






















































Natural Language Processing (NLP) is a subfield of Artificial Intelligence (AI) that focuses on the interaction between computers and human language. It involves the development and application of computational algorithms and models to understand, analyze, and generate human language in a way that is meaningful and useful. NLP is most in demand in healthcare, finance, and legal at the moment.
There are a huge number of financial, legal, and medical tasks that NLP brings to the latest level. Our company has a detailed guide regarding examples of NLP use cases in healthcare. In the same article, we will consider ways of solving these tasks and problems in various business areas.

NLP is a complex and challenging field, as human language is full of ambiguities and nuances. However, NLP has made significant progress in recent years, and it is now being used in a wide range of applications. Common use cases include:
- Named entity recognition (NER),
- Text classification and sentiment analysis,
- Information extraction,
- Question answering,
- AI chatbots and virtual assistants,
- Text summarization,
- Paraphrasing,
- Speech recognition,
- Machine translation,
- Text generation, etc.
The graph shows the analysis of the responses to the question asked in a survey organized by gradientflow.com:
What are the main types of NLP use cases that your production system supports?
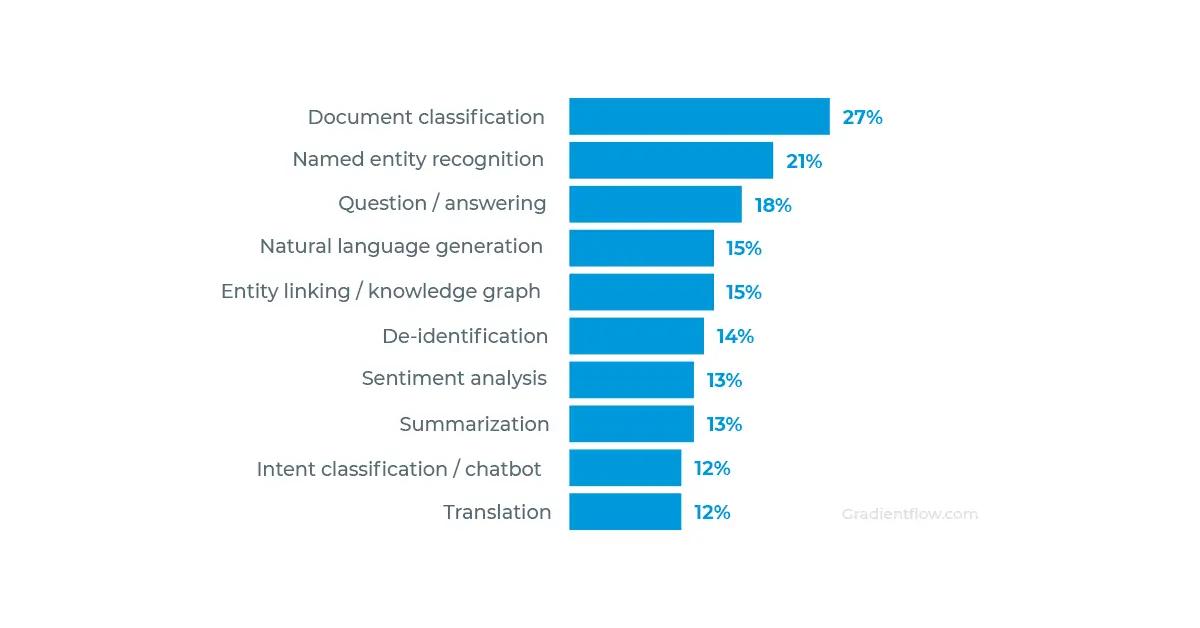
Results of the survey organized by gradientflow.com
What are the main types of NLP use cases that your production system supports?
NLP is essential in many AI applications due to its ability to enable effective communication and understanding between humans and machines. NLP allows AI systems to interpret and analyze human language. With NLP, AI systems can process and derive insights from vast amounts of textual data, enabling organizations to gain valuable knowledge from unstructured information.
A NLP library is a collection of software tools, algorithms, and resources that provide developers and researchers with pre-built functions and models to process, analyze, and understand human language. These libraries offer functionalities for tasks like tokenization, part-of-speech tagging, named entity recognition, word embedding models, sentiment analysis, machine translation, and more. They simplify the implementation of NLP applications by providing ready-to-use components and often include pre-trained models trained on large text corpora. NLP libraries help accelerate the development of language processing applications by offering standardized and efficient solutions for various NLP tasks.
Some of these libraries often come with pre-trained models that have been trained on large corpora of text, allowing users to perform NLP tasks out of the box without the need for extensive training data or domain-specific knowledge.
There are several popular NLP libraries available that provide tools, algorithms, and resources for natural language processing. Some of the most widely used NLP libraries are:
- Natural Language Toolkit (NLTK) is a versatile and open-source library that supports tasks like classification, tokenization, POS tagging, stopping word removal, stemming, semantic reasoning, etc.
- SpaCy is an open-source library developed to be used in production environments. It can quickly process high volumes of text making it a perfect option for statistical NLP; also known for its speed and ease of use.
- Stanford Core NLP library is a collection of NLP tools implemented in Java. It is a robust and reliable open-source tool for NLP tasks
- Gensim is a Python library for topic modeling and document similarity analysis.
- Transformers (Hugging Face) is a powerful Python NLP Library with thousands of pre-trained models that can be used to perform NLP tasks.
- TextBlob is another Python library used for processing textual data. It comes with an extremely friendly and easy-to-use interface.
These are just a few examples of the popular NLP libraries available. Each library has its own strengths, features, and target audience. The choice of library depends on specific requirements, programming language preferences, and the nature of the NLP tasks you wish to perform.
Spark NLP is developed to be a single unified solution for all the NLP tasks and is the only library that can scale up for training and inference in any Spark cluster, take advantage of transfer learning and implementing the latest and greatest algorithms and models in NLP research, and deliver a mission-critical, enterprise-grade solutions at the same time.
It offers scalability and high performance by leveraging distributed computing capabilities. Spark NLP provides a wide range of NLP functionalities, including tokenization, part-of-speech tagging, named entity recognition, sentiment analysis, and more. It incorporates state-of-the-art NLP models and supports multilingual processing. With seamless integration into the Apache Spark ecosystem, Spark NLP enables end-to-end data processing pipelines and caters to industries dealing with big data and complex NLP tasks.
The active community and Slack channel surrounding Spark NLP provides support and contributes to its development, making it a valuable choice for organizations and projects that require scalable, efficient, and comprehensive NLP capabilities. It is commercially supported by John Snow Labs Inc, an award-winning healthcare AI and NLP company based in USA.
Here are some reasons why Spark NLP has gained popularity and the need for its existence:
- Scalability: One of the key differentiators of Spark NLP is its ability to scale horizontally and process large volumes of text data efficiently. It leverages the distributed computing capabilities of Apache Spark, making it suitable for big data processing and handling massive datasets that may not be feasible with traditional NLP libraries.
- Performance: Spark NLP is designed to provide high-performance NLP processing. By distributing the workload across a cluster of machines, it takes advantage of parallel processing, enabling faster execution times for NLP tasks. This is especially beneficial when dealing with large-scale datasets and computationally intensive operations.
- Support for Large-Scale NLP Workflows: Spark NLP caters to the needs of organizations and industries dealing with big data and complex NLP tasks. It offers comprehensive functionality and pre-built models for a wide range of NLP tasks, allowing users to build complete end-to-end NLP workflows without the need to integrate multiple libraries or tools.
- Multilingual Support: Spark NLP provides robust support for processing text data in multiple languages. It includes pre-trained models and pipelines for various languages, allowing users to perform NLP tasks on multilingual datasets and develop applications that cater to diverse language requirements.
- Community and Support: Spark NLP benefits from an active and growing community of users and contributors. The community provides support, shares best practices, and contributes to the development of the library. This support network ensures that users have access to resources, documentation, and a vibrant community that helps them overcome challenges and make the most of Spark NLP.
- Industry Applications: Spark NLP is particularly well-suited for industries and domains that deal with large-scale text data, such as healthcare, finance, legal and social media analysis. It enables efficient processing, analysis, and extraction of valuable insights from massive amounts of textual information, making it a valuable tool for industry-specific NLP applications.
Here is a general overview, comparison, and performance of various NLP libraries:
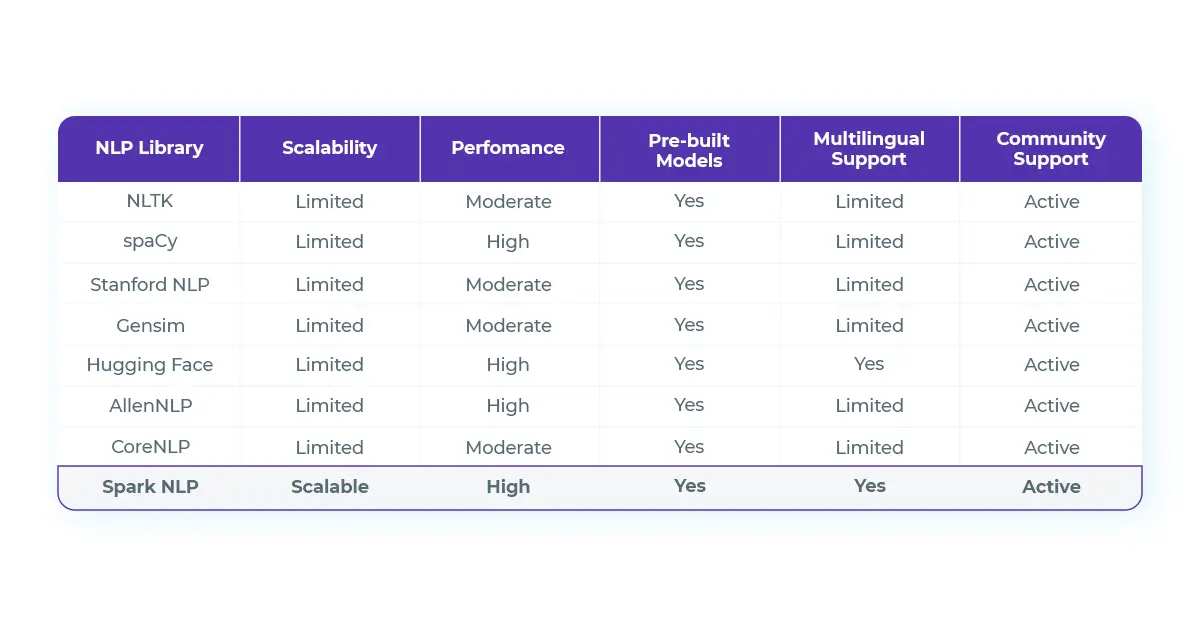
Comparison of various NLP libraries
The graph below shows the analysis of the responses to a question asked in a survey about the most popular NLP libraries in business:
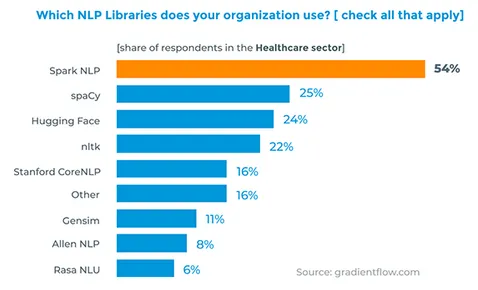
Most widely used NLP Libraries in Healthcare
John Snow Labs as a leading development of NLP libraries
John Snow Labs is an award-winning data analytics company leading and sponsoring the development of the Spark NLP library. The company provides commercial support, indemnification and consulting for it. This provides the library with long-term financial backing, a funded active development team, and a growing stream of real-world projects that drives robustness and roadmap prioritization.

John Snow Labs is recipient of several awards in NLP
John Snow Labs is a leading provider of NLP software, models, and data for healthcare and life science organizations. The company’s products are used by some of the world’s largest healthcare companies, including Roche, Kaiser Permanente, McKesson, Merck, and Novartis.

Spark NLP is already in use in enterprise projects for various use cases
Conclusion
NLP is a crucial field in AI that focuses on enabling computers to understand, process, and generate human language. NLP libraries play a significant role in advancing NLP research and applications by providing pre-built tools, models, and resources that simplify the development of language processing systems.
Among the many NLP libraries available, Spark NLP stands out as a powerful and versatile choice. Built on top of Apache Spark, it offers scalability and high-performance processing capabilities, making it well-suited for handling large-scale text data and complex NLP tasks. Spark NLP provides a comprehensive range of NLP functionalities, including named entity recognition, sentiment analysis, question answering, summarization and more, allowing users to build end-to-end NLP pipelines efficiently.
Spark NLP also incorporates state-of-the-art NLP models and offers support for multilingual processing, making it adaptable to diverse language requirements. Its seamless integration with the Apache Spark ecosystem allows users to leverage the power of distributed computing, machine learning, and data processing, enabling the development of sophisticated and efficient NLP workflows.
Explore how our team uses Spark NLP and its libraries in real NLP use cases.




