
























































De-identified Health Information to Improve Patient Care
Modern-day wise folks say that “data is the new oil”. Data supports cutting-edge research, drives innovation, and helps with the development of solutions to real-world problems. This is especially true in the healthcare sector.
The right type, amount, and quality of data provide healthcare practitioners with critical insights about patients. Data also allows them to communicate effectively with patients, speed up diagnoses, and deliver better and more efficient care. Medical and health researchers also leverage data to develop new medicines, treatments, and vaccinations, identify disease risk factors, prevent or address epidemics, and disseminate knowledge to improve public health and extend human longevity.
However, using this data can compromise the privacy of individuals to whom it belongs. Over the past few decades, laws like HIPAA have evolved to protect the privacy of individuals in the U.S. Other countries have also developed their own data privacy laws, including Canada, Australia, and the EU (GDPR).
Healthcare organizations, professionals, and researchers in all these countries must comply with these regulations to prove that they take patient data privacy seriously and to avoid the financial and legal repercussions of non-compliance. To achieve compliance, they remove patients’ medical data, i.e., patients Protected Health Information (PHI). De-identification is also a requirement for organizations looking to train their machine learning models to analyze or process patient-level data for research or other purposes.
However, de-identification can be a challenging task. This article explores some of these challenges and explains how to get de-identified health information and how the healthcare data de-identification software from John Snow Labs helps eliminate them.
Before we get into these details, let’s start with the basics.

What is Deidentified Patient Data and Why is it Required?
De-identification involves removing Personally Identifiable Data (PII) and Protected Health Information (PHI) from the data. Removing personal identifiers from health information helps mitigate privacy risks to patients. It also enables HIPAA-covered healthcare organizations, researchers, etc., to safely use de-identified health information (patient data) for comparative effectiveness studies, medical research studies, life sciences research, policy assessments, and other endeavors. De-identification also enables these entities to share data with each other without violating the privacy of patients.
Finally, de-identifying data before further processing eliminates the need for entities to get authorization from each patient. This reduces their administrative burden while ensuring that they have the data they need for their use cases.
In the U.S., the de-identification of PHI is a requirement under the Privacy Rule of the Health Insurance Portability and Accountability Act (HIPAA de-identification rules). The privacy laws of many other countries, including Canada, Australia, and EU nations, also mandate the PHI de-identification prior to its processing, analysis, or sharing.
PHI De-identification under HIPAA
The de-identification of medical data is expressly governed under HIPAA. HIPAA’s Privacy Rule states that health information is not individually identifiable – i.e., it is adequately de-identified – if it doesn’t identify an individual, and if the covered entity does not believe that the data can be used to identify an individual.
HIPAA names two methods to de-identify data under the Privacy Rule: Safe Harbor and Expert Determination.
Safe Harbor PHI Deidentification method
The Safe Harbor de-identification method requires removing 18 types of identifiers so that health information cannot be used to identify individuals. These identifiers include:
- Names
- Geographic data, such as a street address, city, and ZIP code
- Dates directly related to an individual, such as birth date, discharge date, death date, etc.
- Telephone numbers
- Email addresses
- Social security numbers
- Medical record numbers
- Biometric identifiers, including fingerprints and voiceprints
- Full-face photographs
- Health plan beneficiary numbers
All these patient identifiers can help identify individuals from their data. Such identification violates the privacy requirements under HIPAA rules, which limit the use and disclosure of this data. Data de-identification is required to detect and mask such information.
At the same time, healthcare data de-identification usually leads to information loss, which may limit the usefulness of the resulting health information for further processing or analyses.
Expert Determination
This method of obtaining deidentified patient data involves applying statistical principles to data so that the risk of re-identifying an individual from this data is “very small”. These principles must be suggested by a knowledgeable and experienced statistical expert. Moreover, the risk of re-identification must remain small whether the information is used alone, or combined with other information.
Under this method, the de-identification process can be tailored to a specific use case. It also maximizes the utility and usefulness of de-identified data and is, therefore, more flexible than the Safe Harbor method. It also lowers re-identification risk compared to Safe Harbor which can be either overly restrictive or overly permissive. However, Safe Harbor has the advantage of low cost and simplicity over Expert Determination.
The Challenges of Healthcare Data De-identification
Traditionally, healthcare organizations and researchers used manual methods to de-identify patient data and prepare it for further processing and analytics. This involved hiring a team of individuals who would review each document page-by-page and line-by-line. They would then look for any PHI that could identify an individual, such as their first and last name, address, telephone numbers, etc. Finally, they would manually remove PHI from the de-identified health information.
The problem with this approach is that it relies on the human eye and human attention to detail. Since humans are fallible, the reviewer may miss one or more PHI identifiers, and mistakenly approve a document as de-identified and suitable for further processing and analytics by machine learning models. This not only creates privacy risks for individuals but also increases the risk of non-compliance with HIPAA and other laws. The latter can create serious legal and financial issues for the offending organization.
Another challenge with manual healthcare data de-identification is its slow speed. The healthcare industry in the U.S. produced 1.2 billion clinical documents in 2015. This number has surely increased in the 6 years since. Every healthcare organization deals with hundreds of thousands, if not millions, of clinical documents every year. And more such documents are created every single day. It’s impossible to quickly review and de-identify all the data in these documents for research, effectiveness studies, policy assessments, and other use cases.
John Snow Labs’ turnkey, fully customizable, end-to-end healthcare data de-identification software effectively addresses these challenges with the power of Natural Language Processing (NLP).
John Snow Labs Full-service of Data De-identification Tools
De-identified Health Information with Spark NLP
John Snow Labs’ healthcare data de-identification service leverages NLP to automatically get de-identified patient data from various data sources. It leverages world-class Spark NLP for Healthcare software to eliminate the need for manual de-identification.
Spark NLP for Healthcare is an award-winning NLP that makes it easy to de-identify medical data with award-winning, publicly–benchmarked models. Spark NLP offers state-of-the-art (SOTA) accuracy for de-identification models backed by peer-reviewed academic publications.
The Spark NLP library is the most popular and widely-used Python NLP library in the industry. In addition to data de-identification, it supports many other NLP use cases in healthcare, including clinical entity recognition, clinical entity linking, relation extraction, and assertion status.
Benefits of John Snow Labs Health Data De-identification Service
John Snow Labs provides these benefits for getting reliable de-identified data:
- Uses state of the art accurate software
- Fully end to end, including risk analysis, process setup, and operational support
- Can maintain linkage of clinical data across multiple files
- Able to work with structured and unstructured text, images, and DICOM files
- Secure, compliant solution installed on customer premises with no need for internet access
- Maintains the crucial linkage of clinical data across multiple files
- Ensures compliance with HIPAA, GDPR, and other regulations
For every organization, John Snow Labs runs the data de-identification service on-premise, in the customer’s own IT environment. The John Snow Labs team accesses the data running on the customer’s environment via secure channels to ensure that the data, the organization, as well as patients, are protected at all times.
Real-world Use Case
Providence St. Joseph’s Hospital (PSJH) de-identified 700 million patient notes with Spark NLP. They were able to accurately capture more than 99.1% of PHI to de-identify these documents. They also de-identified 100K patient notes in just over 43 minutes and 500K notes in just over 2 hours.
By using John Snow Labs Spark NLP for Healthcare, PSJH successfully addressed many key de-identification challenges, such as how to:
- De-identify 87 PHI-rich tables, each with over a billion rows of free-text and other unstructured data, daily and on a set schedule
- Maintain referential integrity across all 87 tables
- Share PHI-rich data with researchers and other third parties
- Encrypt patient and encounter-level PHI columns
- Ensure that the de-identification methodology is HIPAA-compliant
PSJH evaluated John Snow Labs models based on accuracy and speed by randomly selecting 1,000 patient notes, de-identifying them with John Snow Labs technology, and using human experts to validate these de-identified notes. For over 34K sentences in these notes, there were 281 leaked PHI events, meaning PHI leaked into 0.81% of sentences.
The service is scalable for any number of documents and de-identification use cases. It also seamlessly integrates with existing tech stacks. All of these are huge advantages for Providence St. Joseph’s Hospital.
5-Step End-to-end White Glove Service
John Snow Labs end-to-end white-glove service is offered as a complete package. This means that it incorporates multiple offerings to streamline the data de-identification process. Its 5-step process takes care of every aspect of data de-identification, right from needs analysis and legal requirements review, to quality assurance, operational support, model improvement, audits, and more.
Here’s how these 5 steps work:
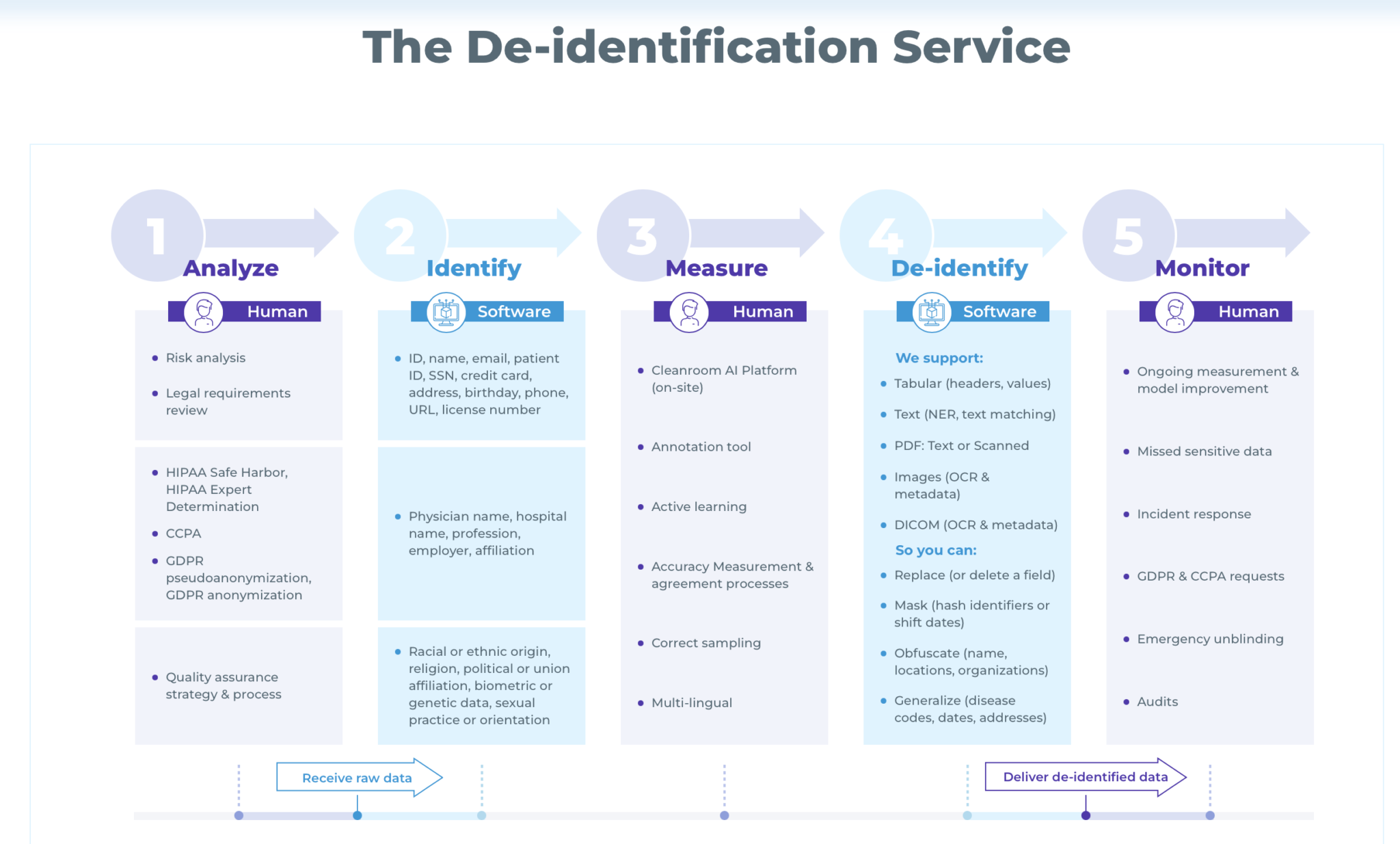
1. Analyze
The John Snow Labs team works closely with the healthcare organization to review their overall setup, infrastructure, and data de-identification requirements. They also perform a legal risk review to understand the governing law requirements (HIPAA, CCPA, GDPR, etc.). In case of HIPAA, they determine which de-identification method should be selected: Safe Harbor or Expert Determination.
Finally, the team:
- Performs data risk analysis to understand the data’s purpose and use case
- Understands what kind of information is to be de-identified: names, telephone numbers, email addresses, racial or ethnic origin, etc.
- Determines how to remove identifiers from PHI
- Determines how the output should be presented – if de-identified data is to be replaced, say, by adding random names from a directory, replaced by a placeholder or simply blanked out.
2. Identify
After the “human” step 1, step 2 involves the use of the software. This is where code and pipelines are written in Spark NLP to remove the identifiers determined in Step 1.
3. Measure
This is once again a human step, where the JSL team verifies and measures performance and accuracy on a data sample. They also execute agreed processes, setup sampling, and install the Cleanroom AI platform onsite in the customer’s environment.
Depending on the results of this step, the team adjusts the de-identification pipelines created in Step 2 if required. If accuracy and performance meet required levels, the process moves into the de-identify stage.
4. De-identify
In this software-driven stage, the John Snow Labs team runs the de-identification pipeline. This pipeline is extremely sophisticated to accommodate complex unstructured text and eliminate the need for manual de-identification processes – which are both time-consuming and error-prone.
Spark NLP supports numerous types of unstructured text for de-identification, including
-
- Structured tables and datasets
- Free text documents
- DICOM (Digital Imaging and Communications in Medicine) documents
- Scanned PDFs
- Medical imaging data
- Pathology images, and more
At the end of this stage the PHIs can be:
- Delete or replaced from the text
- Obfuscate names, locations, organizations, etc.
- Generalize disease codes, dates, and addresses
5. Monitor
John Snow Labs de-identification service does not stop with data de-identification. It also includes ongoing operational support and performance measurements to maintain the quality, consistency, and reliability of the de-identified output.
The John Snow Labs team coordinates with the customer’s team to:
- Improve NLP models
- Streamline incident response
- Manage GDPR and CCPA removal requests
- Perform data and process audits
The team also supports the healthcare entity with emergency unblinding. This may be required if the entity is running a clinical trial, and needs to notify specific individuals/study participants in case of an emergency that places them at some kind of health risk. This requires re-identifying patient data which can be done easily by the John Snow Labs team.
Conclusion: How to get Deidentified Patient Data
Data de-identification is a critical requirement for healthcare organizations that need to analyze and process getting de-identified health information while maintaining compliance with HIPAA and other data privacy regulations.
John Snow Labs’ healthcare data de-identification service delivers state-of-the-art accuracy while de-identifying many kinds of structured medical data. The service is offered as a package, so the entity need not worry about any aspect of the de-identification process, whether it’s risk analysis, constructing de-identification pipelines, audits, or ongoing monitoring.
To know more about this world-class NLP deidentification service and get accurate and reliable de-identified PHI, schedule a call with the John Snow Labs team today.




