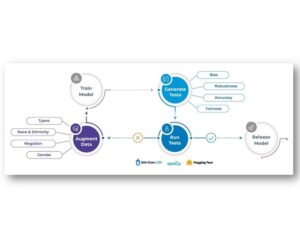
Automatically generate test cases, run tests, and augment training datasets with the open-source, easy-to-use, cross-library LangTest package
 If your goal is to deliver NLP systems for production systems, you are responsible to deliver models that are robust, safe, fair, unbiased, and private – in addition to being highly accurate. This requires having the tools & processes to test for these requiremenst in practice – as part of your day-to-day work, your team’s work, and on every new version of a model.
If your goal is to deliver NLP systems for production systems, you are responsible to deliver models that are robust, safe, fair, unbiased, and private – in addition to being highly accurate. This requires having the tools & processes to test for these requiremenst in practice – as part of your day-to-day work, your team’s work, and on every new version of a model.
The LangTest library is designed to help you do that, by providing comprehensive testing capabilities for both models and data. It allows you to easily generate, run, and customize tests to ensure your NLP systems are production-ready. With support for popular NLP libraries like transformers, Spark NLP, OpenAI, and spacy, LangTest is an extensible and flexible solution for any NLP project.
In this article, we’ll dive into three main tasks that the LangTest library helps you automate: Generating tests, running tests, and augmenting data.
Automatically Generate Tests
Unlike the testing libraries of the past, LangTest allows for the automatic generation of tests – to an extent. Each TestFactory can specify multiple test types and implement a test case generator and runner for each one.
The generated tests are presented as a table with ‘test case’ and ‘expected result’ columns that correspond to the specific test. These columns are designed to be easily understood by business analysts who can manually review, modify, add, or remove test cases as needed. For instance, consider the test cases generated by the RobustnessTestFactory for an NER task on the phrase “I live in Berlin.”:
| Test type | Test case | Expected result |
| remove_punctuation | I live in Berlin | Berlin: Location |
| lowercase | i live in berlin. | berlin: Location |
| add_typos | I liive in Berlin. | Berlin: Location |
| add_context | I live in Berlin. #citylife | Berlin: Location |
Starting from the text “John Smith is responsible”, the BiasTestFactory has generated test cases for a text classification task using US ethnicity-based name replacement.
| Test type | Test case | Expected result |
| replace_to_asian_name | Wang Li is responsible | positive_sentiment |
| replace_to_black_name | Darnell Johnson is responsible | negative_sentiment |
| replace_to_native_american_name | Dakota Begay is responsible | neutral_sentiment |
| replace_to_hispanic_name | Juan Moreno is responsible | negative_sentiment |
Generated by the FairnessTestFactory and RepresentationTestFactory classes, here are test cases that can ensure representation and fairness in the model’s evaluation. For instance, representation testing might require a test dataset with a minimum of 30 samples of male, female, and unspecified genders each. Meanwhile, fairness testing can set a minimum F1 score of 0.85 for the tested model when evaluated on data subsets with individuals from each of these gender categories.
| Test type | Test case | Expected result |
| min_gender_representation | Male | 30 |
| min_gender_representation | Female | 30 |
| min_gender_representation | Unknown | 30 |
| min_gender_f1_score | Male | 0.85 |
| min_gender_f1_score | Female | 0.85 |
| min_gender_f1_score | Unknown | 0.85 |
The following are important points to take note of regarding test cases:
- Each test type has its interpretation of “test case” and “expected result,” which should be human-readable. After calling h.generate(), it is possible to manually review the list of generated test cases and determine which ones to keep or modify.
- Given that the test table is a pandas data frame, it is editable within the notebook (with Qgrid) or exportable as a CSV file to allow business analysts to edit it in Excel.
- While automation handles 80% of the work, manual checks are necessary. For instance, a fake news detector’s test case may show a mismatch between the expected and actual prediction if it replaces “Paris is the Capital of France” with “Paris is the Capital of Sudan” using a
replace_to_lower_income_country - Tests must align with business requirements, and one must validate this. For instance, the
FairnessTestFactorydoes not test non-binary or other gender identities or mandate nearly equal accuracy across genders. However, the decisions made are clear, human-readable, and easy to modify. - Test types may produce only one test case or hundreds of them, depending on the configuration. Each TestFactory defines a set of parameters.
- By design, TestFactory classes are usually task, language, locale, and domain-specific, enabling simpler and more modular test factories.
Running Tests
To use the test cases that have been generated and edited, follow these steps:
- Execute
h.run()to run all the tests. For each test case in the test harness’s table, the corresponding TestFactory will be called to execute the test and return a flag indicating whether the test passed or failed, along with a descriptive message. - After calling
h.run(), callh.report(). This function will group the pass ratio by test type, display a summary table of the results, and return a flag indicating whether the model passed the entire test suite. - To store the test harness, including the test table, as a set of files, call
h.save(). This will enable you to load and run the same test suite later, for example, when conducting a regression test.
Below is the example of a report generated for a Named Entity Recognition (NER) model, applying tests from five test factories:
| Category | Test type | Fail count | Pass count | Pass rate | Minimum pass rate | Pass? |
| robustness | remove_punctuation | 45 | 252 | 85% | 75% | TRUE |
| bias | replace_to_asian_name | 110 | 169 | 65% | 80% | FALSE |
| representation | min_gender_representation | 0 | 3 | 100% | 100% | TRUE |
| fairness | min_gender_f1_score | 1 | 2 | 67% | 100% | FALSE |
| accuracy | min_macro_f1_score | 0 | 1 | 100% | 100% | TRUE |
All the metrics calculated by LangTest, including the F1 score, bias score, and robustness score, are framed as tests with pass or fail outcomes. This approach requires you to specify the functionality of your application clearly, allowing for quicker and more confident model deployment. Furthermore, it enables you to share your test suite with regulators who can review or replicate your results.
Data Augmentation
A common approach to enhance the robustness or bias of your model is to include new training data that specifically targets these gaps. For instance, if the original dataset primarily consists of clean text without typos, slang, or grammatical errors, or doesn’t represent Muslim or Hindi names, adding such examples to the training dataset will help the model learn to handle them more effectively.
Generating examples automatically to improve the model’s performance is possible using the same method that is used to generate tests. Here is the workflow for data augmentation:
- To automatically generate augmented training data based on the results from your tests, call
h.augment()after generating and running the tests. However, note that this dataset must be freshly generated, and the test suite cannot be used to retrain the model, as testing a model on data it was trained on would result in data leakage and artificially inflated test scores. - You can review and edit the freshly generated augmented dataset as needed, and then utilize it to retrain or fine-tune your original model. It is available as a pandas dataframe.
- To evaluate the newly trained model on the same test suite it failed on before, create a new test harness and call
h.load()followed byh.run()andh.report().
By following this iterative process, NLP data scientists are able to improve their models while ensuring compliance with their ethical standards, corporate guidelines, and regulatory requirements.
Getting Started
Visit langtest.org/ or run pip install LangTest to get started with the LangTest library, which is freely available. Additionally, LangTest is an early stage open-source community project you are welcome to join.
John Snow Labs has assigned a full development team to the project, and will continue to enhance the library for years, like our other open-source libraries. Regular releases with new test types, tasks, languages, and platforms are expected. However, contributing, sharing examples and documentation, or providing feedback will help you get what you need faster. Join the discussion on LangTest’s GitHub page. Let’s work together to make safe, reliable, and responsible NLP a reality.