






















































Using machine learning and regex patterns to identify and extract date information in Spark NLP

TL; DR: Dates extraction from a text is a common Natural Language Processing (NLP) task that involves identifying and extracting references to dates in text data. This can be useful for a wide range of applications, such as event scheduling, social media monitoring, and financial forecasting. Using Spark NLP, it is possible to identify and extract dates from a text with high accuracy.
How to extract dates from the text using NLP
There are different ways to extract date from a text with NLP. Date information extraction is a common task in Natural Language Processing that can be achieved using a variety of techniques:
- Regular Expressions: You can use regular expressions to match patterns that represent dates in the text. For example, you could use a regular expression to match a pattern like “MM/DD/YYYY”. This approach can work well if the date format in the text is consistent.
- Named Entity Recognition (NER): NER is a technique that can identify and classify named entities in text, such as dates. NER can be implemented using both machine learning (ML) and deep learning (DL) techniques. These models can be trained on annotated datasets to learn to identify dates in text.
- Rule-based Systems: You can also use rule-based systems to extract date information. These systems typically use a set of rules that define how to identify dates in text.
DateMatcher and MultiDateMatcher are rule-based annotators in the Spark NLP library that are used to extract date expressions from text using pattern matching. DateMatcher can only extract one date per input document while MultiDateMatcher can extract multiple dates; other than that their performances are the same.
DateMatcher can identify a wide range of date formats, including both absolute and relative dates. DateMatcher uses rules to identify and extract date expressions from text. The component is highly customizable, allowing users to specify their own rules to match specific date formats.
Please check the common scenarios for datetime usage in Spark.
Some of the features of Spark NLP DateMatcher include:
- Ability to handle multiple languages: DateMatcher can be used to match date expressions in 204 languages.
- Support for relative dates: DateMatcher can match relative date expressions, such as “tomorrow,” “next week,” and “last year.”
- Change Input/Output Date Formats.
- Set missing day if it is missing in the text.
Overall, DateMatcher is a powerful and flexible tool for extracting date expressions from text, and can be customized to match specific formats and languages. It is an important component in many NLP applications that require date information, such as news analysis, social media monitoring, and financial forecasting.
In this post, you will learn how to use Spark NLP to perform date extraction from text.
Let us start with a short Spark NLP introduction and then discuss the details of date extraction with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs (JSL). It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
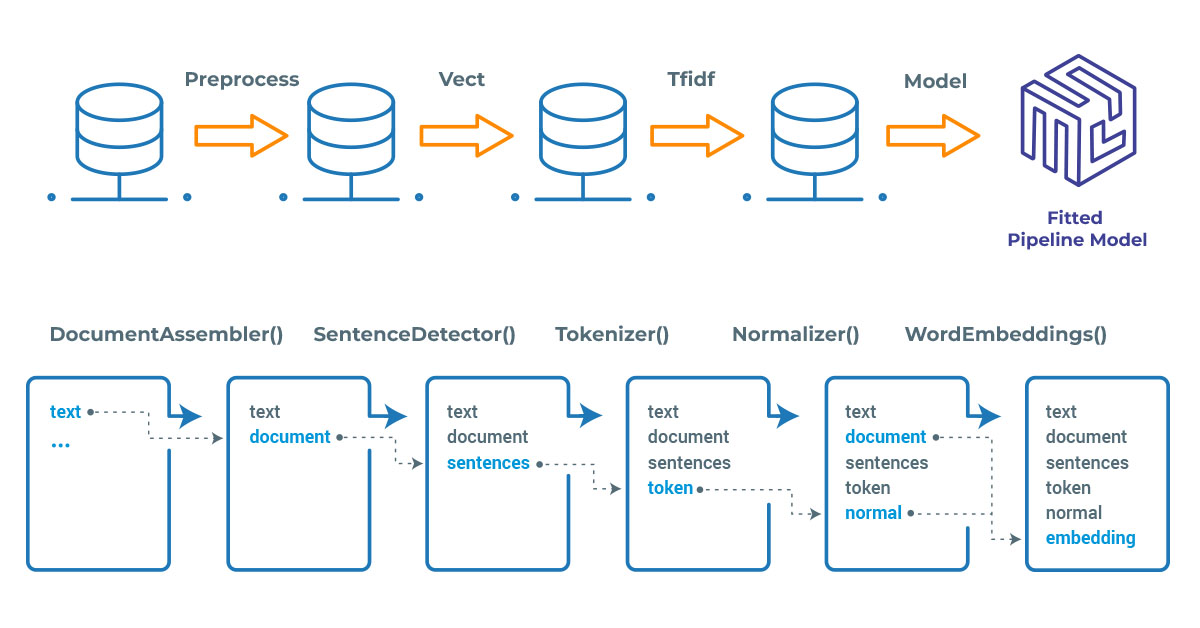
Spark NLP pipelines
Each step contains an annotator that performs a specific task, such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
How can NLP extract dates from texts
Spark NLP’s powerful and accurate tools allow us to perform date extraction, identify and extract dates from text with high accuracy.
Comparing DateMatcher and MultiDateMatcher
DateMatcher and MultiDateMatcher annotators extract the following date information automatically from the text:

DateMatcher and MultiDateMatcher annotators expect DOCUMENT as input, and then will provide DATE as output.
Please check the details of the pipeline below, where we define a short pipeline and then define 5 texts for text classification:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
DateMatcher,
MultiDateMatcher
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Extracts one date information from text
date = (
DateMatcher()
.setInputCols("document") \
.setOutputCol("date") \
.setOutputFormat("yyyy/MM/dd")
)
# Step 3: Extracts multiple date information from text
multiDate = (
MultiDateMatcher()
.setInputCols("document") \
.setOutputCol("multi_date") \
.setOutputFormat("MM/dd/yy")
)
nlpPipeline = Pipeline(stages=[document_assembler, date, multiDate])
text_list = ["See you on next monday.",
"She was born on 02/03/1966.",
"The project started yesterday and will finish next year.",
"She will graduate by July 2023.",
"She will visit doctor tomorrow and next month again."]
In Spark ML, we need to fit the obtained pipeline to make predictions (see this documentation page if you are not familiar with Spark ML).
After that, we get predictions by transforming the model.
# Create a dataframe
spark_df = spark.createDataFrame(text_list, StringType()).toDF("text")
# Fit the dataframe and get predictions
result = pipeline.fit(spark_df).transform(spark_df)
# Display the extracted date information in a dataframe
result.selectExpr("text","date.result as date", "multi_date.result as multi_date").show(truncate=False)

The above dataframe shows that DateMatcher extracted one date and MultiDateMatcher extracted all the date information from the text.
Also, date formats for the annotators are different in the pipeline, defined by the setOutputFormat parameter.
Relative Dates
DateMatcher and MultiDateMatcher annotators can also return relative dates. To accomplish this, a reference (or anchor) date must be defined. Reference date parameters can be set by setAnchorDateDay(), setAnchorDateMonth(), setAnchorDateYear().
If an anchor date parameter is not set, the current day or current month or current year will be set as the default value.
Check the below pipeline with two separate MultiDateMatcher annotators:
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Set anchor day, month and year
multiDate = (
MultiDateMatcher()
.setInputCols("document")
.setOutputCol("multi_date")
.setOutputFormat("MM/dd/yyyy")
.setAnchorDateYear(2001)
.setAnchorDateMonth(1)
.setAnchorDateDay(17)
)
# Step 3: Set anchor month and year - day is the current day
multiDate_no_day = (
MultiDateMatcher()
.setInputCols("document")
.setOutputCol("multi_date_no_day")
.setOutputFormat("MM/dd/yyyy")
.setAnchorDateYear(2001)
.setAnchorDateMonth(1)
)
nlpPipeline = Pipeline(stages=[document_assembler, multiDate, multiDate_no_day])
text_list = ["See you on next monday.",
"She was born on 02/03/1966.",
"The project started yesterday and will finish next year.",
"She will graduate by July 2023.",
"She will visit doctor tomorrow and next month again."]
After that, we get predictions by transforming the model for the new parameters:
# Create a dataframe
spark_df = spark.createDataFrame(text_list, StringType()).toDF("text")
# Fit the dataframe and get predictions
result = pipeline.fit(spark_df).transform(spark_df)
# Display the extracted date information in a dataframe
result.selectExpr("text","multi_date.result as date", "multi_date_no_day.result as date_no_day_anchor").show(truncate=False)

Different anchor (reference) days produced different results for the 3rd and 5th texts, where reference dates are used.
Other Languages
Date matching annotators can be used with a total of 204 languages. The default value is "en"– English.
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
multiDate = (
MultiDateMatcher()
.setInputCols("document")
.setOutputCol("multi_date")
.setOutputFormat("yyyy/MM/dd")
.setSourceLanguage("de")
)
nlpPipeline = Pipeline(stages=[document_assembler, multiDate])
spark_df = spark.createDataFrame([
["Das letzte zahlungsdatum dieser rechnung ist der 4. mai 1998."],
["Wir haben morgen eine prüfung."]]).toDF("text")
result = pipeline.fit(spark_df).transform(spark_df)
result.selectExpr("text", "multi_date.result as date").show(truncate=False)

The example above shows date extraction in German.
The first row contains an actual date while the second one has a relative date (morgen means tomorrow in English). They are formatted in the desired output format.
Please check the link for the supported languages.
For additional information, please consult the following references.
- Documentation : DateMatcher, MultiDateMatcher
- Python Doc : DateMatcher, MultiDateMatcher
- Scala Doc : DateMatcher, MultiDateMatcher
- For extended examples of usage, see the Spark NLP Workshop.
Conclusion
Dates extraction is a crucial task in NLP that plays a vital role in a wide range of text-based applications. By accurately identifying and normalizing dates mentioned in text data, NLP models can help facilitate temporal analysis, event extraction, sentiment analysis, summarization, and data integration. The ability to extract date from text files helps to unlock valuable insights and drive more advanced text-based applications in a variety of fields.
DateMatcher and MultiDateMatcher are powerful and accurate language detection tools in Spark NLP, and are valuable assets for any NLP application that involves multilingual date value extraction.




