Introduction
If you were a doctor consulting with another doctor, you might naturally say, “I had a case like that three years ago, and here’s what I did.” You wouldn’t say the patient’s name, address, etc.
The human brain is an essential tool to de-identify data so others in the organization can not have access to it. Some example use cases of de-identified health information are:
- Analysis of patient-level records for a public health sector
- Analysis of patient level records for adverse drug reactions in the post-marketing phase
- Prediction of short and long-term resource demand of a hospital department from emergency meeting room notes
- Tracking medications prescribed in a specific region to get public-health early warnings
- Tracking a company’s health plan performance in various areas
Before we delve into the details of Data De-identification, let’s first understand what de-identification is and what is de-identified under HIPAA data.
What is Data De-identification under HIPAA?
De-identification is a general term for any process of removing the association between a set of identifying data and the data subject. It consists of algorithms and processes that can be applied to documents, records, and data to remove any information which can lead to the identification of the person the document is concerned with. It protects the privacy of the individuals when addressed by people who should not know the person’s identity.
Traditionally, de-identification is performed by manually redacting personal information from the documents. However, the manual method is surprisingly inaccurate and prohibitively expensive for large data sets [link to the latest post].
Lately, methods based on natural language processing (NLP) methods have emerged, enabling high-quality de-identification for large data sets.
De-identification is critical for companies and government agencies seeking to make data available for further processing within the organization or outside. For instance, significant medical research can be done for social benefit by sharing de-identified patient information under the framework established by HIPAA (Health Insurance Portability and Accountability Act) Privacy rule. The HIPAA De-identification Privacy Rules set national standards for protecting medical records and other personal health information.
We can simplify de-identification as a method of removing PII (Personal Identifiable Information) and PHI (Protected Health Information) that the document stores. It can be used to accomplish the following objectives:
- Compliance with privacy regulations, e.g., HIPAA de-identification standard.
- Safeguarding the privacy of people interacting with the organizations
- Reducing risk and minimizing the damage caused to people from a data breach
- Building community trust in how companies and agencies store and handle data
Benefits of HIPAA-compliant Data De-identification
De-identification aims to safeguard the confidentiality of people. A document or record can’t be considered de-identified if it includes any personal data that allows the individual to be re-identified, i.e., personal identity can be inferred from the document. Data De-identification tools should preserve as much value in the information as possible and still protect people’s privacy. One of the key reasons to release de-identified data is to allow the study of raw data’s values and characteristics for research purposes without exposing any information about the individuals. For example, a healthcare organization can employ an agency to study the influence/outcomes of healthcare policy, like the expansion of care programs. The investigators can request access to data to conduct their study, but the healthcare organization has to de-identify the data before providing access to the records.
De-identification is an effective process that we can use to:
- Support leading-edge healthcare research with patient information without violating patient privacy.</li=>
- Share data within and among organizations to break down silos.
- Respond to access to information requests in a privacy-protective manner.
- Allow healthcare organizations to conduct research on patient habits during treatment
- Analysis of complex real-world data by Pharma companies
- De-identification allows researchers to provide public health warnings without revealing Protected Health Information.
Remember that data de-identification does not guarantee that the data is processed ethically and fairly. It is necessary to assess the impact of the processing to achieve that goal.
Do you know that de-identification has been particularly valuable in the medical field? It has led to discoveries and breakthroughs to improve patient care and is at the heart of the research.
Innovation partnerships leverage de-identified data and have the potential for advances in medical research. McKinsey estimates that applying big data strategies to health records could generate up to $100 billion in value annually across the US healthcare system.
Frequently Asked Questions
What is the difference between PI, PII, PHI, Data De-identification, and Data Anonymization?
Let’s look for the definition shared in the International Association of Privacy Professionals glossary:
- Personal Information – PI A synonym for “personal data.” It is a term with particular meaning under the California Consumer Privacy Act, which defines it as information that identifies, relates to, describes, is capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer. There is a particular meaning within the EU GDPR context: any information relating to an identified or identifiable natural person; an identifiable person is one who can be identified, directly or indirectly — in particular by reference to an identification number or to one or more factors specific to their physical, physiological, mental, economic, cultural or social identity.
- Personally Identifiable Information – PII Any information about an individual, including any information that can be used to distinguish or trace an individual’s identity, such as name, social security number, date and place of birth, mother’s maiden name, or biometric records; and any other information that is linkable to an individual, such as medical, educational, financial, and employment information.
- Protected Health Information – PHI Any individually identifiable health information transmitted or maintained in any form or medium that is held by an entity covered by the Health Insurance Portability and Accountability Act or its business associate; identifies the individual or offers a reasonable basis for identification; is created or received by a covered entity or an employer; and relates to a past, present or future physical or mental condition, provision of healthcare or payment for healthcare to that individual.
- De-identification: An action that one takes to remove identifying characteristics from data.
- Anonymization: The process in which individually identifiable data is altered in such a way that it no longer can be related back to a given individual. Among many techniques, there are three primary ways that data is anonymized. Suppression is the most basic version of anonymization and it simply removes some identifying values from data to reduce its identifiability. Generalization takes specific identifying values and makes them broader, such as changing a specific age (18) to an age range (18-24). Noise addition takes identifying values from a given data set and switches them with identifying values from another individual in that data set. Note that all of these processes will not guarantee that data is no longer identifiable and have to be performed in such a way that does not harm the usability of the data.
The interesting difference is between GDPR regulations and HIPAA:
- Anonymous information is defined as information that does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable. GDPR does regulate sharing of anonymous information.
- On the other hand, pseudonymized information could be attributed to a natural person by using additional information. It is considered personal information under GDPR.
For example: a document with names and SSNs is replaced with random strings, and the diagnosis is left unchanged. The mapping between names and random strings and SSN and random strings is kept private and secure. Under the HIPAA de-identification privacy rule, the table is considered de-identified, and sharing is permitted. Under GDPR regulations, the table is considered pseudonymized, and sharing is regulated unless the mapping is destroyed.
GDPR pseudonymization corresponds to NIST & HIPAA de-identification, while GDPR anonymization corresponds to NIST anonymization.
What are Direct and Indirect Identifiers?
There are two types of identifiers, i.e., direct and indirect.
Direct Identifiers
Information that relates specifically to an individual. HIPAA designates the following as direct identifiers: names; postal address information other than town or city, state, and zip code; phone numbers; fax numbers; email addresses; social security numbers; medical record numbers; health plan beneficiary numbers; account numbers; certificate/license numbers; vehicle identifiers and serial numbers including license plate numbers; device identifiers and serial numbers; URLs; IP addresses; biometric identifiers; and full face photographic images and any comparable images.
Indirect Identifiers
Information that can be combined with other information to potentially identify a specific individual. HIPAA designates the following as indirect identifiers: city, state, and zip codes; elements of dates; and other numbers, characteristics, or codes not HIPAA-designated as direct identifiers.
How can Researchers Use De-identified Data?
The de-identified data can be freely shared, within or outside the organization. However, the publicly shared data may have a higher risk of re-identification than, e.g., data analyzed only internally by employees trained for HIPAA compliance. Thus, the re-identification risk can differ for various intents for usage. When assessing the risk of re-identification, the expert may also consider the intended use of the data.
What is PII Data De-identification and Anonymization?
PII is defined in NIST SP 800-122 “Guide to Protecting the Confidentiality of Personally Identifiable Information (PII)”. The document regulates US Federal agencies. It may be used by nongovernmental organizations on a voluntary basis.
To distinguish an individual is to identify an individual. Some examples of information that could
identify an individual include, but are not limited to, name, passport number, social security number, or biometric data. In contrast, a list containing only credit scores without any additional information concerning the individuals to whom they relate does not provide sufficient information to distinguish a specific individual.
To trace an individual is to process sufficient information to make a determination about a specific aspect of an individual‘s activities or status. For example, an audit log containing records of user actions could be used to trace an individual‘s activities.
De-Identifying Information
Full data records are not always necessary, such as for some forms of research, resource planning, and examinations of correlations and trends. The term de-identified information is used to describe records that have had enough PII removed or obscured, also referred to as masked or obfuscated, such that the remaining information does not identify an individual and there is no reasonable basis to believe that the information can be used to identify an individual. De-identified information can be re-identified (rendered distinguishable) by using a code, algorithm, or pseudonym that is assigned to individual records. The code, algorithm, or pseudonym should not be derived from other related information about the individual, and the means of re-identification should only be known by authorized parties and not disclosed to anyone without the authority to re-identify records. A common de-identification technique for obscuring PII is to use a one-way cryptographic function, also known as a hash function, on the PII.
De-identified information can be assigned a PII confidentiality impact level of low, as long as the following are both true:
- The re-identification algorithm, code, or pseudonym is maintained in a separate system, with appropriate controls in place to prevent unauthorized access to the re-identification information.</li=>
- The data elements are not linkable, via public records or other reasonably available external records, in order to re-identify the data.
For example, de-identification could be accomplished by removing account numbers, names, SSNs, and any other identifiable information from a set of financial records. By de-identifying the information, a trend analysis team could perform an unbiased review of those records in the system without compromising the PII or providing the team with the ability to identify any individual. Another example is using health care test results in research analysis. All of the identifying PII fields can be removed, and the patient ID numbers can be obscured using pseudo-random data that is associated with a cross-reference table located in a separate system. The only means to reconstruct the original (complete) PII records is through authorized access to the cross-reference table.
Anonymizing Information
Anonymized information is defined as previously identifiable information that has been de-identified and for which a code or other association for re-identification no longer exists. Anonymizing information usually involves the application of statistical disclosure limitation techniques to ensure the data cannot be re-identified, such as:
- Generalizing the Data — Making information less precise, such as grouping continuous values
- Suppressing the Data — Deleting an entire record or certain parts of records
- Introducing Noise into the Data — Adding small amounts of variation into selected data
- Swapping the Data — Exchanging certain data fields of one record with the same data fields of another similar record (e.g., swapping the ZIP codes of two records)
- Replacing data with the Average Value — Replacing a selected value of data with the average value for the entire group of data.
Using these techniques, the information is no longer PII, but it can retain its useful and realistic properties.
How to Perform Data De-identification Under HIPAA?
There are two ways of de-identification under the HIPAA privacy rule. The safe harbor method lists 18 direct identifiers for removal and requires the subject not to know that the residual information can be used to identify the individual. The expert determination requires an expert in the field to conclude that the risk is small and document his analysis.
In particular, the de-identification is defined in § 164.514 “Other requirements relating to uses and disclosures of protected health information”: A covered entity may determine that health information is not individually identifiable health information only if:
Expert determination
- A person with appropriate knowledge of and experience with generally accepted statistical and scientific principles and methods for rendering information not individually identifiable:
- Applying such principles and methods determines that the risk is very small and that the information could be used, alone or in combination with other reasonably available information, by an anticipated recipient to identify an individual who is a subject of the information; and Documents the methods and results of the analysis that justify such determination; or
Safe Harbor
The following identifiers of the individual or of relatives, employers, or household members of the individual, are removed:
- Names;
- All geographic subdivisions smaller than a State, including street address, city, county, precinct, zip code, and their equivalent geocodes, except for the initial three digits of a zip code if, according to the current publicly available data from the Bureau of the Census:
- The geographic unit formed by combining all zip codes with the same three initial digits contains more than 20,000 people; and
- The initial three digits of a zip code for all such geographic units containing 20,000 or fewer people is changed to 000.
- All elements of dates (except year) for dates directly related to an individual, including birth date, admission date, discharge date, date of death; and all ages over 89 and all elements of dates (including year) indicative of such age, except that such ages and elements may be aggregated into a single category of age 90 or older;
- Telephone numbers;
- Fax numbers;
- Electronic mail addresses;
- Social security numbers;
- Medical record numbers;
- Health plan beneficiary numbers;
- Account numbers;
- Certificate/license numbers;
- Vehicle identifiers and serial numbers, including license plate numbers;
- Device identifiers and serial numbers;
- Web Universal Resource Locators (URLs);
- Internet Protocol (IP) address numbers;
- Biometric identifiers, including finger and voice prints;
- Full face photographic images and any comparable images; and
- Any other unique identifying number, characteristic, or code, except as permitted by paragraph (c) of this section; and
The covered entity does not have actual knowledge that the information could be used alone or in combination with other information to identify an individual who is a subject of the information.
There are also conditions to keep records for re-identification: A covered entity may assign a code or other means of record identification to allow information de-identified under this section to be re-identified by the covered entity, provided that:
- (Derivation.) The code or other means of record identification is not derived from or related to information about the individual and is not otherwise capable of being translated so as to identify the individual; and</lifont=>
- (Security.) The covered entity does not use or disclose the code or other means of record identification for any other purpose and does not disclose the mechanism for re-identification.
Putting it Altogether
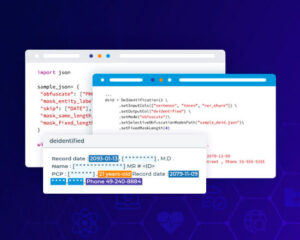
Do you know what the biggest benefit of de-identified data is? The benefit is that we can store de-identified data anywhere we want. The infrastructure that interacts with the data does not need to adhere to HIPAA. De-identification of HIPAA data can be an intricate and challenging process, but we can use some tools to ease our work. For example, the Healthcare Data De-identification tool automatically de-identifies structured and unstructured data, PDF files, images, and documents in compliance with HIPAA, GDPR, or custom needs. It is trusted by 5 of 8 top Pharma companies as its accuracy on real-world documents is greater than 99%.
Try this de-identification tool and see how it can be best applied to your use case.