We are very excited to announce NLU 1.1.4 has been released and comes with a lot of tutorials showcasing how you can train a multilingual text classifier on just one starting language which then will be able to classify labels correct for text in over 100+ languages.
This is possible by leveraging the language-agnostic BERT Sentence Embeddings(LABSE). In addition to that tutorials for English pure classifiers for stock market sentiment, sarcasm and negations have been added.
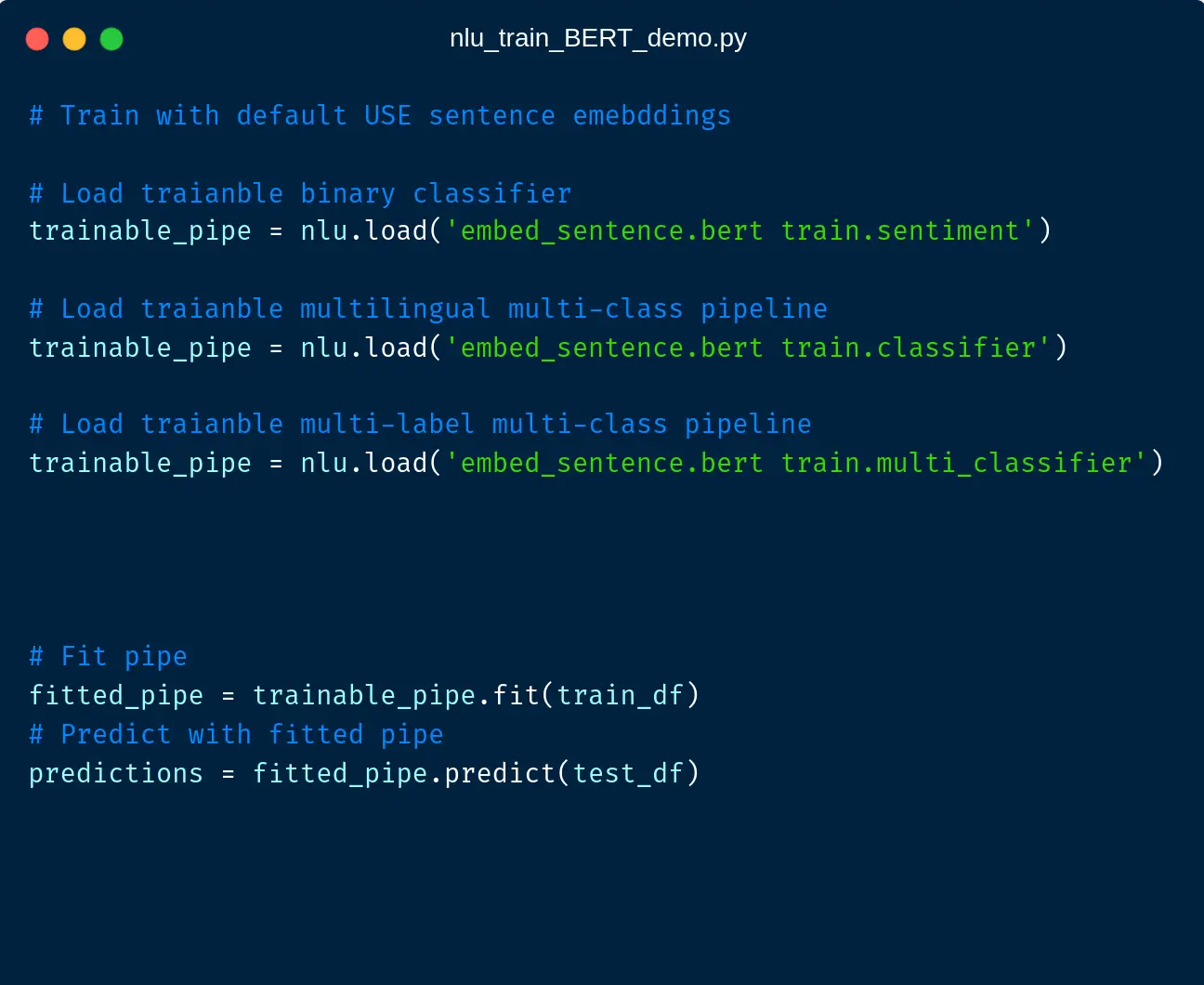
You can train a classifier with default USE embeddings in just 1 line
You can use any other embedding by specifying it before the classifier reference
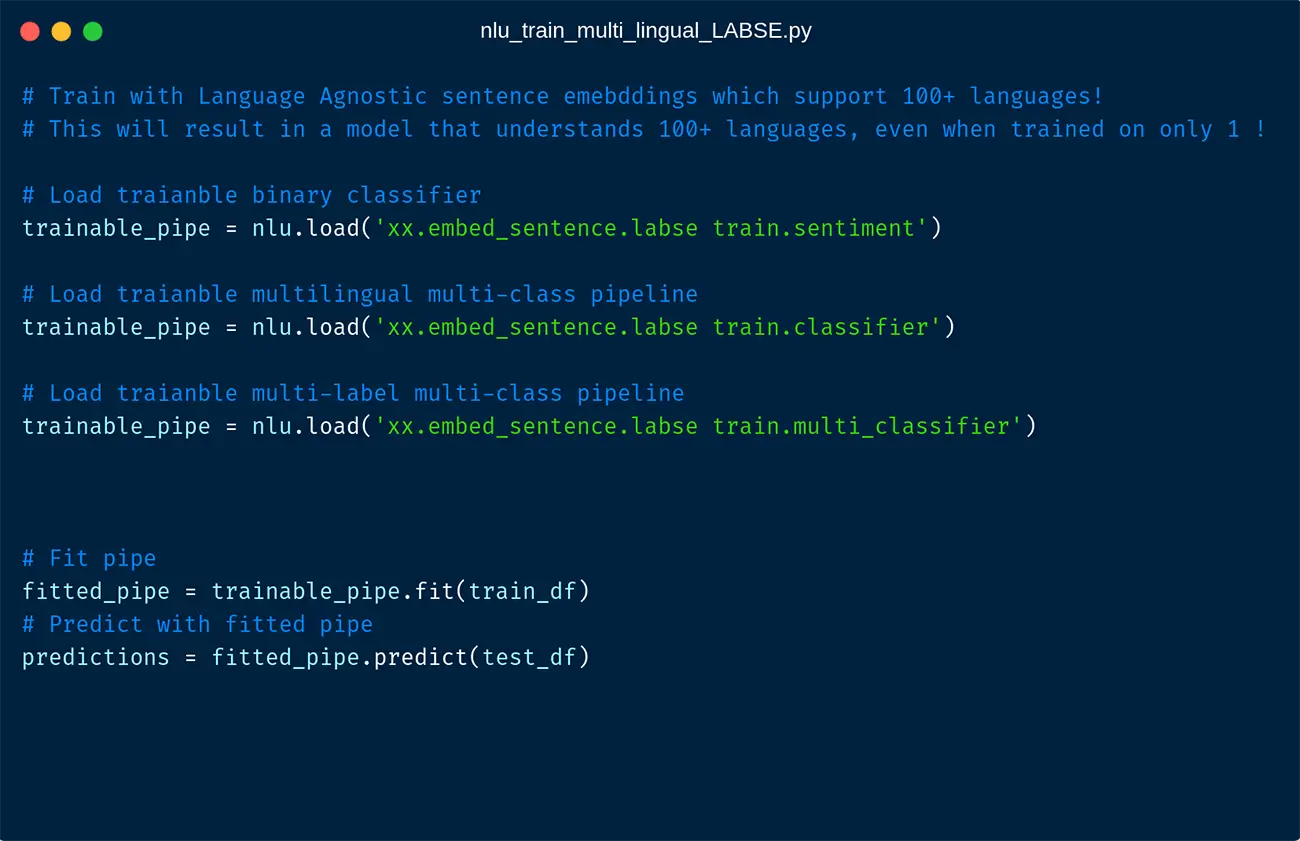
If you train with LABSE your model will understand 100+ languages, even if you train only in one language!
Finally, this release makes working in Spark environments easier, by providing a way to get a Spark DF, regardless of your input data.

New NLU Multi-Lingual training tutorials
These notebooks showcase how to leverage the powerful language-agnostic BERT Sentence Embeddings(LABSE) to train a language-agnostic classifier.
You can train on one start language(i.e. English dataset) and your model will be able to correctly predict the labels in every one of the 100+ languages of the LABSE embeddings.
- Multilingual Twitter Sentiment, binary classification (2class)
- Multilingual Stock Market Sentiment, binary classification (2class)
- Multilingual Reddit Comments Sentiment, binary classification (2class)
- Multilingual COVID19 Sentiment, binary classification (2class)
- Multilingual Apple Tweets Sentiment, binary classification (2class)
- Multilingual News classification, multi class classification (4class)
- Multilingual TripAdvisor Hotel Reviews, multi-class classification (3class)
- Multilingual Amazon Phone Reviews, multi-class classification (3class)
New NLU training tutorials (English)
These are simple training notebooks for binary classification for English
- Biological Texts Negation, binary classification (2class)
- News Headlines Sarcasm, binary classification (2class)
- COVID19 Sentiment, binary classification (2class)
- Natural Disasters Sentiment, binary classification (2class)
- Stock Market Sentiment, binary classification (2class)
- NLU Website
- All NLU Tutorial Notebooks
- NLU Videos and Blogposts on NLU
- NLU on Github
- Suggestions or Questions? Contact us in Slack!
- Models Hub with new models