
























































This post presents a benchmark comparison between two cutting-edge large language models evaluated across a broad spectrum of clinical and biomedical text understanding tasks.
On one side is GPT-4.5 from OpenAI, currently their most advanced and highest-performing model. On the other is the suite of healthcare-specific large language models developed by John Snow Labs. These models span multiple sizes, including 7B, 10B, 14B, 24B, and even large-scale variants.
Blind Evaluation of factuality and clinical relevance by practicing medical doctors
Over the past few years, there has been growing consensus in the academic community that evaluating LLMs for healthcare requires assessing multiple dimensions: clinical accuracy, relevance, completeness, safety, clarity, and hallucination risk. John Snow Labs adheres to this philosophy. All models are evaluated by clinicians using a structured, multi-dimensional framework. In this discussion, we present results from a subset of these dimensions, alongside examples of our safety alignment process.
The evaluation used over 200 newly created questions across four categories: clinical text summarization, clinical information extraction, biomedical research Q&A, and open-ended medical knowledge. Each question was designed to ensure that no model had been exposed to the data during training.
Evaluating LLMs for healthcare demands a structured, multi-dimensional clinical framework, one that prioritizes factual accuracy, clinical relevance, and safety, not just fluency or length.
The evaluators were experienced clinicians. For each task, prompts were submitted to two LLMs using standard APIs. The original text and both responses were then shown to physicians, with the order randomized and responses blinded so the evaluation did not know which LLM was used to generate the output. Evaluators could express a preference or state that both responses were equally good. Inter-annotator agreement analysis and washout studies, asking the same clinicians the same questions two weeks later, ensured consistency and validity.
The evaluation focused on three core dimensions:
- Factuality: is the answer factually correct based on the input?
- Clinical relevance: does the answer include the critical information a doctor would expect?
- Conciseness: is the answer clear and to the point?
This report emphasizes factuality and clinical relevance, as conciseness can be strongly influenced by prompt engineering.
John Snow Labs Shows Superior Results to GPT-4.5 Across All Tasks
In a head-to-head comparison of John Snow Labs’ Medical LLM Medium (24B) versus OpenAI’s GPT-4.5 across all tasks, evaluators had no preference in 69% of cases for factuality. However, when a preference was stated, John Snow Labs’ model was chosen 18% of the time, compared to GPT-4.5’s 13%. For clinical relevance, evaluators were neutral about half the time. When a choice was made, John Snow Labs’ model was preferred 29% of the time compared to 26% for GPT-4.5.
John Snow Labs’ Medical LLM surpass GPT-4.5 in factuality and clinical relevancy across different tasks while operating at just 1% of the cost.
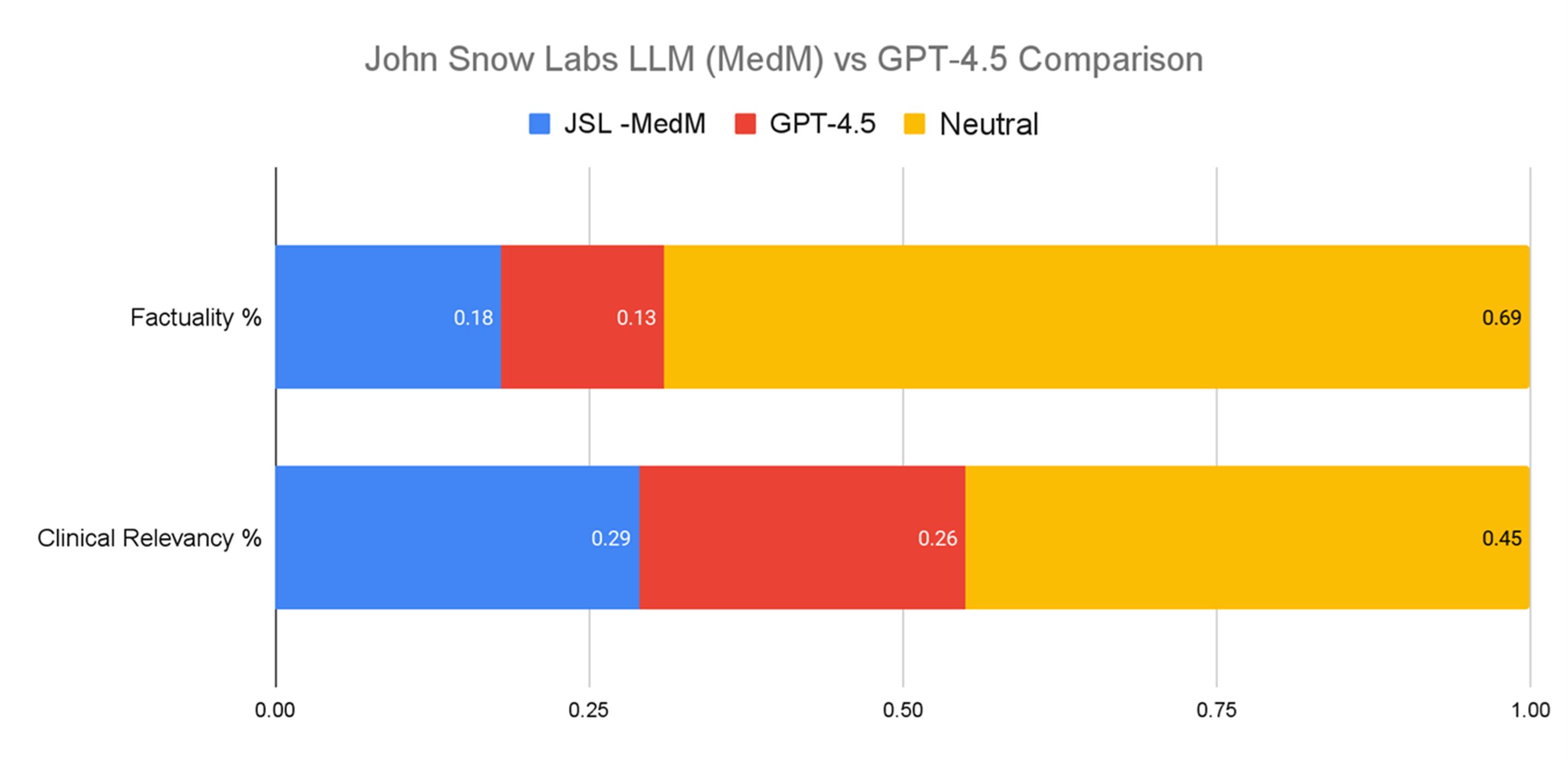
Evaluation across all tasks.
Crucially, John Snow Labs’ model delivers these results at just 1% of the cost of GPT-4.5, with the pricing comparison accounting for hardware, hosting, and licensing.
Clinical Information Extraction
Clinical information extraction is a core task in many real-world applications. Whether identifying procedures in radiology reports or extracting patient history from intake notes, this function supports everything from safety surveillance to population health analysis.
For clinical information extraction, John Snow Labs’ model was preferred up to three times more often than GPT-4.5 when experts made a choice.
In our evaluation, two-thirds of the time both models were rated equally factual. However, when evaluators expressed a preference, John Snow Labs’ model was chosen three times more often (24% versus 8%). On clinical relevance, it was preferred over GPT-4.5 (29% versus 18%).
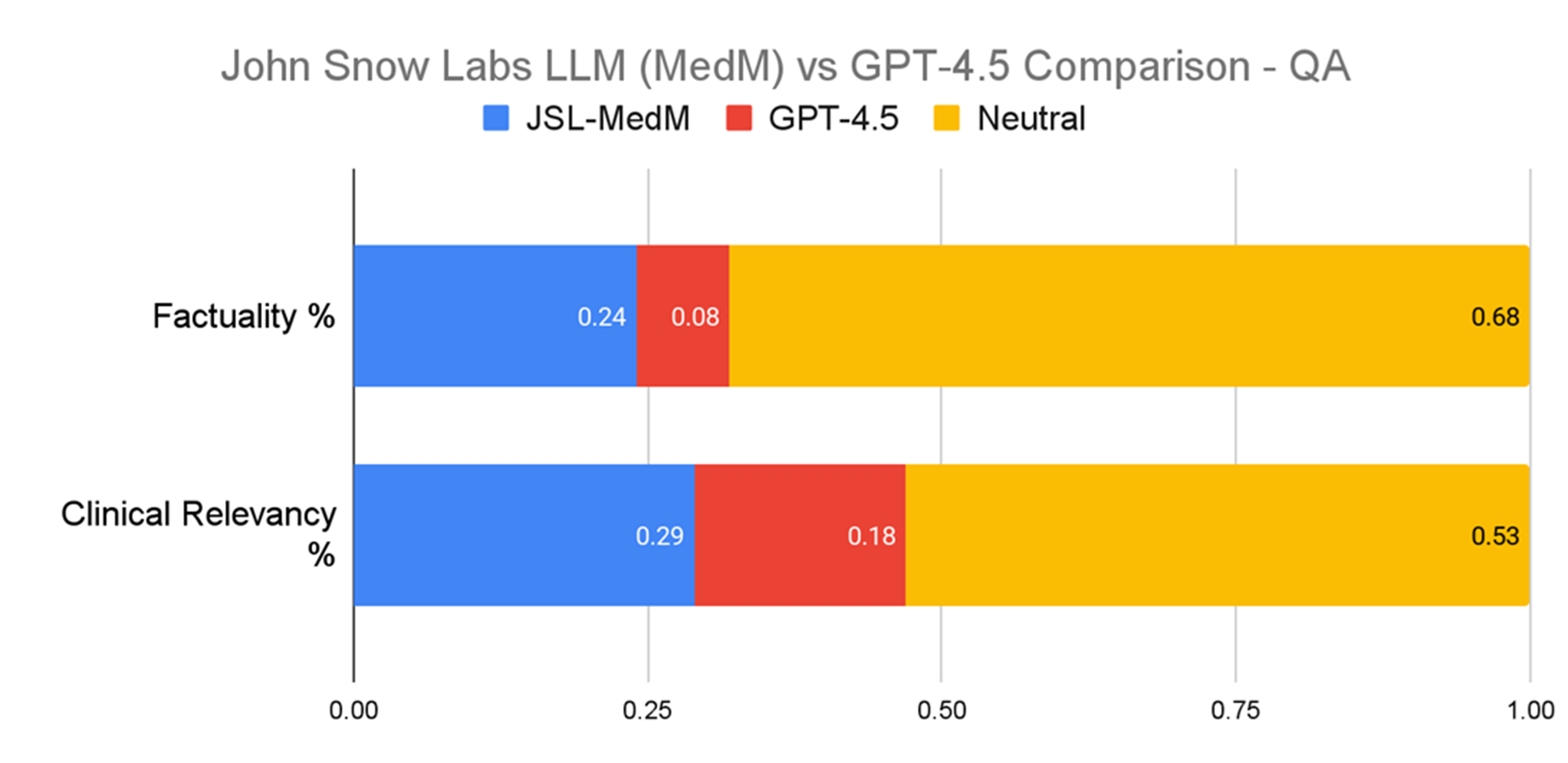
Evaluation on Clinical Information Extraction.
Biomedical Q&A Tasks
In biomedical Q&A tasks, evaluators assessed answers to questions such as: “What biomarkers are commonly negative in APL?” or “What is sNFL used for?” Compared to GPT-4.5, John Snow Labs’ model was preferred 2.5 times more often for clinical relevance (38% versus 15%) and also more frequently for factuality (18% versus 10%).
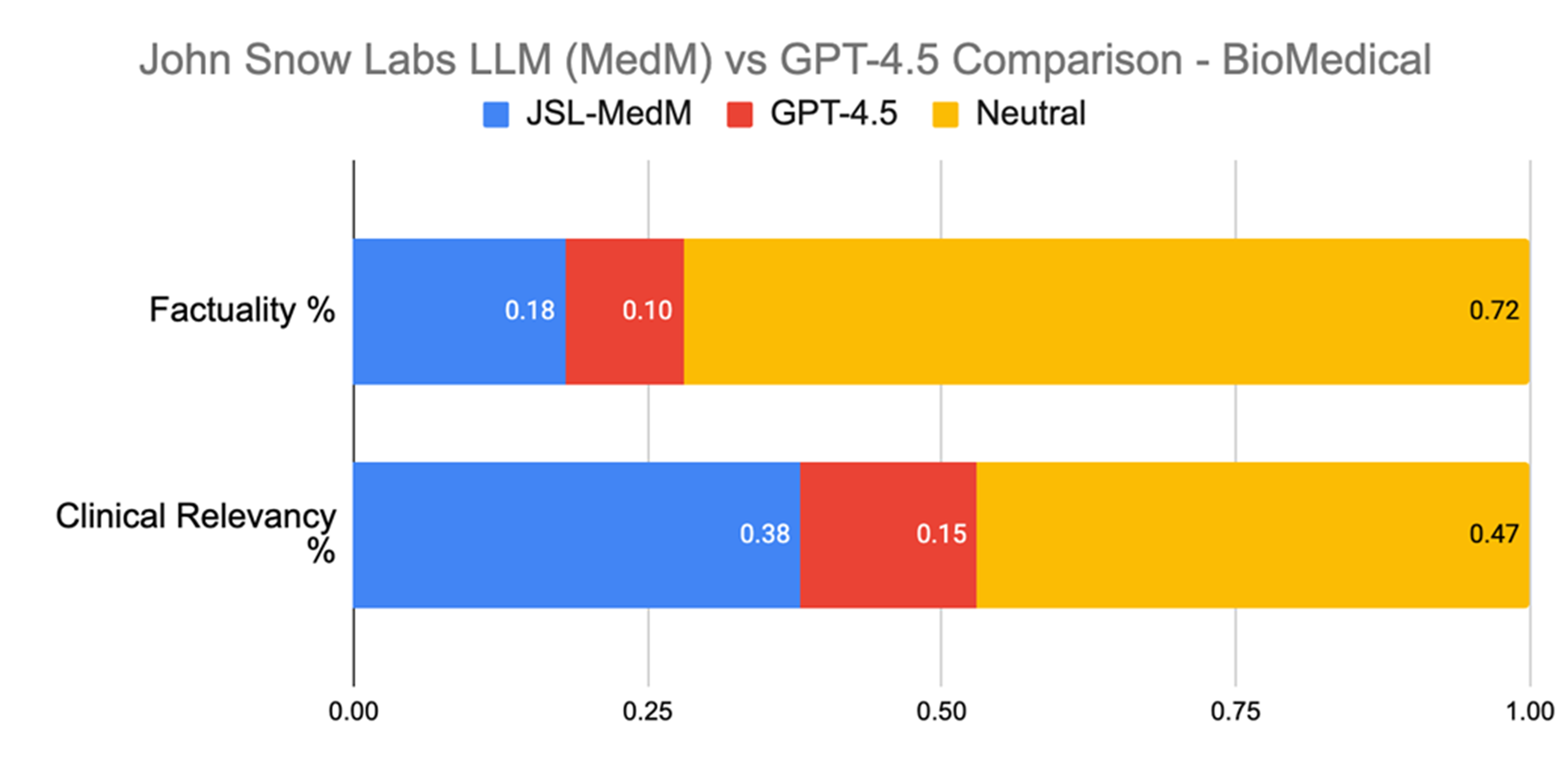
Evaluation on Biomedical Q&A.
These results underscore a key point: general-purpose models are often trained with consumer applications in mind. While they may perform well in layperson contexts, they can fall short when precision, domain alignment, and clinically sound outputs are required by medical professionals.
In biomedical Q&A, clinicians preferred John Snow Labs’ model 2.5 times more often than GPT-4.5 for clinical relevance, highlighting the need for domain-specific models in medicine.
Clinical Note Summarization and the Risk of Hallucinations
Clinical note summarization is a particularly compelling use case. LLMs often generate summaries that rival or surpass those written by human experts. In blind evaluations, AI-generated summaries are frequently preferred, and may even hallucinate less than human-authored ones. However, these gains do not always translate into time savings. A study from the University of California, San Diego, found that primary care physicians using ChatGPT to draft patient messages ended up spending 22% more time, as they needed to review and edit the drafts before sending. The extra steps added rather than saved time.
The main issue with summarization is hallucinations. While LLMs are impressively fluent, they can fabricate content, sometimes in ways that seem plausible. Such inaccuracies can dangerously alter key clinical details. For this reason, factual accuracy is paramount. John Snow Labs has developed a hallucination detection tool tailored to LLM-generated medical content, which is used internally to refine and validate models.
In clinical summarization, John Snow Labs’ model was preferred twice as often as GPT-4o for factuality, proving that domain-specific tuning beats general models even in their strongest tasks.
In a randomized, blind evaluation where physicians reviewed summaries generated by John Snow Labs’ fine-tuned model versus GPT-4o, John Snow Labs model was preferred twice as often for Factuality (47% vs 25%) Clinical Relevancy (48% versus 25%) and Conciseness (42% versus 25%) when compared with GPT-4o.
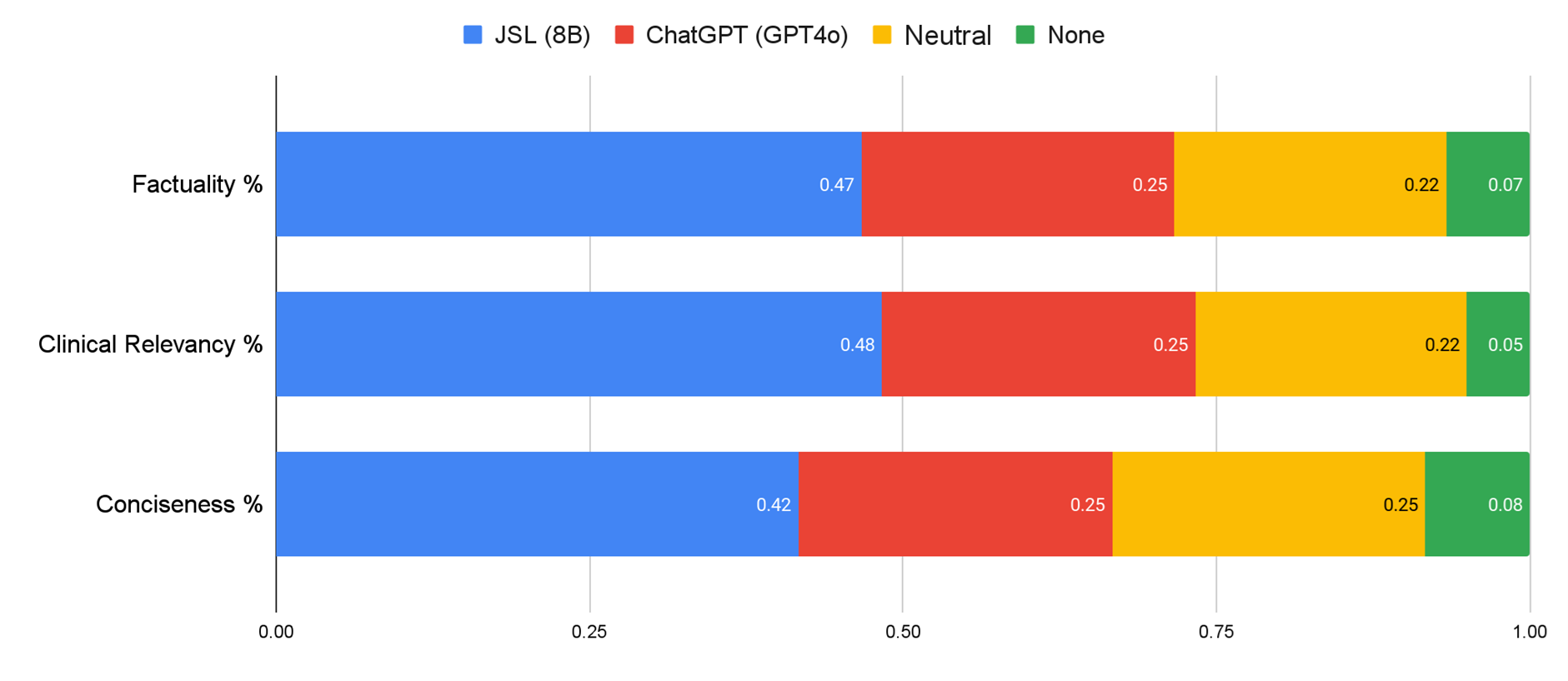
This shows that even for tasks where LLMs seem strong, domain-tuned models not only match but often exceed their performance, with more predictable behavior, lower cost, and greater transparency.
Balancing performance with operational needs
Selecting a medical language model for production environments involves more than just evaluating performance on benchmark tasks. While this study highlights that domain-specific models tend to outperform general-purpose systems in clinical relevance and factuality, as seen in the consistent preference for John Snow Labs’ model across a variety of blinded evaluations, there are broader operational factors that often weigh just as heavily in decision-making.
John Snow Labs’ Medical LLMs run securely in your infrastructure, update every two weeks, and scale affordably thanks to server-based pricing.
Healthcare and life sciences organizations routinely face stringent data privacy requirements. In this context, models that can be deployed within a secure infrastructure, including support for air-gapped systems and containerized APIs, present an important operational advantage. This ability to maintain full control over data and model execution is particularly relevant when working with protected health information or sensitive research content.
Scalability and cost structure are also crucial. Usage-based pricing models, common among hosted LLM services, can quickly become impractical when applied to large-scale clinical workloads. Server-based licensing, in contrast, allows for predictable costs and may offer significant savings when processing millions of records. For institutions planning high-throughput applications, this pricing model can materially impact long-term sustainability.
Finally, the speed at which medical knowledge evolves makes regular model updates an important consideration. Solutions that integrate new findings, datasets, and methodologies on a consistent schedule help organizations stay aligned with current clinical standards and practices.
Taken together, these findings suggest that while general-purpose models like GPT-4.5 are powerful and broadly applicable, task-optimized medical LLMs—especially those designed for secure, large-scale deployment—may offer a better fit for organizations with clinical responsibilities. The performance advantages seen in this evaluation, when combined with considerations around privacy, integration, and cost, make a strong case for giving serious thought to domain-specific alternatives when choosing a model for healthcare settings.




