






















































Using Spark NLP capabilities to train and use CRF models for NER at scale

Named Entity Recognition (NER) Conditional Random Field (CRF) is a machine learning algorithm in Spark NLP that is used to identify and extract named entities from unstructured text data. Spark NLP provides pre-trained NER models that use NER CRF, or users can also train their own custom NER models using the CRF algorithm.
What is Conditional Random Field
Conditional Random Fields (CRFs) are a class of probabilistic graphical model that is commonly used in machine learning and natural language processing applications. In NLP, CRFs are used for the sequence labeling tasks, which involve assigning labels to each element in a sequence of observations, such as assigning part-of-speech tags to words in a sentence or recognizing named entities (such as people, organizations, and locations) in a text.
CRFs use the observed data to predict the labels of the sequence, while taking into account the dependencies between neighboring labels. This makes them particularly effective for tasks where the labels of neighboring elements are dependent on each other, such as in NLP.
CRF model for NER is trained on a labeled dataset that includes examples of text with corresponding named entity labels. During training, the model learns to identify patterns and features in the input text that are associated with named entities, such as the presence of specific words or phrases, syntactic structures, or contextual information.
Once the model is trained, it can be used to predict named entities by assigning labels to each token based on the learned patterns and features. The predictions are made using a probabilistic framework that takes into account the dependencies between adjacent tokens in the sequence.
The figure below shows the visualization of the named entities recognized from a sample text. The entities are extracted, labelled (as PERSON, DATE, ORG etc) and displayed on the original text. Please check the post named “Visualizing Named Entities with Spark NLP”, which gives details about Ner Visualizer.

Extracted named entities, displayed by the Ner Visualizer.
Overall, NER CRF NLP models are a powerful tool for automated named entity recognition. The NER CRF algorithm in Spark NLP is highly customizable and can be trained on a wide range of datasets and domains.
Just remember that there are many alternatives in Spark NLP for named entity recognition. The most accurate, but also complex models are Deep learning-based models. Deep learning-based models have shown state-of-the-art performance on NER tasks.
There are also rule-based methods, which use a set of hand-crafted rules based on patterns, heuristics, and dictionaries to identify named entities in text. Users can also create their own custom rules and dictionaries to improve the performance of the NER system.
Finally, it is possible to use multiple models, like a hybrid system, to increase the accuracy of the model.
In this post, you will learn how to use Spark NLP to named entity recognition by CRF using pretrained models and also training a custom model.
Let us start with a short Spark NLP introduction and then discuss the details of NER by CRF with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:

First three rows of the training dataset
And now the test dataset:
testData = CoNLL().readDataset(spark, 'NER_NCBIconlltest.txt') testData.show(3)

First three rows of the test dataset
Spark NLP has the pipeline approach and the pipeline will include the necessary stages to extract the entities from the text:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
Tokenizer,
PerceptronModel,
WordEmbeddingsModel,
NerCrfModel,
NerConverter
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = DocumentAssembler() \
.setInputCol('text') \
.setOutputCol('document')
# Step 2: Tokenization
tokenizer = Tokenizer() \
.setInputCols(['document']) \
.setOutputCol('token')
# Step 3: Perceptron model to tag words' part-of-speech
posTagger = PerceptronModel\
.pretrained()\
.setInputCols(["token", "document"])\
.setOutputCol("pos")
# Step 4: Glove100d Embeddings
embeddings = WordEmbeddingsModel.pretrained()\
.setInputCols(["token", "document"])\
.setOutputCol("embeddings")
# Step 5: Entity Extraction
ner_model = NerCrfModel.pretrained()\
.setInputCols(['document', 'token', 'pos', 'embeddings']) \
.setOutputCol('ner')
# Step 6: Converts a IOB representation of NER to a user-friendly one
ner_converter = NerConverter() \
.setInputCols(['document', 'token', 'ner']) \
.setOutputCol('entities')
# Define the pipeline
pipeline = Pipeline(stages=[
document_assembler,
tokenizer,
posTagger,
embeddings,
ner_model,
ner_converter
])
# Fit and transform the dataframe to the pipeline
model = pipeline.fit(trainingData)
result = model.transform(trainingData)
This model was trained by using the ‘glove_100d’, so we had to use the same embeddings while running the model.
Now, we will explode the results to get a nice dataframe of the entities. Here, chunks with no associated entity (tagged “O”) were filtered.
result.select(F.explode(F.arrays_zip(result.entities.result,
result.entities.metadata)).alias("cols")) \
.select(F.expr("cols['0']").alias("chunk"),
F.expr("cols['1']['entity']").alias("ner_label")).show(15, truncate=False)
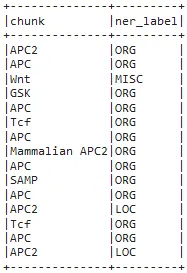
Extracted chunks and the predicted labels
As you can see, adding the NerConverter as the last stage helped us display only the chunks (or a combination of valuable extracted entities), not all the extracted tokens. This stage served as a filtering step and additionally, tokens labelled as B- and I- are connected to provide us the full chunk.
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run entity extraction by CRF with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
# Returns a pandas Data Frame, we select the desired columns
nlp.load('ner.crf').predict("Donald Trump and Angela Merkel dont share many oppinions")

After using the one-liner model, the result shows the NERs and their labels
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
NerCrfApproach
In order to show the capacity of the NerCrfApproach annotator in model training, let us train a model with the training dataset and then use this trained model to get predictions from the test dataset.
The pipeline below is quite similar to the one that we used for NerCrfModel annotator except a few stages:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
SentenceDetector,
Tokenizer,
PerceptronModel,
Word2VecModel,
NerCrfApproach
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = DocumentAssembler() \
.setInputCol('text') \
.setOutputCol('document')
# Step 2: Getting the sentences
sentence = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
# Step 3: Tokenization
tokenizer = Tokenizer() \
.setInputCols(['sentence']) \
.setOutputCol('token')
# Step 4: Perceptron model to tag words' part-of-speech
posTagger = PerceptronModel\
.pretrained()\
.setInputCols(["token", "sentence"])\
.setOutputCol("pos")
# Step 5: Glove100d Embeddings
embeddings = Word2VecModel.pretrained()\
.setInputCols(["token"])\
.setOutputCol("embeddings")
# Step 6: Model training
nerTagger = NerCrfApproach() \
.setInputCols(["sentence", "token", "pos", "embeddings"]) \
.setLabelColumn("label") \
.setMinEpochs(1) \
.setMaxEpochs(3) \
.setOutputCol("ner")
# Define the pipeline
pipeline = Pipeline(stages=[
document_assembler,
sentence,
tokenizer,
posTagger,
embeddings,
nerTagger
])
In this pipeline, instead of the WordEmbeddings annotator, we used Word2Vec to generate the embeddings during model training and got very satisfactory results.
We will use the training dataset for model training and then use the test dataset to get predictions:
# Fit the training dataset to the pipeline pipelineModel = pipeline.fit(trainingData) # Get the predictions by transforming the test dataset predictions = pipelineModel.transform(testData)
Now, we will explode the results to get a nice dataframe of the tokens, ground truths and the labels predicted by the model we just trained.
predictions.select(F.explode(F.arrays_zip(predictions.token.result,
predictions.label.result,
predictions.ner.result)).alias("cols")) \
.select(F.expr("cols['0']").alias("token"),
F.expr("cols['1']").alias("ground_truth"),
F.expr("cols['2']").alias("prediction")).show(25, truncate=False)
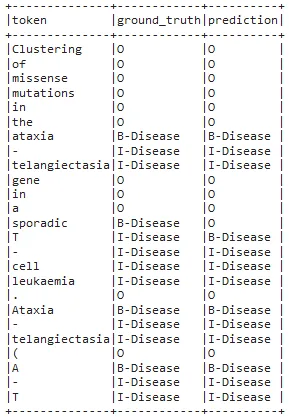
Tokens, ground truths and the labels predicted by the model
During training we only used three epochs (an epoch represents one iteration of the model training process, where the model goes through all the training examples once), normally this number will be higher. Still, the results are satisfactory, with only one mistake in the table shown above.
For additional information, please consult the following references.
- Documentation : NerCRF
- Python Doc : NerCRF
- Scala Doc : NerCRF
- For extended examples of usage, see the Spark NLP Workshop repository.
Conclusion
NER is a critical task in NLP that involves identifying and extracting entities from text data. CRF NLP models are a popular approach for NER in NLP, as they can effectively model the dependencies between adjacent tokens in a sequence while making predictions.
Overall, the NER CRF in Spark NLP is a powerful tool for named entity recognition and extraction in NLP. It allows users to automate the identification and extraction of named entities from unstructured text data, saving time and effort for data scientists and developers.
By combining the NER Conditional Random Field algorithm with other tools and components in Spark NLP, it is possible to create powerful and flexible NLP pipelines that can be adapted to a wide range of use cases and domains.




