On its website, the Good Clinical Practice (GCP) Network has published a list of “essential documents for the conduct of a clinical trial”. These documents are crucial because they allow the evaluation of a clinical trial, and the quality of the data produced. They also demonstrate that the trial investigator, sponsor, and monitor complied with GCP standards, and any applicable regulatory requirements. These documents are collectively referred to as the “Trial Master File” (TMF), which must be established at the start of the trial.
GCP lists 53 documents that should be a part of every TMF for every trial. This sounds like a lot, but it’s actually a very small number compared to many real-world clinical trials. In reality, a pharmaceutical company conducting a clinical trial may end up creating and maintaining thousands of documents, such as the:
- Investigator’s brochure
- Consent forms given to subjects
- Insurance statements
- Authorizations from regulatory authorities
- CVs or resumes of the people involved
The TMF has been a requirement of GCP since its inception, so it’s not something that can be skipped. However, it can create a lot of challenges for the pharma company conducting the trial.
This article explores these challenges and explains why they are so problematic. It also highlights how a new Trial Master File Migration System from John Snow Labs can address these challenges with the help of Artificial Intelligence (AI) and Natural Language Processing (NLP).
The Challenges of Artifacts and Unstructured Data in a Clinical Trial’s TMF
For those involved in conducting a clinical trial, managing the TMF can be a highly complex endeavor. And there are many reasons for this.
Challenge #1: Multiple Content Zones
A typical TMF contains multiple content zones. These include:
- Central and Local Testing
- Central Trial Documents
- Data Management
- IP and Trial Supplies
- IRB or IEC and other Approvals
- Regulatory
- Safety Reporting
- Site Management
- Statistics
- Third parties
- Trial Management
For all these content zones, information must be compiled, populated, and maintained, which is both time-consuming and labor-intensive.
Challenge #2: Artifacts from Multiple Departments in Different Formats
Another factor that adds to TMF complexity is that it can include thousands of documents or artifacts originating from multiple departments outside clinical operations. These artifacts may be in different formats including Word, PDF, scanned PDFs, Excel with automatic formulae evaluations, and even PowerPoint presentations.
Such non-standardization makes it difficult to compile and compare documents. It’s even harder to quickly classify them or extract data from PDF, Word, Excel, etc., at scale since they contain a lot of unstructured, i.e., free text data.
Challenge #3: Involvement of Contract Research Organizations
The complexity increases even more if contract research organizations (CROs) are employed to conduct clinical research. CROs generate and maintain their own artifacts in their own formats, which once again, makes it tough to classify documents and extract key metadata or attributes from them.
Challenge #4: Migration to New Document Management Systems
The final challenge pertains to the migration of TMF artifacts from a legacy DMS (document management system) to a new DMS. Pharmaceutical organizations typically take on a migration project when they want to retire a legacy DMS. They may also have acquired another company or a drug that uses a different kind of DMS, and therefore need to migrate data from the acquired company’s DMS to their own DMS.
This exercise again requires a lot of manual effort and time – both of which can add up substantially when there are tens of thousands or hundreds of thousands of artifacts to be migrated.
The Need for an AI- and NLP-based Tool
Even one single clinical trial can generate thousands of documents. Human knowledge workers must classify these documents by type, and extract key attributes or metadata from them. They must also manually enrich the data to ensure that documents are fit for purpose, and map them correctly based on the TMF reference model. All of these activities take a lot of time and effort.
The cost and expense rise sharply when a large number of documents need to be migrated from unstructured or incompatible legacy systems to a target system, or when documents need to be enhanced with the metadata. That’s why this old manual system is not scalable or sustainable.
These issues also affect drug development pipelines. As the demand for drugs increases, pharmaceutical companies have to contend with lengthy development processes when they rely on manual labor to make sense of unstructured information in clinical trial artifacts.
An automation solution is needed to remove unproductive and inefficient manual effort, and improve output consistency and repeatability. However, automation with Robotic Process Automation (RPA) is not the answer. RPA bots are not “smart” enough to process the unstructured data in clinical trial documents. Only an AI- and NLP-based tool can help clinical trial investigators, sponsors, and others to effectively address all the challenges outlined above.
John Snow Labs has developed such a system. The AI- and NLP-based Trial Master File Migration System provides a structured, efficient, repeatable and scalable way to process TMF artifacts. The tool combines automation with content management to help clinical trial researchers and other personnel with:
- Based on AI / NLP – able to extract information if no proper rule is available, based on training data
- Classify documents and extract information
- OCR capabilities, handwritten detection, and recognition
- Language detection
- Instant and batch mode John Snow Labs Trial Master File Migration System
Key Features
Based on AI and NLP, this cutting-edge tool can classify all kinds of clinical trial documents, and extract a host of critical information to help trial investigators and researchers get the information they need to generate greater value from the trial.
But the system can do much more than simply classify artifacts or extract metadata. It is advanced enough to also detect the language in documents. It can also perform OCR (Optical Character Recognition) on scanned documents allowing trial investigators to easily access even more critical data types.
John Snow Labs’s intelligent tool removes the need for manual, monotonous, time-consuming TMF processing tasks. Its machine learning algorithms can extract rules automatically from documents to ensure both speed and consistency. The machine learning model can recognize wrong entities and detect false positives with a specific Machine Learning module.
Users can also add specific rules manually that the system will then “learn”. For example, a user can set a rule to teach the tool which data to extract from a document that has multiple dates. The tool can also augment data from third-party databases, such as the names of all the people and subjects involved in a clinical trial.
Benefits
The John Snow Labs clinical trial document migration and information extraction system is designed for organizations managing high volumes of clinical trial documentation. This includes:
- Pharma and biopharma companies
- Medical device manufacturers
- Consultancies
- Technical vendors
- Healthcare providers
- CRO companies
This AI-assisted document migration tool delivers fast, accurate, and consistent document migration and information extraction for large-scale clinical trial documents.
Compared to manual batch processing, classification, and mapping activities, this automated system shortens processing times and reduces the number of resources required to migrate documents or extract key information. It also delivers high accuracy and enables consistency and repeatability that manual processes just cannot ensure.
The tool consistently delivers:
- 80% time and labor intensity reduction
- Decrease in lead time to less than 6 months
Security and Compliance
The solution can be fully tailored for any pharmaceutical company that conducts large-scale clinical trials. It leverages both generic and project-specific components. The generic components are used for:
- Document classification pipelines
- Entity extraction pipelines
- Classifier models
- Named entity extraction models
- Handwritten recognition models
Specific components depend on the format of the TMF, the company, and their rules, documents, and requirements. For instance, for Novartis (see below), John Snow Labs delivered these project-specific components:
- Annotation guidelines
- Custom trained classification and entity extraction models
- Post-processing pipelines
- Detector of false positive results
- Vendor-specific GxP validation documentation
The post-processing pipeline is a particularly important component of the tool’s end-to-end process. It allows to implementation of custom rules defined by the company subject matter experts, e.g. what information should be extracted in case of a mismatch between metadata in the source DMS and information extracted from the document, or which data should be extracted if multiple data are present in the document.
Of course, the process doesn’t end there. After these software-driven steps, human quality control steps in to review output quality, and ensure that all exceptions and manual queues are handled effectively. Any feedback from this step is fed back into the post-processing step for even better results.
The TMF migration tool has a component for the detection of false positives. Thanks to AI assistance and a Machine Learning model, the system can detect false positives such as incorrect (i.e., wrongly classified or extracted) entries made in the target system or database. The input data for the machine learning model include, e.g., comparison of extracted values with existing metadata, information about hand-written recognized values along with the accuracy estimates, information about multiple names on a page, and information about names extracted from other sources than personnel sheets.
The tool also classifies results by “false positive” and “true positive”, and sends the false positives to the exception queue for manual (i.e., human) review. This is a critical feature because keeping the number of false positives low is critical in an automated classification and entity extraction tool for the healthcare sector.
These components are all supported by John Snow Labs’ licensed software:
- Spark NLP for Healthcare: Robust, accurate, fast and scalable NLP solution for healthcare and pharma
- Annotation Lab1: Software to quickly annotate large volumes of data
- Spark OCR: Highly accurate Optical Character Recognition (OCR) library to convert scanned documents to text. In addition, it has the ability to detect and recognize handwritten text and classify documents given a scanned image.
Know More About Spark NLP for Healthcare
Spark NLP for Healthcare is an award-winning NLP solution designed specifically for the healthcare sector. Healthcare organizations can easily use Spark NLP as part of their larger and scalable Machine Learning and Deep Learning pipelines in distributed environments. The Spark NLP library is the most widely-used NLP library in the world, with a wide installation base in healthcare and pharmaceuticals.
Spark NLP supports numerous healthcare NLP use cases, including clinical entity recognition, clinical entity linking, relation extraction, and assertion status. It comes with 200+ pre-trained models, is linked to a number of medical-specific terminologies, and incorporates multiple algorithms to help healthcare organizations and their users to, e.g.:
- De-identify text
- Classify unstructured documents and extract knowledge from them
- Clean up medical text with spell checks/corrections, stopword cleanups, and more
- Extract clinical entities
- Link extracted entities to standard ontologies (ICD-10, RxNorm, Snomed, etc)
- Assert presence and absence of the problem
- Extract relation between entities
- Spark NLP for Healthcare holds 9 top positions in the accuracy leaderboard of Papers With Code, a growing community and database of NLP and ML companies, developers, and papers. It is also trainable, tunable, and supported by a large community.
In addition, Spark NLP is:
- Fast: It takes care of the speed of the run, even on a single processor
- Hardware-optimized: John Snow Labs has partnered with Nvidia and Intel, the solution is coded in Scala to run fast even on a single processor.
- Scalable: Since the underlying technology is Apache Spark, Spark NLP can be easily scaled to large computer clusters
To know more about Spark NLP, explore our blog here.
The TMF migration tool is a turnkey solution where John Snow Labs manages the end-to-end deployment process, including:
- Preparing data guidelines
- Training custom components
- Verifying output
- Running production pipelines with:
- OCR
- Document classification
- Data extraction
- Data cleaning
- Quality control and manual queue handling

Case Study: Novartis
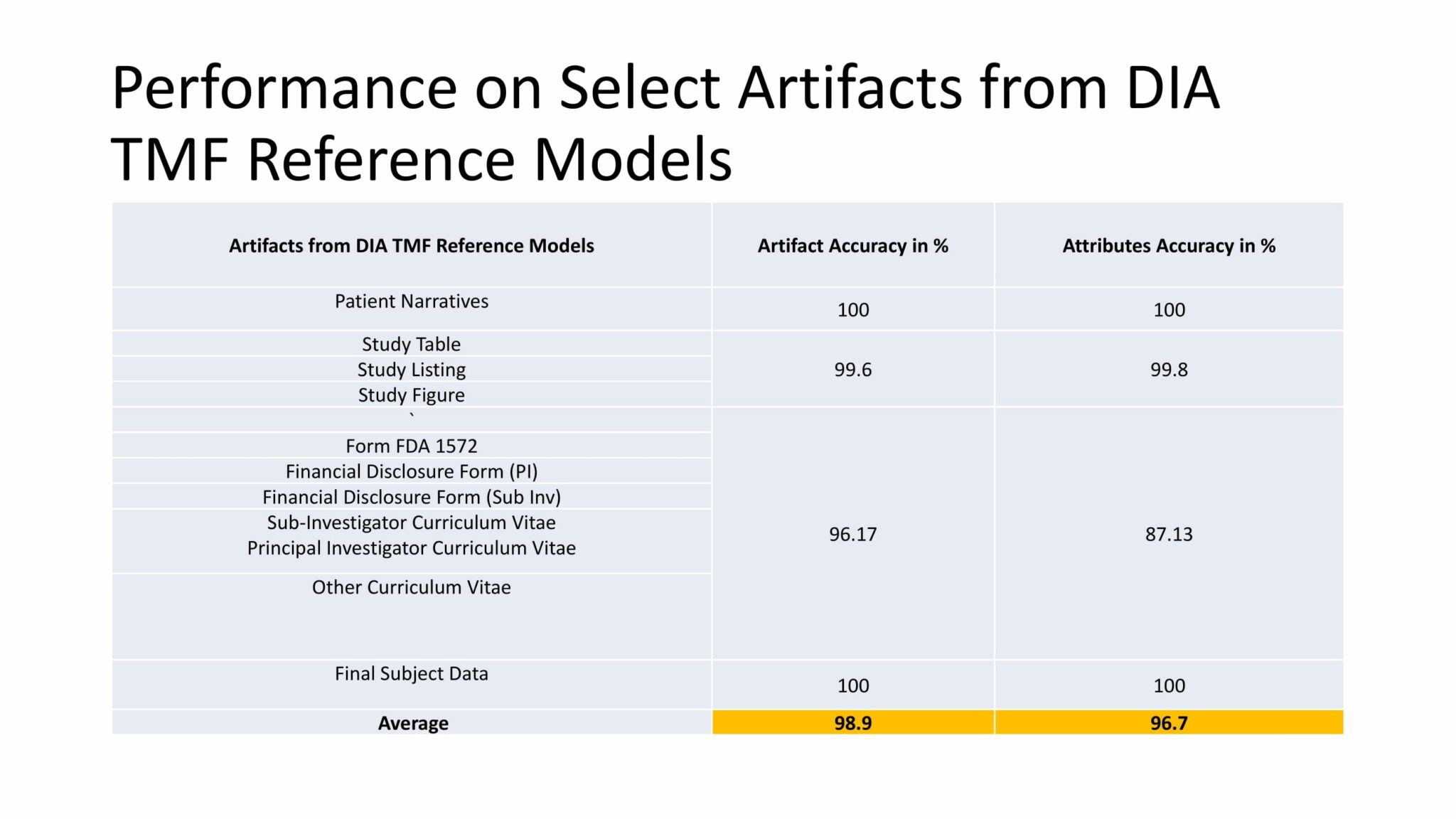
This AI/NLP system has already been successfully implemented at Novartis, one of the largest pharmaceutical companies in the world. The company successfully classified 48 artifacts of the TMF reference model and 29 attributes with this tool.
The artifacts included:
- Site staff qualification supporting information
- Sub-investigator CV
- FDA 1572
The attributes included:
- First name
- Last name
- Signature date
- Expiration date
- License date
Earlier, the Novartis team would rely on manual processes to classify the TMF artifacts and extract the required attributes from them. The process was slow, cumbersome and prone to errors. These issues were especially prevalent when:
- Different artifacts were saved in different formats
- Artifacts had different layouts
- Artifacts contained handwritten information
John Snow Labs’ NLP tool eliminated all these issues to ensure correct classification and accurate data extraction. It managed the development of the pipeline to create training data from unstructured data for its machine learning algorithm. It also ran the production pipeline to make highly accurate structured data available for the target system.
The tool delivered highly accurate results for a number of artifacts and attributes from the DIA TMF reference model.
The tool also helped the company save thousands of man-hours. Where earlier, processing 1 million documents would have taken 100 people 100 days, the tool brought the processing time for the same number of documents down to just 20 days.

In the long run, Novartis expects that this saved time and effort will have a tangible impact on the company’s drug development timelines, and enable them to bring life-saving drugs to more patients faster than ever before.
Conclusion
Every clinical trial generates vast quantities of data right from inception to the end of the study. Trial investigators, sponsors, and monitors often need to classify these documents, and extract key pieces of information from them to support their downstream processes and decision-making. But as document volumes increase, manual data processing is neither efficient nor sustainable. Automation is therefore required.
But most automated solutions only work with structured data. They cannot process the unstructured data in clinical trial documents. Here’s where the AI- and NLP-assisted tool from John Snow Labs is breaking new ground.
With its advanced automation capabilities backed by machine learning algorithms trained on millions of TMF documents, this tool vastly improves TMF processing speeds and output quality over manual methods. It also saves manual labor by up to 80%, and cuts cost by 80% or more.
To know more about the clinical trial document migration and information extraction system, contact John Snow Labs.