























































A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
The Annotation Lab 1.6.0 focuses on enhancing the Models Training and Active Learning feature that we introduced in our last release. With this release, Annotation Lab supports Classification and Assertion Status Models training and task preannotation. To ensure a better user experience we have done some improvements related to Task Management. And as always we have continued to make the product more secure with security and bug fixes.
Check out all the new features and enhancements included in this release.
Highlights
This release includes support for training Classification and Assertion Status models. For any Classification project and Named Entity Recognition (with Assertion Status) project, a Project Owner/Manager can trigger training or configure the Active Learning feature from the Setup Page. The project can either be a simple Classification project or a simple NER project with Assertion Statuses defined or even include a mix of labels. The model training for such projects in Annotation Lab is as simple as clicking a button.

Multiple Training
If a project is set up to include classification, ner and assertion status labels and the three kinds of annotations are present in the training data, it is possible to train three models: one for NER, one for Assertion Status, and one for Classification at the same time. The training logs from all three pieces of training can be downloaded at once by clicking the download button present in the Training section of the Setup Page. The newly trained models will be added to the Spark NLP pipeline config.
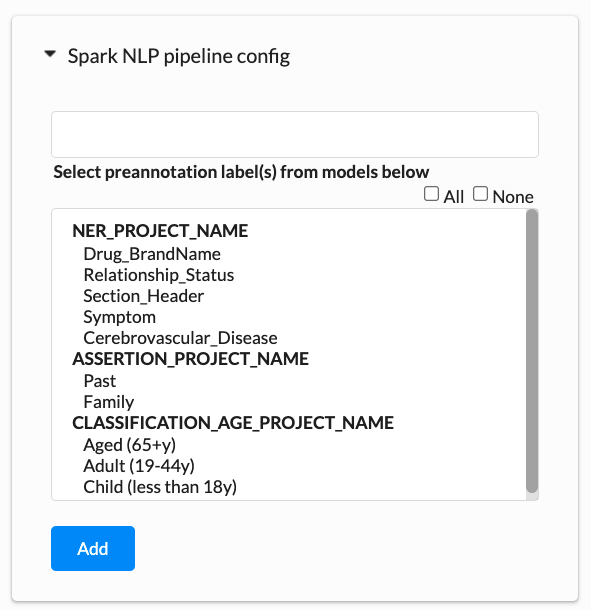
Assertion Project Models Training
The syntax for defining an Assertion Status label is the same as for the NER labels, with an additional attribute – assertion, which should be set to true (see example below). This is a convention defined by Annotation Lab users, which we exploited for identifying the labels to include in the training and prediction of Assertion Models.
A simple Labeling Config with Assertion Status defined should look like the following:

Notice assertion=”true” in Absent and Past labels, which marks each of those labels as Assertion Status Labels.
With a good amount of annotated data, the Assertion Status Model training can be started. After the training is complete, the model will be listed in the Spark NLP Pipeline Config. When hovered on the model in the list, we can see more information about it like when it was trained and if the training was manually initiated or by the Active Learning process.
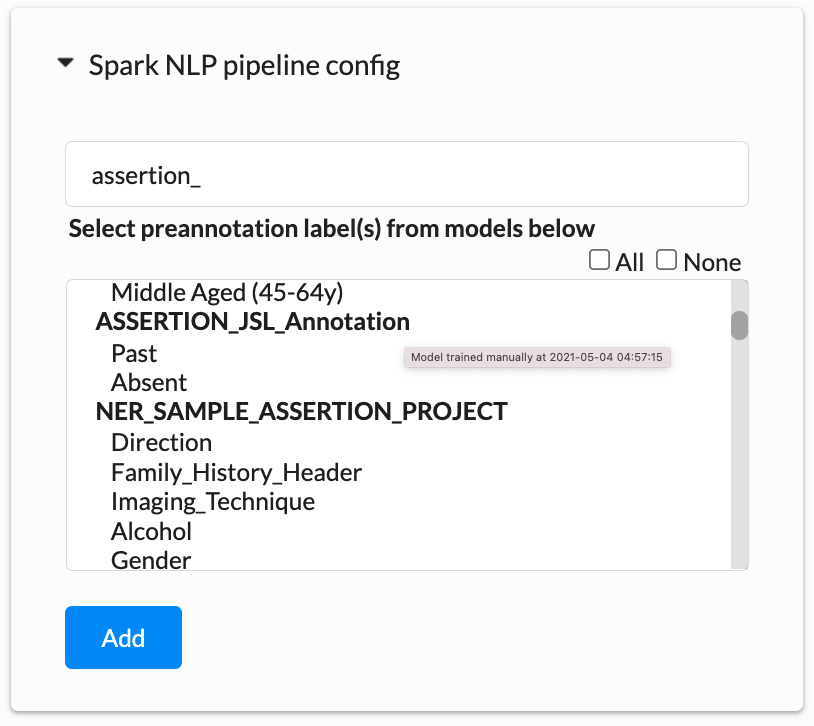
Once the model has been trained, the project configuration will be automatically updated to reference the new model for prediction. Notice below, for the Assertion Status <Label> tag the addition of model attribute to indicate which model will be used for task preannotation for this label.

It is not possible to mark a label as an Assertion Status label and use a NER model to predict it. A validation error is shown in the Interface Preview in case an invalid Assertion model is used.

The Annotation Lab only allows the use of one single Assertion Status model in the same project.

Classification Project Models Training
Annotation Lab supports two types of classification training Single Choice Classification and Multi-Choice Classification. For doing so, it uses three important attributes of the <Choices> tag to drive the Classification Models training and preannotation. Those are name, choice, and train.
Attribute name
The attribute name allows the naming of the different choices present in the project configuration, and thus the training of separate models based on the same project annotations. For example, in the sample configuration illustrated below, the name=”age” attribute, tells the system to only consider age-related classification information when training an Age Classifier. The value specified by the name attribute is also used to name the resulting Classification model (classification_age_annotation_manual).
Attribute choice
The choice attribute specifies the type of model that will be trained: multiple or single. For example, in the Labeling Config below, Age and Gender are Single Choice Classification categories while the Smoking Status is Multi-Choice Classification. Depending upon the value of this attribute, the respective model will be trained as a Single Choice Classifier or Multi-Choice Classifier.

Attribute train
This version of Annotation Lab restricts the training of two or more Classification Models at the same time. If there are multiple Classification categories in a project (like the one above), only the category whose name comes first in alphabetical order will be trained by default. In the above example, based on the value of the name attribute, we conclude that the Age classifier model is trained.
The model to be trained can also be specified by setting the train=”true” attribute for the targeted <Choices> tag (like the one defined in Gender category below).

The trained classification models are also available on the Spark NLP pipeline config list.
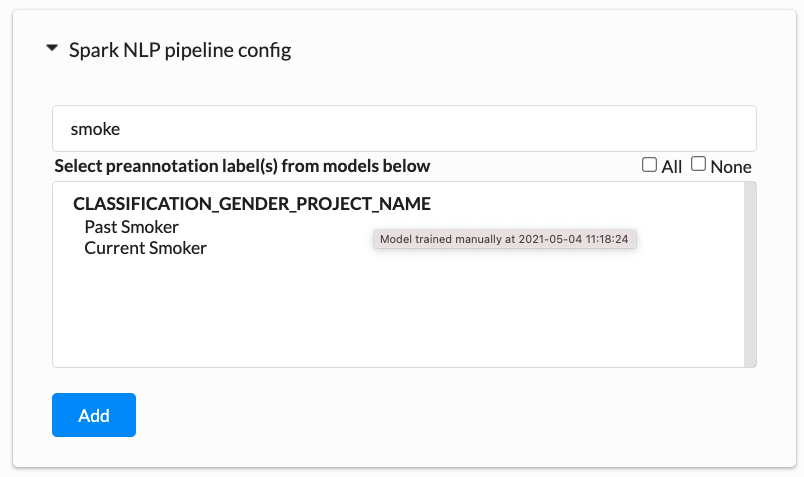
Preannotation
The Annotation Lab 1.6.0 offers support for any combination of NER, Assertion Status, and/or Classifications projects. Hence users can get classification, NER, and Assertion preannotations at the same time.
Though training two or more classification models in a single go is not possible at this point, the preannotation model server does support the preannotation using two or more classification models.
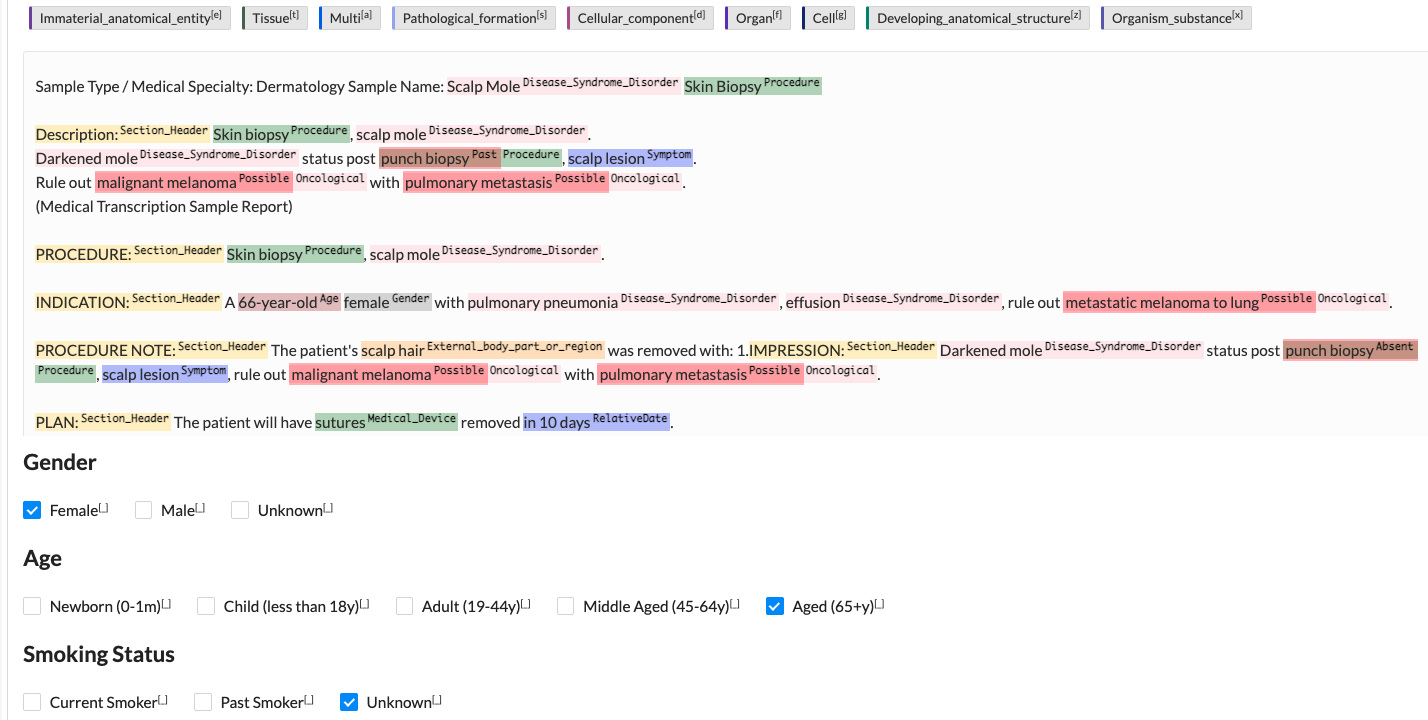
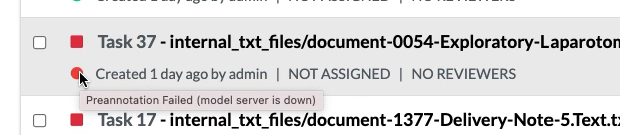
Information about the reason for failed preannotations on a given task is now available in the Task view, by hovering the mouse on the red circle which indicates the failure of preannotation.
Spark NLP version
All the model training and preannotations are using the Spark NLP library (v2.7.5).




