


















































Signs, Symptoms, Treatments, Findings, Procedures, Drugs, Tests, Labs, Vitals, Sections, Adverse Effects, Risk Factors, Anatomy, Social Determinants, Vaccines, Demographics, Sensitive Data
Clinical Trial Design, Protocols, Objectives, Results; Research Summary & Outcomes; Organs, Cell Lines, Organisms, Tissues, Genes, Variants, Expressions, Chemicals, Phenotypes, Proteins, Pathogens








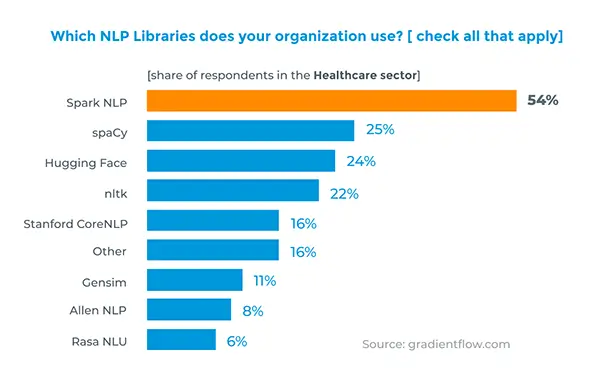
Being the most widely used library in the healthcare industry, John Snow Labs’ Healthcare NLP comes with 2,000+ pretrained models that are all developed & trained with latest state-of-the-art algorithms to solve real world problems in the healthcare domain at scale. To provide reliable models and tools all the time while covering edge cases in real-world data and improve how well models generalize, the datasets and models are updated and augmented on a regular basis.
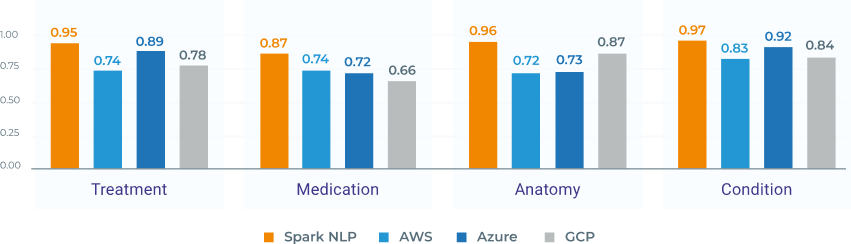
This talk shares accuracy benchmarks from the healthcare-specific models on De-Identification, Named Entity Recognition and Entity Resolution Models. It compares accuracy with respect to both peer-reviewed academic benchmarks and the commercial solutions provided by major cloud providers (AWS Medical Comprehend, GCP Healthcare API and Azure Text Analytics for Health).