Dia Trambitas is an AI Product Manager with deep expertise in Natural Language Processing and applied Generative AI. At John Snow Labs, Dia has led the development of the Generative AI Lab — a no-code platform for data annotation and model training — as well as the Medical Chatbot, a secure and domain-specific conversational AI assistant tailored for clinical environments. With a strong focus on practical deployments of cutting-edge AI, she has worked at the intersection of healthcare and technology, driving product innovation that empowers users to harness large language models safely and effectively. Passionate about transforming unstructured data into actionable insights, Dia brings a strategic and user-centered approach to building AI tools that are both powerful and accessible.
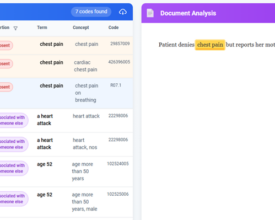
How the John Snow Labs Terminology Server converts unstructured clinical narratives into standardized, machine-ready medical codes, bridging the gap between narrative medicine and healthcare analytics. Every day, hospitals and health...
There's a quiet crisis in healthcare analytics. Organizations are spending millions on AI models, disease registries, population health programs, and clinical research, and many of them are doing it on...
In industries where strict regulatory standards govern operations, achieving full auditability and operational transparency is critical—not optional. Generative AI Lab addresses these critical requirements with a powerful set of enhancements...
Human-in-the-Loop (HITL) validation is critical to ensuring AI model outputs meet the highest standards of accuracy, compliance, and usability. Generative AI Lab is purpose-built to empower annotation teams to validate...
Introduction Healthcare organizations are under increasing pressure to improve the accuracy and efficiency of clinical documentation and risk adjustment. With the rise of value-based care, Hierarchical Condition Category (HCC) coding...



































































 See More
See More