How can AI governance be automated in healthcare applications of generative AI?
Automating AI governance in healthcare involves embedding bias detection, robustness checks, and compliance validation directly into the development lifecycle of generative AI systems. This ensures that healthcare-focused models are reliable, fair, and fit for purpose. The presentation by Ben Webster and David Talby outlines a hands-on framework using LangTest, a tool designed to validate the quality, safety, and compliance of AI models tailored for healthcare.
What healthcare scenario highlights the need for automated governance?
A healthcare organization managing 1.5 million annual audio feedback files provides a clear example. These recordings, sourced from diverse hospitals, are transcribed and analyzed for sentiment and topic modeling. The AI system parses each comment, identifies clauses, and groups them into “thought units” for assigning sentiment and topics. These outputs are critical for triaging urgent cases and routing feedback appropriately.
Errors in topic identification or sentiment attribution can lead to inappropriate actions. For example, failing to detect negative sentiment in a serious complaint may delay critical interventions. Biases such as gendered name associations or title-based assumptions (e.g., doctor vs nurse) can further distort sentiment analysis. Automated governance ensures these risks are systematically identified and addressed.
How does LangTest help mitigate bias and improve robustness?
LangTest provides synthetic testing, data augmentation, and bias-mitigation capabilities. Developers can simulate scenarios by swapping names, changing titles, or adjusting linguistic variables to uncover hidden biases. By fine-tuning models with synthetic and real-world data permutations, teams can systematically de-bias models and validate robustness under diverse conditions.
LangTest also supports:
- Structured output validation (e.g., JSON responses)
- Automatic data augmentation for increasing robustness and de-biasing LLMs
- Testing for healthcare-specific hallucinations, bias and other errors
These features make LangTest suitable for custom healthcare AI workflows, where general-purpose benchmarks fall short.
What standards and tools support transparent model evaluation?
Transparency in AI requires meaningful documentation and standardized evaluation. Model cards, such as those developed by the Coalition for Health AI, function as “nutrition labels” for AI systems. They report performance metrics on accuracy, fairness, robustness, and safety, specifying where the model performs well and where caution is needed.
Generating trustworthy model cards demands customized, task-specific benchmarks. Off-the-shelf leaderboards often suffer from data contamination and overfitting. For instance, models trained on public internet data may memorize medical exam questions rather than demonstrating true reasoning capabilities. LangTest helps generate unique test sets, ensuring model evaluations reflect real-world performance.
What are the current gaps in AI governance for healthcare?
Four key gaps hinder effective AI governance in healthcare:
- Data Contamination: Pretrained LLMs may have seen benchmark questions during training, invalidating test results.
- Task Relevance: Most benchmarks don’t reflect actual clinical tasks, like summarizing radiology reports or generating patient instructions.
- Medical Red Teaming: There’s a lack of tools to test whether LLMs produce medically unethical or illegal advice under adversarial prompts.
- Cognitive Bias Detection: Clinical decision-making is prone to biases (e.g., anchoring, confirmation). These biases can also affect LLM outputs.
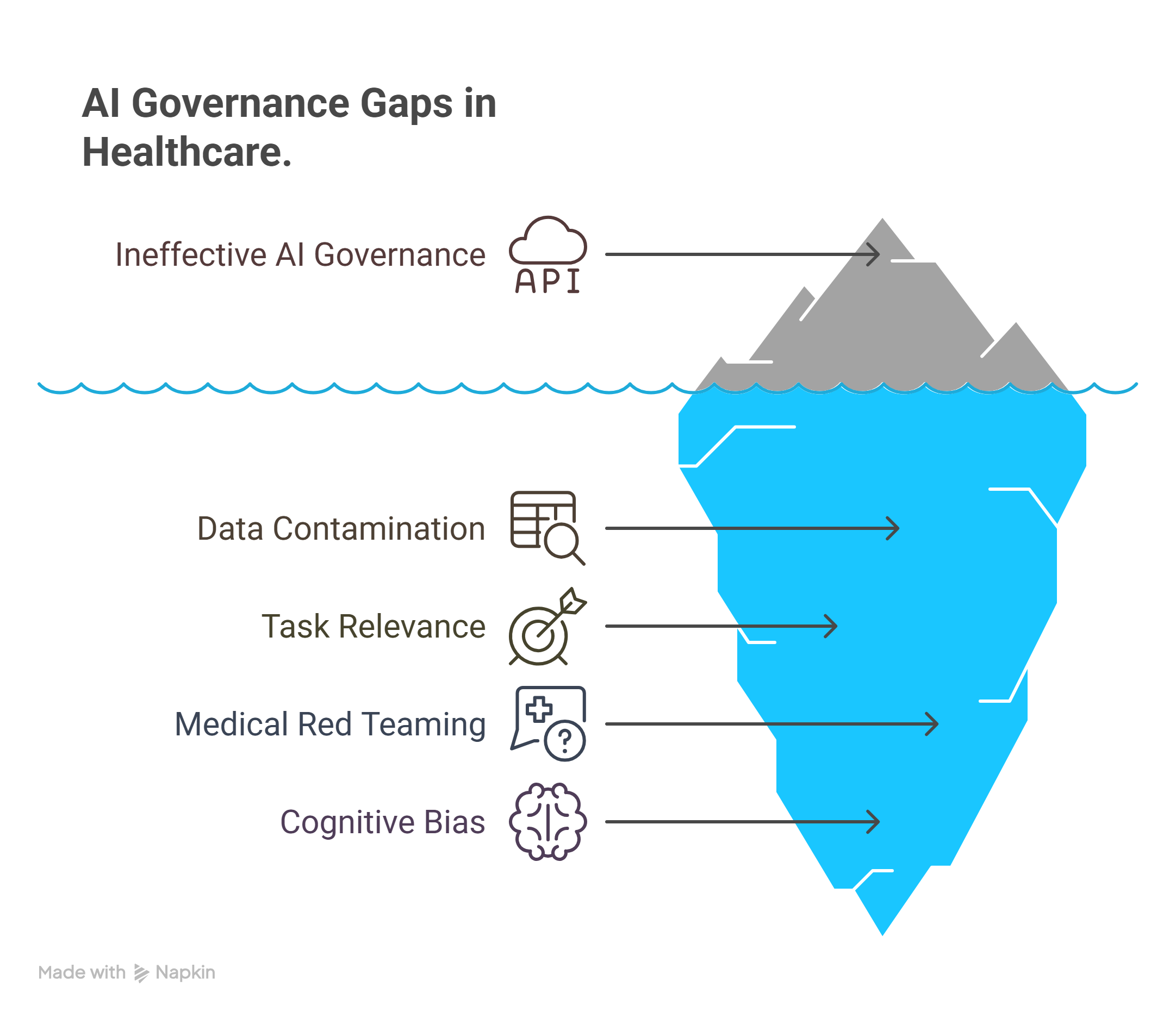
Addressing these issues requires more than generic tools. Organizations must build custom test suites that reflect their specific clinical use cases. This includes developing benchmarks inspired on more realistic patient data, such as those introduced by Stanford’s Med-HAULT initiative. Evaluating how models respond to ethical dilemmas and uncovering latent biases is crucial. Additionally, red-teaming simulations focused on medical safety, legality, and ethical boundaries are essential to ensure robust AI governance.
How does this approach support compliance and trust?
Healthcare AI systems must meet rigorous compliance standards. LangTest aids this by:
- Validating performance across demographic groups
- Detecting performance degradation from minor input variations
- Supporting red-teaming for ethical, legal, and safety risks
By incorporating governance directly into the development workflow, organizations can automate the generation of trustworthy model documentation. This enables safe deployment, transparent reporting, and alignment with regulatory frameworks.
Supplementary Q&A
What is LangTest, and how does it differ from general LLM benchmarks? LangTest is a customizable testing framework for evaluating AI models, particularly in regulated or high-stakes domains like healthcare. Unlike general benchmarks, it enables bias simulation, robustness testing, and structured output validation tailored to specific use cases.
How do medical red teaming benchmarks improve model safety? Medical red teaming tests an LLM’s response to unethical or illegal prompts, such as faking records or discriminatory advice. By simulating these risks, organizations can tune models to avoid harmful outputs and ensure compliance.
Why is data contamination a major issue for healthcare LLMs? Public LLMs often memorize benchmark data from training, leading to inflated performance claims. This undermines real-world reliability, especially in medicine, where minor wording changes can drastically affect outcomes.
How does automating governance support continuous model improvement? Automated governance frameworks like LangTest enable ongoing testing and validation as models evolve. This supports safe iteration, especially when introducing new features, themes, or patient cohorts.
What makes a model card meaningful versus marketing fluff? A meaningful model card includes real performance data, bias evaluations, and safety checks based on task-specific benchmarks. It communicates known strengths, limitations, and recommended usage conditions, helping users make informed decisions.
60+ Test Types for Comparing LLM & NLP Models on Accuracy, Bias, Fairness, Robustness & More
Learn more