
























































Spark NLP for Healthcare
There is a growing need for automated text mining of Electronic health records (EHRs) in order to find clinical indications that new research points to. EHRs are the primary source of information for clinicians tracking the care of their patients. Information fed into these systems may be found in structured fields for which values are inputted electronically (e.g. laboratory test orders or results) but most of the time information in these records is unstructured making it largely inaccessible for statistical analysis. These records include information such as the reason for administering drugs, previous disorders of the patient or the outcome of past treatments, and they are the largest source of empirical data in biomedical research, allowing for major scientific findings in highly relevant disorders such as cancer and Alzheimer’s disease. Despite the growing interest and groundbreaking advances in NLP research and NER (Named Entity Recognition) systems, easy to use production-ready models and tools are scarce in the biomedical and clinical domains and it is one of the major obstacles for clinical NLP researchers to implement the latest algorithms into their workflow and start using immediately. On the other hand, NLP tool kits specialised for processing biomedical and clinical text, such as MetaMap and cTAKES typically do not make use of new research innovations such as word representations or neural networks discussed above, hence producing less accurate results.
 Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomies
Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomies
 Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomies
Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomiesWe introduce Spark Healthcare NLP as the one-stop solution to address all these issues [2].
Commercial Clinical NLP Solutions (APIs)
There are already several commercial healthcare NLP solutions in the market but most of them are built and maintained by a small team of in-house developers to serve the daily needs of the company it is built for. In this study, we’ll explore publicly available, pay-as-you-go solutions developed and maintained by major cloud providers that use natural language processing to meet the challenge — Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health.

Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Since the data used by these services to train & fine-tune their own models is confidential, and given the fact that it is highly expensive and time-consuming to develop in-house datasets, we can strongly assume that apart from the proprietary in-house datasets, they must have included publicly available datasets as well for training purposes.
Comparison Setup and Methodology
As stated above, Spark NLP for Healthcare can extract and analyse 400+ different clinical & biomedical entities via 100+ NER models, 60+ Entity Resolution models from 10+ medical terminologies (ICD10, CPT-4, UMLS etc.), 50+ Relation Extraction models, 10+ Assertion Status Detection models and 40+ De-Identification models and pipelines. On the contrary, the number of entities and features of the major cloud providers are quite limited. The list of entities that can be extracted from these services vs what Spark NLP can extract can be seen in the image in the next section.
That is, Spark NLP can extract entities at a more granular level and it is tricky to make a 1:1 mapping to evaluate these services fairly. The cloud services also do not support all the taxonomies when it comes to entity resolution (only 3–4 different terminologies are supported at most) and details are not clear from their documentation. That is why we decided to create a set of entities and medical terminologies to run this comparison.
For this study, we had to find an open-source dataset for the reproducibility concerns and mtsamples.com looked like a perfect venue. MTSamples.com is designed to give you access to a big collection of transcribed medical reports and contains sample transcription reports for many specialities and different work types. At the time of writing this article, mtsamples.com hosts 5,003 Samples in 40 types. For this study, we randomly picked 8,000 clinical notes from various types and have human annotators (physicians having substantial experience in each domain) annotate all for named entity recognition and entity resolution tasks.
First of all, we annotated this test dataset within the annotation guideline that we used our most popular clinical NER model named ner_jsl. Then we applied the following mapping to indicate which entity from the new annotation corresponds to an entity from Spark NLP vs other cloud services.
 Entity mapping across various cloud services and Spark NLP
Entity mapping across various cloud services and Spark NLP
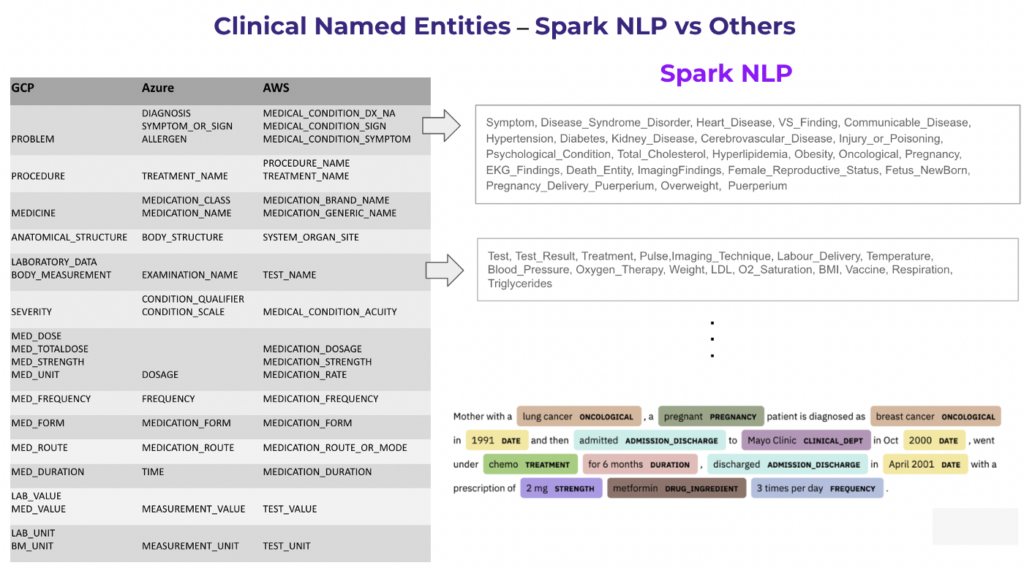 Entity mapping across various cloud services and Spark NLP
Entity mapping across various cloud services and Spark NLPAs our NER models are originally trained with a large set of the internally annotated datasets and we used several open source and proprietary datasets as well as academic ones like MIMIC-III, we wanted to make sure that the NER models we’ll be using to do this comparison haven’t seen the 8,000 sentences during training. So, we manually checked the original training set of our popular NER models (ner_jsl and ner_clinical_large) and dropped the overlapping sentences. We couldn’t do the same checks with the APIs provided by other cloud providers as they are all managed services with no information about the way they train their models. So, we will never know if they also used mtsamples.com to fine-tune their models or not but it is on us to make sure that we don’t have such a leakage for a fair comparison.
Comparison Results
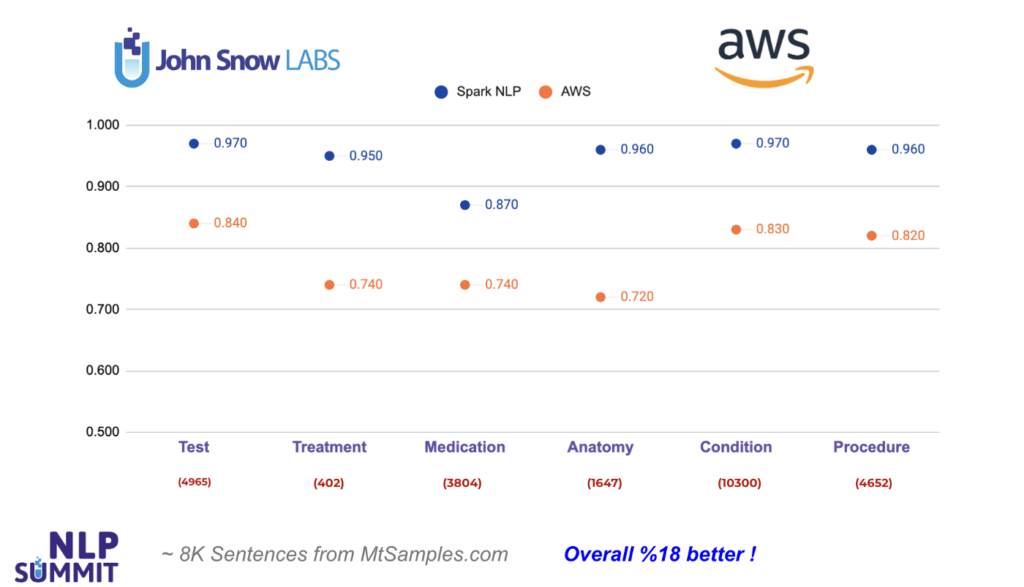
Let’s start with Amazon Medical Comprehend, one of the most popular healthcare NLP APIs out there. We managed to find 6 common entity types returned by AWS and mapped with the entities in Spark NLP using ner_jsl and ner_clinical_large models: Test, Treatment, Medication, Anatomy, Condition, Procedure.
As you can see from the chart below, Spark NLP does 13% better when it comes to Test entities, and 19% better in Treatment entities. The largest difference is observed in Anatomy entities by 24%. In all the entities compared, Spark NLP performs better in all of them, and exceeds AWS by 18% in average. The numbers in red puntos under each entity on the chart’s x-axis denote the number of tokens for the corresponding entity. That is, out of 10,300 Condition-labeled (clinical disorders, symptoms etc.) tokens, AWS fails to detect 1,300 of them while Spark NLP fails only with 300 of them (makes more than 4x less error).
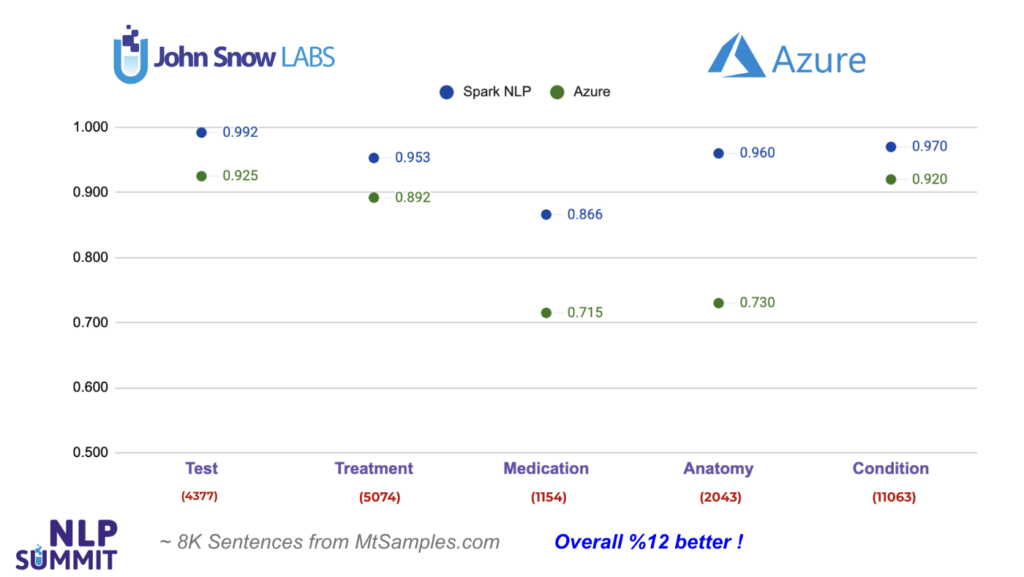
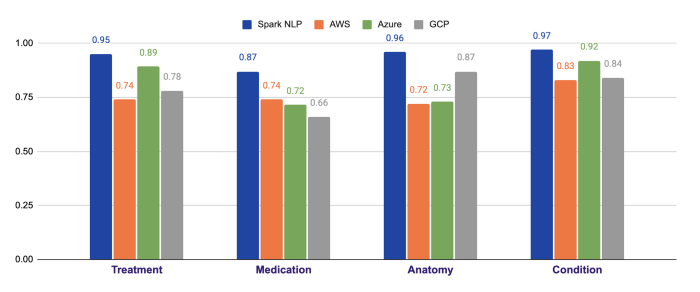
Next, we’ll study Azure Text Analytics for Health API. We see 5 common entity types returned by Azure that can be mapped with the entities in Spark NLP using ner_jsl and ner_clinical_large models: Test, Treatment, Medication, Anatomy, Condition.
As you can see from the chart below, Spark NLP does 7% better when it comes to Test entities, and 15% better in Medication entities. The largest difference is observed in Anatomy entities by 23%. In all the entities compared, Spark NLP performs better in all of them and exceeds Azure by 12% on average. For instance, out of 2,043 Anatomy-labeled (body parts) tokens, Azure fails to detect 550 of them while Spark NLP fails only with 80 of them (makes more than 6x less error).
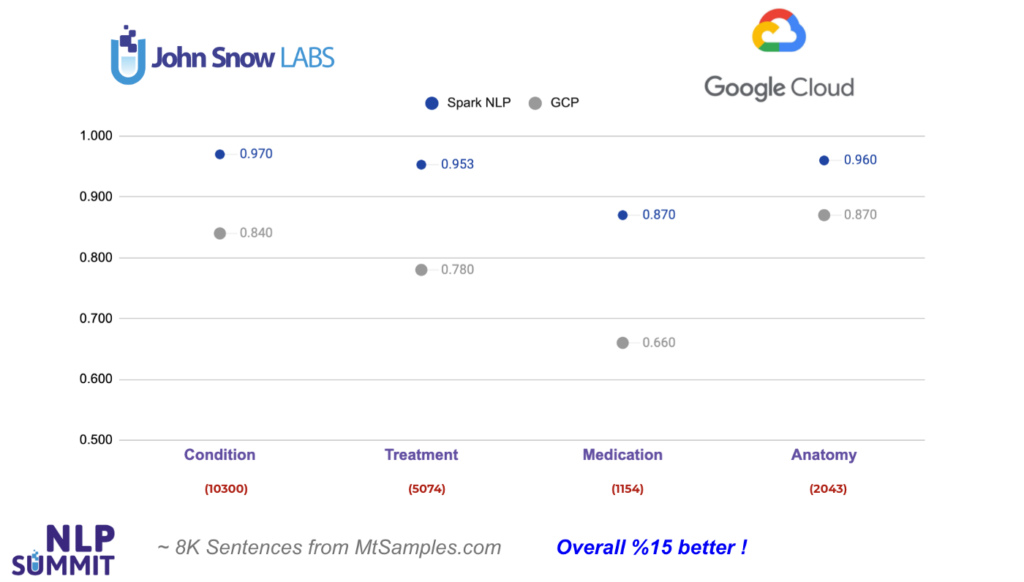
Finally, let’s check out Google Cloud Healthcare API. We see only 4 common entity types returned by GCP that can be mapped with the entities in Spark NLP using ner_jsl and ner_clinical_large models: Condition, Treatment, Medication, Anatomy.
As you can see from the chart below, Spark NLP does 13% better when it comes to Condition entities, and 17% better in Treatment entities. The largest difference is observed in Medication entities by 21%. In all the entities compared, Spark NLP performs better in all of them and exceeds GCP by 15% on average. For instance, out of 1,154 Medication-labeled (drugs, dosages etc.) tokens, GCP fails to detect 390 of them while Spark NLP fails only with 150 of them (makes more than 2x less error).
Here is the overall comparison of the common entities from all the other cloud APIs. As depicted clearly, Spark NLP exceeds each one of them by a large margin in all the entities compared.
In recent deployments, clinical teams have begun to pair high-recall NER with retrieval-augmented generation and ontology-grounded LLMs so that extracted spans are immediately contextualized with guidelines, labs, and longitudinal history. This hybrid pattern, NER → evidence retrieval → controlled generation, has improved downstream tasks like problem-list maintenance, HCC coding justification, and oncology trial matching on external validation sets in 2025, with measurable gains on rare and nested entities and fewer unsupported statements in summaries. The same approach is now used to “explain” extractions by linking each entity to provenance, which reduces manual review time and accelerates sign-off in clinical workflows.
Another notable shift is secure, privacy-preserving adaptation at the point of care. Hospitals are adopting on-prem and edge-friendly models that can be fine-tuned against de-identified notes using federated or differential-privacy techniques, while de-identification and re-identification pipelines keep the human in control. Synthetic clinical corpora conditioned on local case-mix are increasingly used to stress-test NER for corner cases, improving robustness without exposing PHI. Together, these practices allow health systems to meet stricter auditability requirements under emerging AI governance rules, while still achieving faster iteration cycles on specialty-specific models.
Evaluation has also matured from leaderboard F1 to task-level impact. Production teams now track calibration, abstention, and fairness across subpopulations, and they gate releases behind evidence of reduced false positives in safety-critical entities such as allergies and medications. Auto-updating entity resolvers that watch terminology changes (e.g., new codes, drug names) keep pipelines current without full retraining, and multi-stage validators flag contradictions between new extractions and structured EHR fields. The net effect observed across multi-institution rollouts in 2025 is higher coding yield with fewer denials, more reliable clinical summaries, and a clear path to continuous compliance.
Conclusion
Spark NLP for Healthcare comes with 600+ pretrained clinical pipelines & models out of the box and is performing way better than AWS, Azure and Google Cloud healthcare APIs by 18%, 12% and 15% (making 4–6x less error) respectively on extracting medical named entities from clinical notes. It’s also doing better consistently on entity resolution to map clinical entities to medical terminologies. Here are the other advantages of using Spark NLP for Healthcare against cloud APIs:
- Spark NLP for Healthcare offers highly customisable models and pipelines that can be shipped within the existing codebase while cloud APIs are basically black-box services that you should be OK with whatever you get in.
- The DL models shipped within Spark NLP for Healthcare can be fine-tuned and extended using the custom terminologies and new datasets annotated in-house.
- Spark NLP is the only NLP library out there that can scale over Apache Spark clusters to process large volumes of data.
- Spark NLP for Healthcare can work in air-gapped environments with no internet connection and requires no other dependency other than Spark itself. Given that Healthcare APIs offered by major cloud providers require an internet connection, this is a highly important aspect when it comes to preserving the privacy of sensitive information (PHI data) while running some analytics.
- Healthcare APIs offered by major cloud providers are pay-as-you-go solutions and can cost too much when it comes to processing a large volume of clinical texts. On the other hand, Spark NLP for Healthcare is licensed once and has no limitation in that regard. So, you can process TBs of clinical notes with the state of the art accuracy without paying anything other than the one-time annual license.
DO YOU WANT TO KNOW MORE?
- Check the example notebooks in the Spark NLP Workshop repository, available here
- Visit John Snow Labs and Spark NLP Technical Documentation websites
- Write to support@johnsnowlabs.com for any additional request you may have
FAQ
1. What’s the core takeaway of the benchmark?
Spark NLP for Healthcare consistently outperforms the major cloud APIs on common clinical entity types (e.g., Condition, Medication, Anatomy, Test, Treatment, Procedure), showing lower error rates and higher recall/precision on a clinician-annotated test set. This advantage is strongest for granular, domain-specific entities and when entity resolution to medical terminologies is required.
2. Why does Spark NLP do better on clinical text than generic cloud NLP?
Because it ships domain-specialized models trained and tuned on clinical corpora, supports far more medical entity types, and includes native components for assertion status, relation extraction, and entity resolution. In contrast, general cloud APIs expose fewer healthcare entities and taxonomies and operate as black-box services with limited customization.
3. How should teams evaluate NER beyond F1 score?
Pair standard metrics (precision/recall/F1) with task-level outcomes: coding yield and denials, allergy/medication false positives, chart-review time saved, and resolver accuracy against live code systems (ICD-10-CM, CPT, RxNorm, SNOMED CT, etc.). Track calibration, abstention (knowing when to defer), and fairness across subpopulations; gate releases on safety-critical error reductions.
4. Can I deploy these pipelines in a privacy-preserving way?
Yes. Spark NLP supports on-prem and air-gapped deployments, plus de-identification pipelines and federated/differential-privacy fine-tuning patterns. This helps meet auditability and PHI safeguards while enabling local adaptations (e.g., specialty-specific models) without sending data to external cloud services.
5. What’s the recommended production pattern with LLMs and knowledge sources?
Use high-recall NER to extract candidates, ground them with ontology-aware entity resolution, retrieve supporting evidence (guidelines, labs, prior notes), and then apply controlled generation for summaries or justifications. Add multi-stage validators to spot contradictions with structured EHR fields and auto-update resolvers as codes and drug names change. This boosts accuracy, explainability, and compliance in real workflows.




