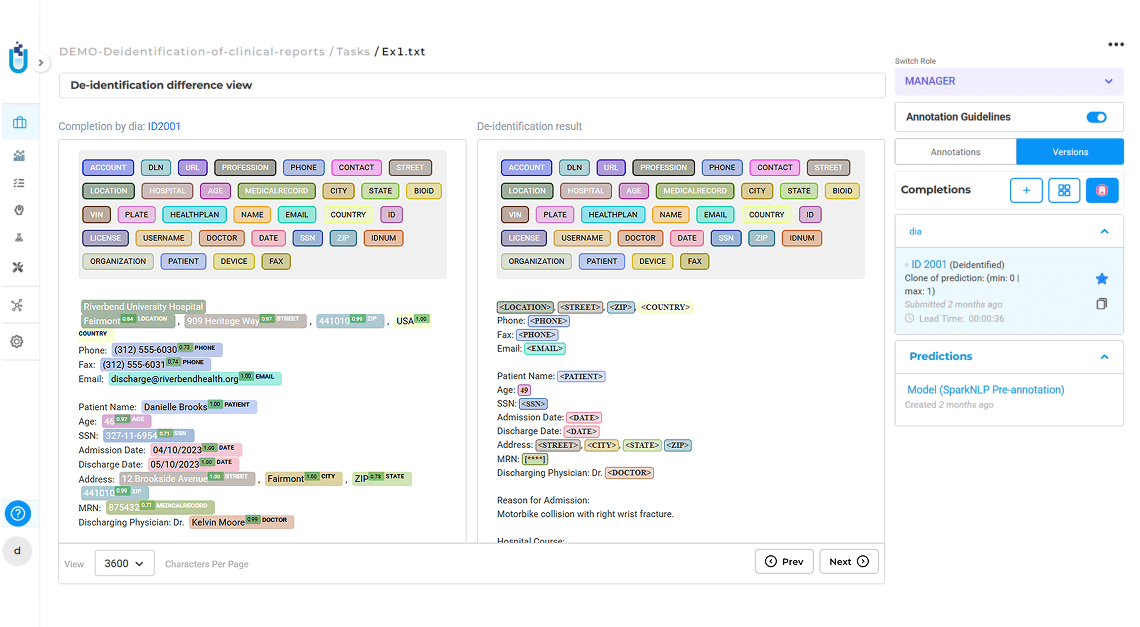
Remove PHI from medical records by combining automated detection with expert review to meet regulatory standards.
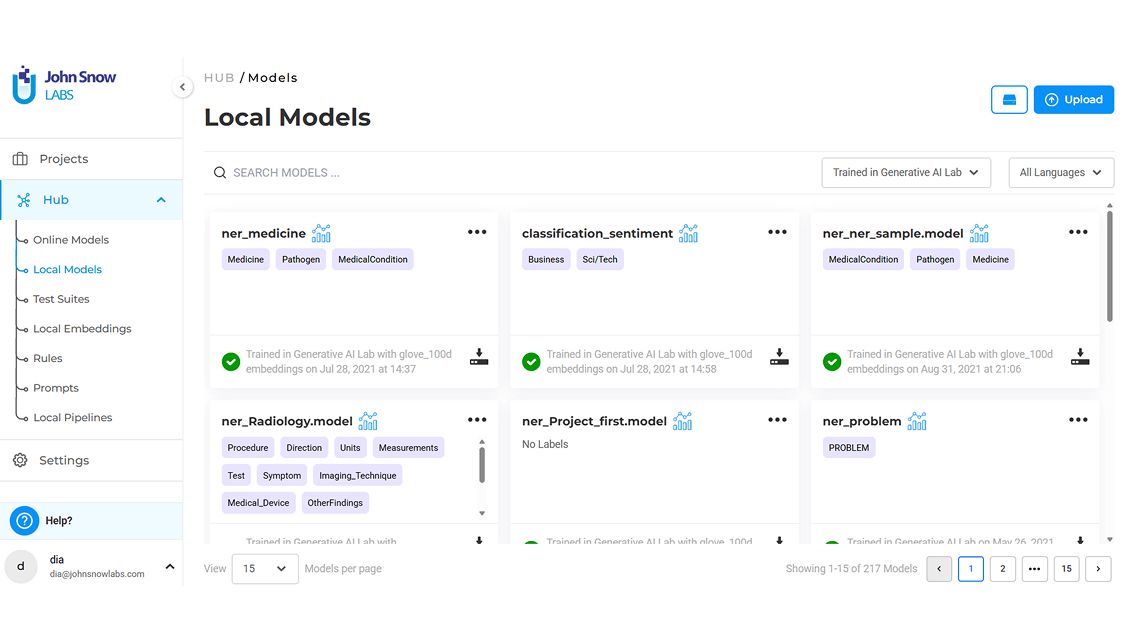
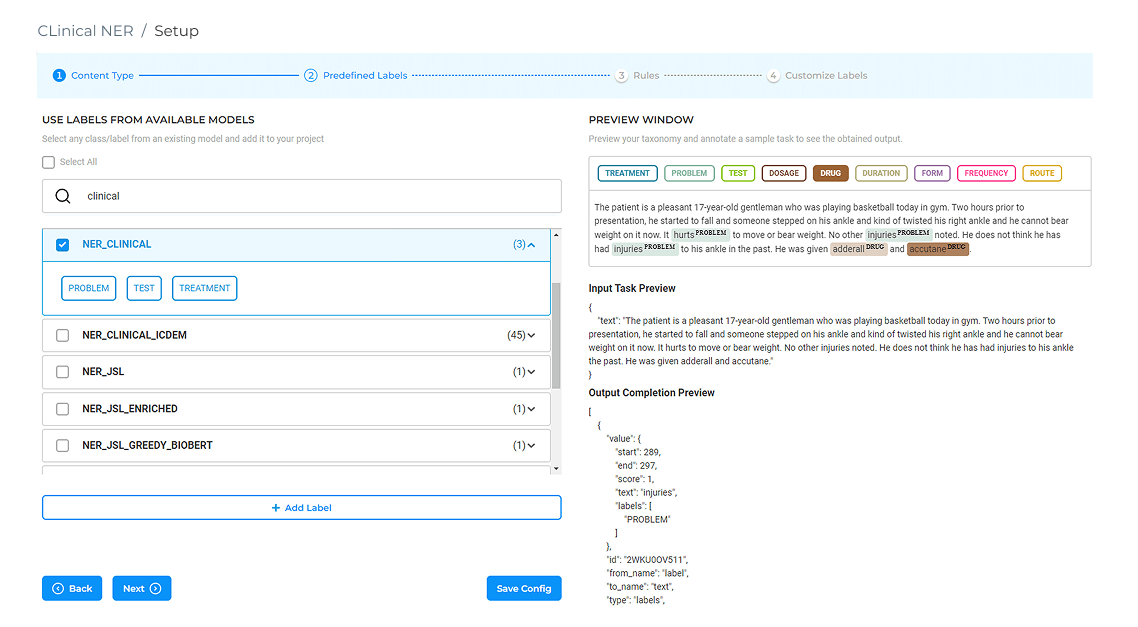
Access ready-to-go NLP models and pipelines to reduce time-to-deploy.
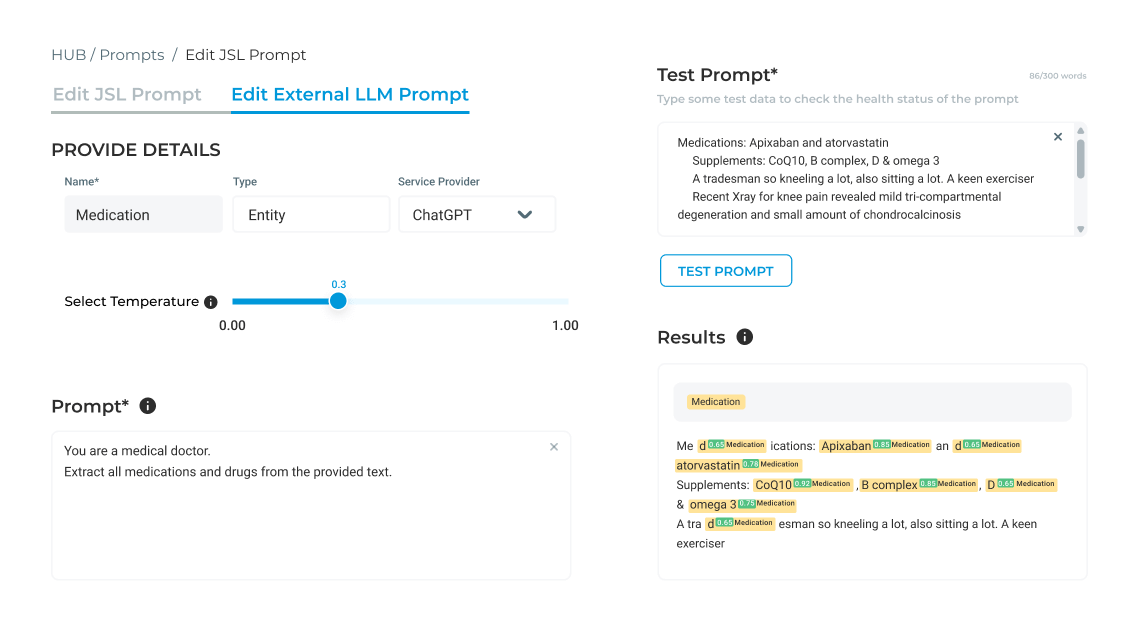
Use LLMs to experiment and prepare training examples for classification, NER, or relation detection. Includes:
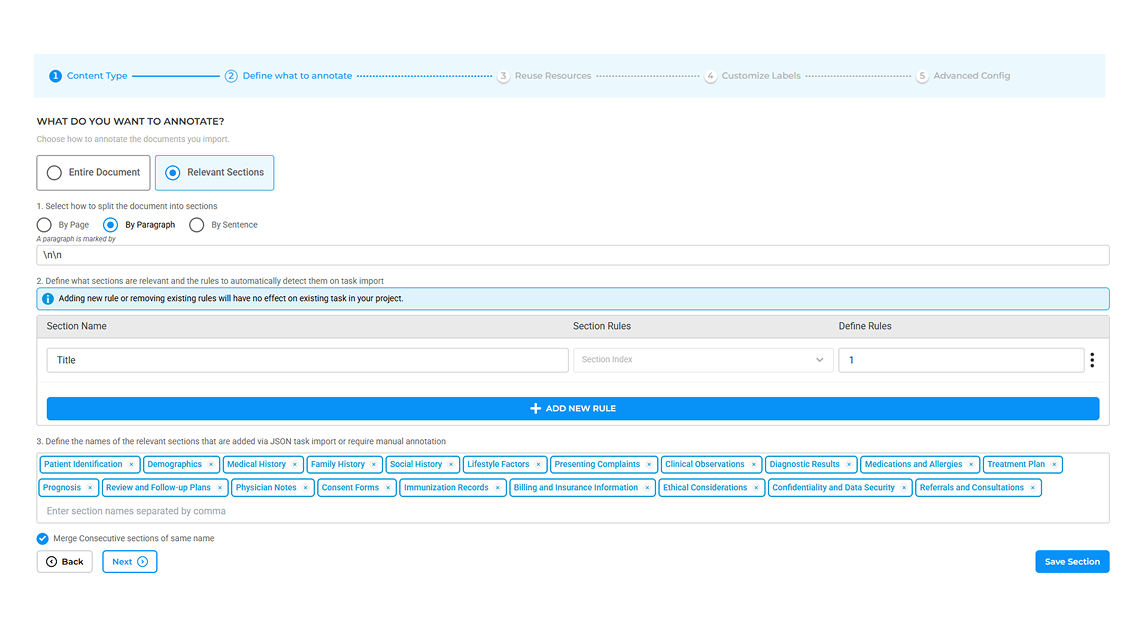
Focus on the sections you need to analyze and ignore the noise in your long documents.
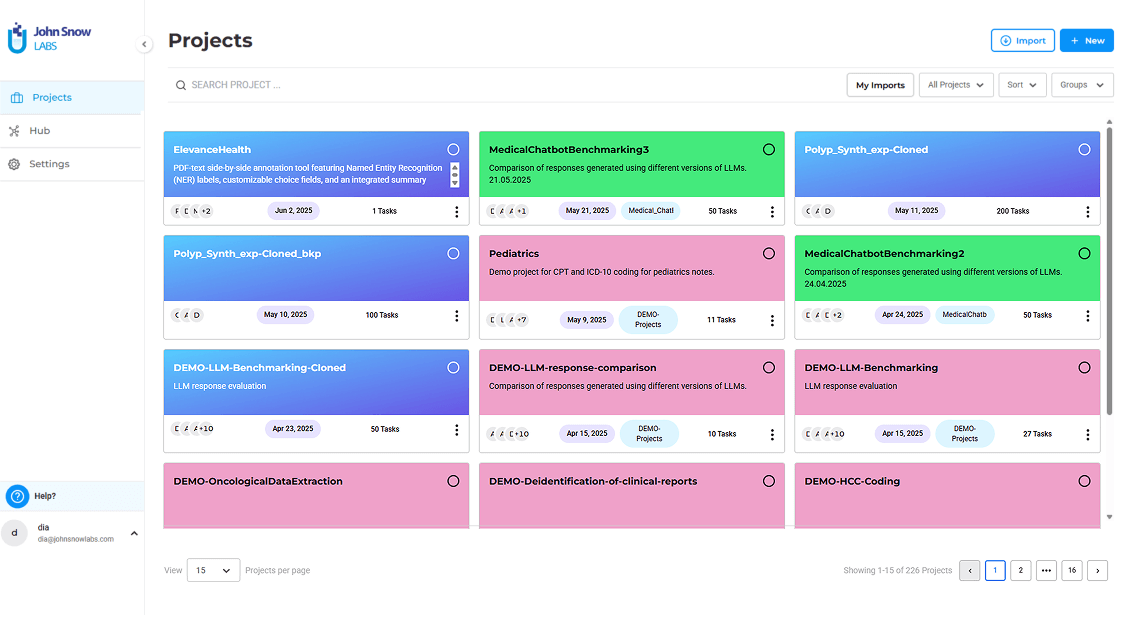
Support complex workflows with transparency and auditability.
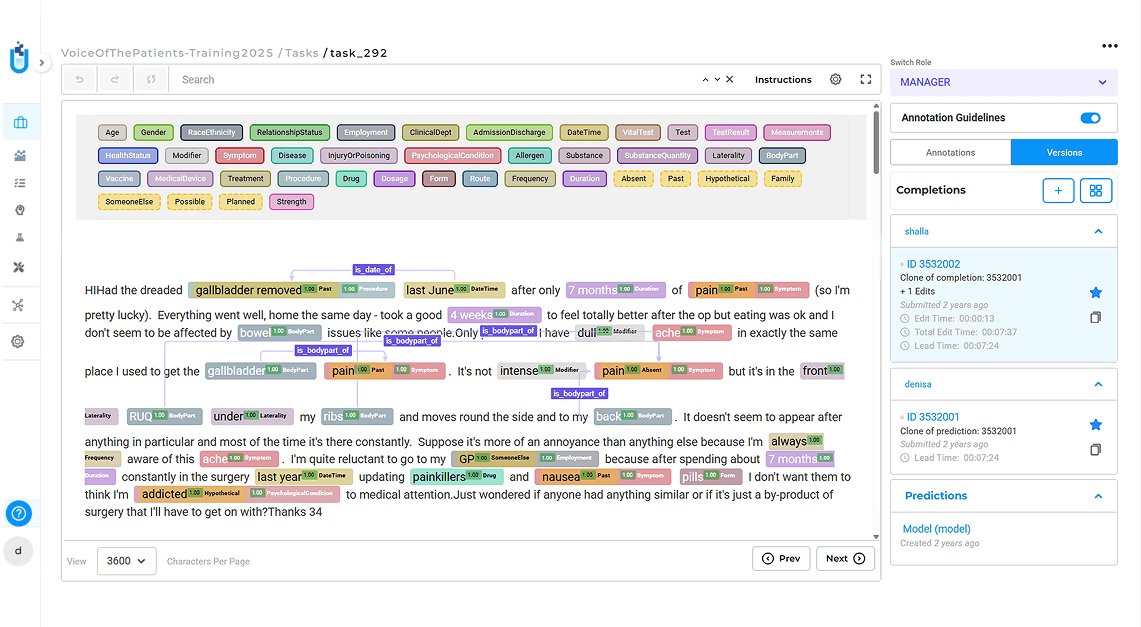
Support complex workflows with transparency and auditability.
Trusted by healthcare, finance, and legal organizations.
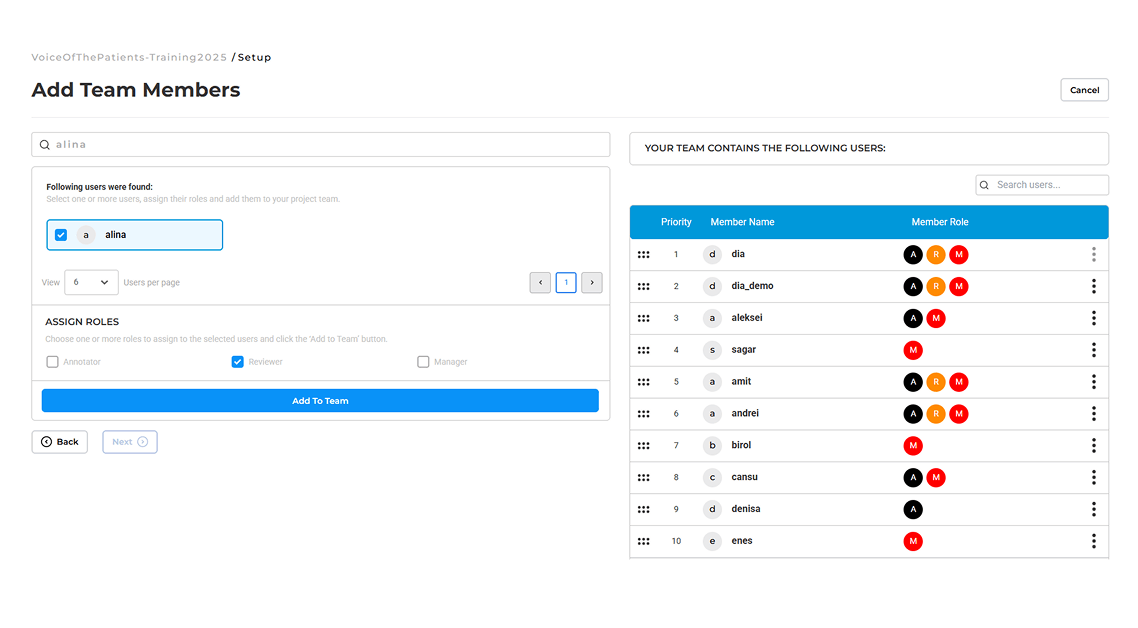
Automatically extract insights from clinical notes, unstructured EHR data, medical literature, and patient documentation.

Convert scanned medical reports, lab results, discharge summaries, or research papers into structured, actionable data.
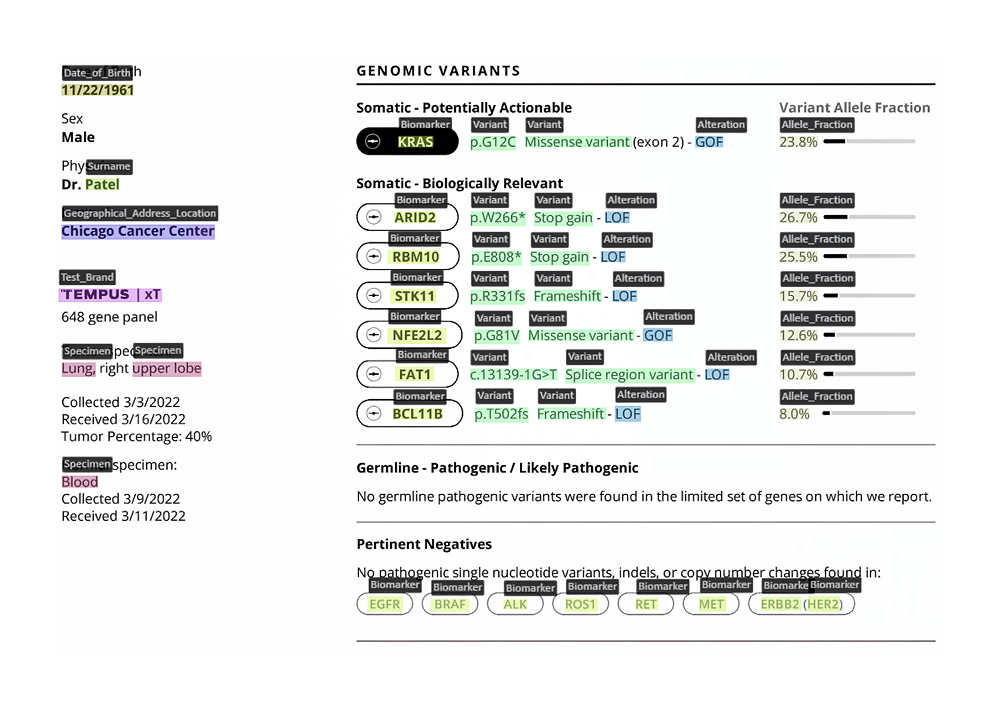
Annotate medical imaging like X-rays, MRIs, CT scans, and pathology slides for diagnostic support.
Label entities on HTML content, rate, and compare LLM responses saved as HTML with references and links.

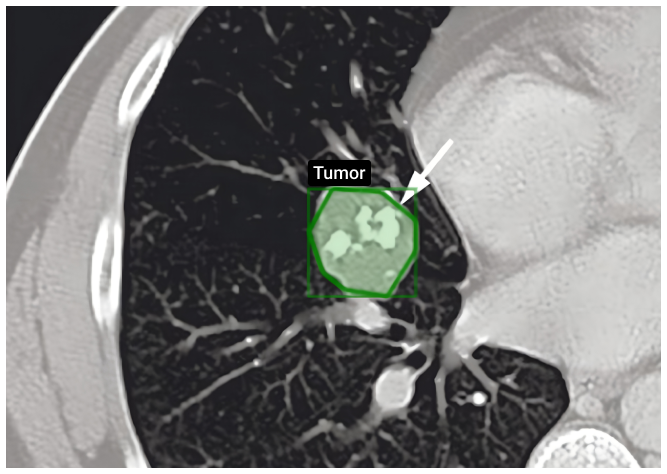
Transcribe doctor-patient conversations, medical dictation, and telemedicine consultations into text.
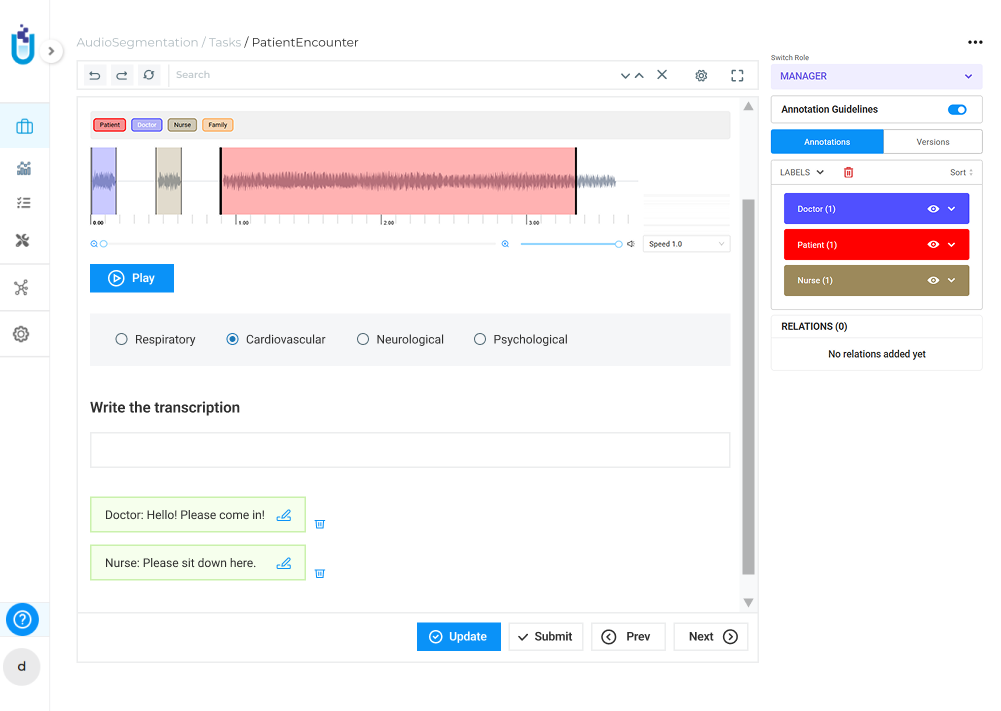
Analyze surgical procedures, patient examinations, and medical training videos for clinical insights.
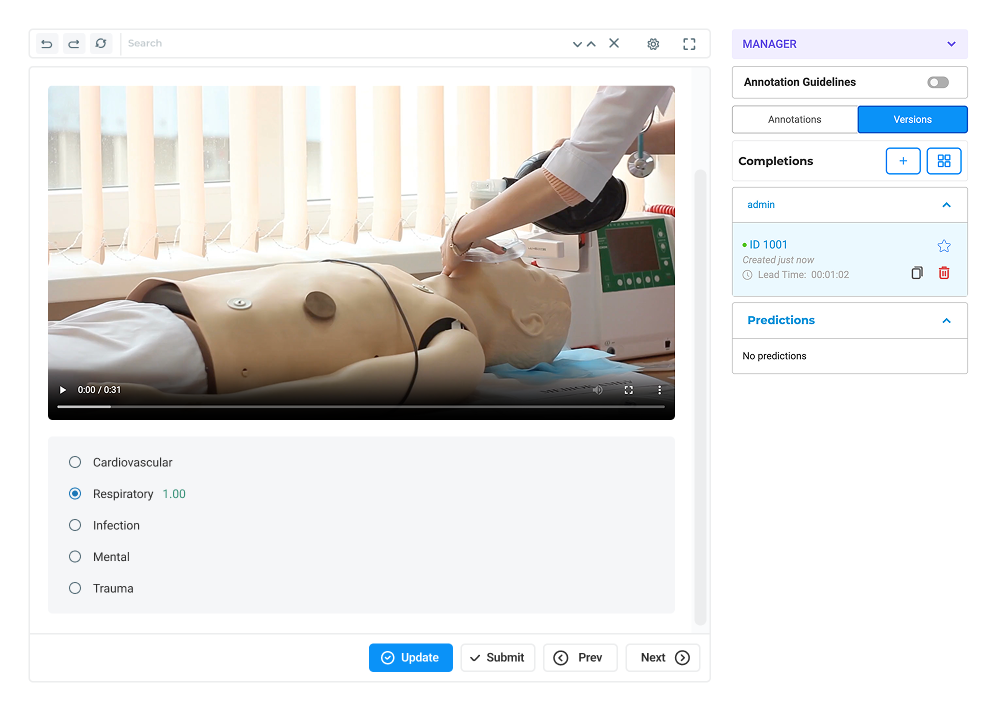
Achieve high data accuracy through rigorous Human-in-the-Loop validation
Learn MoreDeploy HIPAA-compliant software that analyzes your data in isolation
Install SoftwarePrecise control over data access and user permissions with full audit trail
See How It WorksRobust encryption & real-time events monitoring dashboards
Consult an ExpertEnhance your team’s AI proficiency with hands-on expertise in text annotation, Spark NLP, and healthcare-specific NLP through live workshops and certification exams, tailored to your preferred track





Generative AI Lab supports HIPAA compliance with air-gapped or on-premise deployments, zero data sharing, full audit trails, and Human-in-the-Loop (HITL) workflows for expert validation. It offers enterprise-grade security with role-based access control, multi-factor authentication (MFA), tamper-proof audit logs, and identity provider integration, ensuring data privacy for healthcare, legal, and finance sectors.
Yes, Generative AI Lab supports annotation of sensitive and proprietary data in air-gapped or on-premise deployments, ensuring zero data sharing with John Snow Labs or third parties.
The platform ensures accuracy and reliability through Human-in-the-Loop (HITL) workflows with expert oversight, pre-trained models, quality checks, and full audit trails, delivering consistent outcomes for healthcare and research tasks.
Generative AI Lab eliminates the need for data science expertise to deploy, test, train, and tune AI models through its no-code interface. The platform provides immediate access through subscription-based configuration without requiring custom development or IT infrastructure setup.
Cost optimization is achieved through two pricing models: pay-as-you-go billing that charges only for active feature usage and duration, and on-premise deployment options designed for enterprise teams requiring continuous annotation workflows.
The platform's Kubernetes-based auto-scaling architecture automatically adjusts computational resources based on demand, supporting concurrent multi-user access and processing high numbers of documents per day while maintaining consistent performance metrics across varying workloads.
The platform provides a high-productivity UI with keyboard shortcuts, pre-annotations, and AI-assisted labelling, plus a QuickStart guide and video tutorials for immediate use.
Generative AI Lab is offered as a pay-as-you-go solution on cloud marketplaces. The software subscription includes:
No. There is no limitation imposed on the number of projects, users, or documents that can be annotated within the Generative AI Lab. No limitation on the number of models, prompts or rules you can define, test, train or tune with the Generative AI Lab.
Also, there is no limitation on the number of pre-annotations you run or on the number of models you can train.
No, installation through the marketplaces will generate a cost, and using an on-premise deployment will require a license key. Contact us at support@johnsnowlabs.com for on-premise deployments.
Installation instructions are available here: https://nlp.johnsnowlabs.com/docs/en/alab/install
Yes. The Generative AI Lab will replace the NLP Lab products on the AWS and Azure Marketplaces. You can continue to use your existing subscription until the end of 2024, when we will end support for these products in these marketplaces.
We currently offer the product on AWS Marketplace and Azure Marketplace.
Yes. The Generative AI Lab can be used in high-compliance industries like healthcare, life science, finance, and insurance where on-premise deployments are common.
Most single-machine, and Kubernetes distributions are supported.
Yes. Make sure to allocate enough memory & compute power for your use case.
This depends heavily on your use case. The minimal required configuration for on-premise deployments is an 8-Core CPU, 32GB RAM of memory, and 512 GB of SSD storage.
The recommended configuration to support model training and AI-assisted pre-annotations for a team building or validating text models is a 16-Core CPU, 64 GB of memory, and 512 GB of SSD storage. The recommended configuration for teams using Document Understanding features and Visual model training is a 4-GPU instance with 48 CPU cores and 192 GB RAM, equivalent to g4dn.12xlarge AWS instances.
The software price is calculated based on usage and on the type of server where it is deployed.
Usage of Visual Document Understanding and of Healthcare features are charged based on consumption per vCPU per hour.
Charges are reflected on your AWS or Azure bill, and billed through your cloud provider.
Yes! Please email us to describe your situation and needs.
No. The software is designed to be installed and operated entirely within your own infrastructure. It is built with privacy and data sovereignty in mind, ensuring that it does not transmit any data or results outside of your controlled environment.
This architecture guarantees that your data remains within your jurisdiction, providing you with full control over its security and privacy.
You do. We will never even see them.
Our software is engineered specifically for environments that require strict compliance and robust security measures. It operates directly within your infrastructure, ensuring that all data processing occurs locally.
This means your data, including any Protected Health Information (PHI) or Personally Identifiable Information (PII), remains within your control at all times and is never sent to John Snow Labs.
We also provide the option to integrate with third-party Large Language Model (LLM) services, such as OpenAI, to leverage features like prompt-based pre-annotation and synthetic data generation. Should you decide to utilize these functionalities, the responsibility for implementing appropriate safeguards to securely and privately share PHI data with these external services rests with you.
It is crucial to ensure that any data sharing complies with your organization's privacy policies and relevant regulatory requirements to maintain the confidentiality and integrity of sensitive information.
Generative AI Lab does necessitate an active Internet connection for its operation. This requirement serves two primary purposes:
We understand the importance of consistent and reliable access to these resources and functionalities, and an Internet connection ensures that Generative AI Lab can deliver its full capabilities to enhance your projects.
Same business day 8x5 support is included with all subscriptions. We can also provide 24x7 support for production systems - please email us if you require it.
