
























































In the era of large language models (LLMs)—where generative AI can write, summarize, translate, and even reason across complex documents—the function of data annotation has shifted dramatically. What was once a preparatory task for training AI is now a core part of a continuous feedback and improvement cycle.
Today’s annotation tools are no longer just for labeling datasets. They are indispensable for:
- Human-in-the-loop (HITL) validation of LLM outputs, ensuring that model-generated content is accurate, unbiased, and contextually appropriate.
- Auditing and correcting auto-generated annotations, identifying hallucinations, omissions, or formatting inconsistencies.
- Training compact, domain-specialized models that outperform general-purpose LLMs in areas like healthcare, legal, finance, and beyond.
- Building efficient models for edge deployment, where speed, interpretability, and hardware constraints matter as much as accuracy.
Why Text Annotation Still Matters—Even in the Age of Generative AI
Think of annotation like highlighting critical information in a medical report, legal brief, or technical manual. For an LLM, these labeled segments serve as the reference points from which it learns what’s important and how to reason about it. But with AI now capable of generating its own tags, summaries, or extractions, it’s fair to ask: why do we still need manual annotation?
Because even the most advanced models make subtle but serious mistakes—hallucinating facts, misclassifying sentiment, misidentifying relationships, or introducing bias. And they do it at scale.
While AI-assisted labeling has reduced some of the manual workload, modern annotation still demands:
- In-context validation of generative outputs, including structured reviews and scoring.
- Prompt iteration and tuning, ensuring that zero-shot tasks produce consistent results.
- Feedback loops for retraining, enabling task-specific models to continuously learn from expert corrections.
High-quality annotations—especially those created by domain experts—form the backbone of safe, accurate, and deployable AI. They enable organizations to move beyond “good enough” general models and toward tailored systems that are faster, cheaper, and more aligned with real-world needs.
The Road Ahead for Annotation Tools
To support this shift, annotation platforms are evolving rapidly. The best ones combine ease of use, automation, and human insight in a unified interface—empowering cross-functional teams to train, test, and improve AI systems in production settings.
In the sections that follow, we compare six of the most advanced annotation tools—each re-evaluated for its strengths in HITL workflows, generative model evaluation, and domain-specific AI development:
1. Generative AI Lab by John Snow Labs
A Full Stack No-Code platform for Human-in-the-Loop, AI-Assisted Annotation and Model Training
The Generative AI Lab is uniquely positioned for today’s LLM-centric workflows. Designed with a special focus on healthcare specific tasks while still remaining generally applicable, it brings together AI-based preannotation, human and automatic results evaluation, prompt engineering, and model training/tuning—all with no coding required. John Snow Labs’ Generative AI Lab is a comprehensive no-code platform designed to facilitate document labeling and AI/ML model training. It enables domain experts, such as healthcare professionals, legal advisors, and financial analysts, to extract meaningful information from text documents, images, or PDFs and train models to automate these tasks.
Key Features
- AI-Assisted Annotation: Leverages pre-trained models to streamline the annotation process, reducing manual effort and boosting efficiency. It can be applied to text, image or PDF documents, seamlessly recognizing text without the need for in-house OCR, making it an ideal solution for diverse data types.
- Supported Annotation Tasks: Out-of-the-box support for a wide variety of annotation types including: Named Entity Recognition (NER), Classification (multi-class and multi-label), Assertion Status (presence/absence/conditional), Relationship Extraction, Entity Resolution (linking entities across sources), Text Summarization, Dialogue, Segmentation (audio, video), Content Rating
- Prompt Engineering + LLM Review Loops: Refine zero-shot prompts and validate generative outputs in context. Especially powerful when pairing domain experts with GPT-style models to validate entity extraction or summarization.
- No-Code Model Training: Empowers users to train and fine-tune AI models on as few as 40–50 examples per label, without writing code. Ideal for creating domain-specific models for NER, relation extraction, de-identification, and classification. AI development becomes accessible to non-technical professionals.
- De-Identification of PHI & PII: Dedicated projects templates for automatic detection and removal of sensitive patient information from text, ensuring compliance with privacy regulations like HIPAA while enabling secure AI research and data sharing. Those templates are customizable both terms of entities they cover and on de-identification strategy.
- Comprehensive Resource Hub: Provides download access to over 100K pre-trained models, reusable custom rules, and prompts —enabling rapid deployment, experimentation, and iteration. It also allows you to securely store trained models within the platform, with built-in versioning support to track model evolution and ensure reproducibility across experiments.
- Supported Content Types: Annotate across a wide range of formats including text, PDF, image, video, audio, and HTML.
- Enterprise-Grade Security: Runs securely on-prem, in air-gapped environments, or via cloud marketplaces (AWS/Azure). Supports SSO, full audit trails, and annotation versioning—essential for regulatory use cases.
- Project and Team Management: Enables seamless project creation and team collaboration with unlimited user support. Features include task assignment, tagging, comments, consensus analysis, and performance dashboards, ensuring efficient workflow and real-time progress tracking.
Ideal Use Case
Designed for healthcare, finance, and legal teams that require high-performance, explainable language models with clear and robust audit trails. Perfect for building production-ready, low-latency AI solutions that meet strict regulatory and compliance standards.
2. SuperAnnotate
A Flexible Platform for Multi-Modal Data and ML-Powered QA
SuperAnnotate is an end-to-end data annotation platform designed to help businesses create high-quality training datasets for AI and machine learning (ML) models. It supports various types of data, including text, images, and videos, making it a versatile tool for different AI applications such as natural language processing (NLP).
Key Features
- Powerful text annotation tool: Produce precise and high-quality text annotations with multiple options. The options include sentiment analysis, summarization, translation, named-entity recognition, text classification, question answering, and token annotation.
- Built-in UI builder: Build custom annotation and evaluation UIs or team-wide dashboards and applications to fit your workflow.
- Extensive quality assurance review: Data undergoes a thorough and effective evaluation through a multi-level QA process. The QA process is automated and automatically advances data to the next stage once approved or sends it back for further review if necessary.
- Orchestrate for automation: Automates routine, manual, repetitive, and time-consuming tasks. Orchestrate can also be used to manage trigger actions and pipelines.
- Advanced search: Use vector-powered similarity and natural language search to explore your dataset. Effortlessly browse through annotations, predictions, and metadata to find the exact information you need.
- Comprehensive data security: Prioritizes security and privacy of your data using IP whitelisting, signed URLs, native integrations, 2FA, and SSO. It also uses a secured on-premises infrastructure to store and manage data on local storage.
- Annotations types and Annotation content type: SuperAnnotate offers robust image and video annotation tools, including bounding boxes, polygons, keypoints, and semantic segmentation. It also supports text classification, NER, audio transcription, and PDF annotation. You can work with images (JPEG, PNG), videos (MP4), plain text, audio files (WAV, MP3), and PDFs.
Ideal Use Case
Teams needing scalable annotation pipelines for mixed media with strong quality assurance and customizable interfaces.
3. Annotation Studio from Dataloop
Designed for Versatile Media and Semi-Automated NLP Labeling
A platform designed to annotate text, images, video, audio, documents, and LiDAR. It has an easy-to-use interface to switch between each of these data types and effectively annotate your desired data. Additionally, it also offers annotation options for image segmentation, NLP, PDF, RLHF, and GIS.
Key Features
- Label picker: Allows annotators to assign predefined labels to specific elements or objects in the text data.
- Parent-Child Relationship: Create hierarchical relationships between different annotations. It can help to show complex data structures with ease.
- Auto next item: Enhance workflow efficiency by automatically progressing to the next text item when a single label is applied. Once a label is applied, it saves automatically and loads the next item.
- Paragraph delimiter: Defines how text is segmented for annotation where users can set a custom delimiter, such as a space, enter key, or any character. Once set, each annotation applies to the entire delimited section.
- Annotation filters: Quickly sort and display specific annotations based on predefined criteria. The criteria are based on the annotation type, annotation status, and annotation properties.
- Robust security controls: Top-tier data privacy and security by adhering to the “Principle of Least Privilege”. Its security measures include role-based access control, 2FA, data encryption, logging and monitoring, security tests and reports, SSO, and disaster recovery and backup.
- Annotations types and Annotation content type: Dataloop covers a wide range of use cases—image and video annotation with advanced features like instance segmentation, LiDAR and GIS support for 3D and geospatial data, and text/audio tasks like classification and NER. It supports a wide array of formats: images, videos, text, audio, PDFs, LiDAR (.pcd, .las), and GIS files.
Ideal Use Case
Multi-modal AI projects that require iterative validation and support for RLHF or complex document structures.
4. Label Studio
Open Source and Built for Integration
A good choice for researchers and teams building tightly coupled ML pipelines. Its extensibility and open-source nature make it a strong foundation for experimental or custom validation setups. It offers configurable layouts and seamless integration with your ML/AI pipeline through webhooks, APIs, and cloud storage.
Key Features
- ML-assisted labeling: Automatically suggest labels based on the ML model’s prediction. The predictions from the ML model can also be automatically accepted without manual review with auto-annotation.
- Customizable labeling interface: Customize the labeling interface to fit your specific use case. Configure settings such as keeping a label selected after creating a region, displaying labels on bounding boxes, polygons, and other regions, or showing line numbers during text labeling.
- Project Management: Label Studio provides only basic project organization features, lacking several capabilities needed for structured, scalable team workflows. It does not support organizing projects into workspaces, managing project-level roles, or restricting access through membership controls—limiting administrative oversight and secure collaboration. Furthemore, there is no fine-grained user configuration at the project level. These gaps make the platform less suitable for larger teams or enterprise environments that require modular project governance, role-based access, and guided setup experiences.
- Security limitations: While Label Studio offers flexibility and robust functionality, it lacks critical enterprise-grade security features, making it less appropriate for use in regulated industries like healthcare or finance without significant internal support. The absence of SSO integration (SAML or LDAP) complicates secure user management and increases authentication risks, while the lack of SOC2 compliance poses challenges for organizations with strict data security, auditing, and compliance standards.
- Quality workflow limitations: Label Studio lacks essential quality control and workflow management features that are critical for maintaining high annotation standards at scale. It does not support assigning reviewers, measuring annotator agreement, or automatically reassigning low-quality tasks—making it harder to ensure consistent labeling accuracy. Features like ground truth identification, overlap configuration, and annotation limits are also missing, which limits the ability to validate data quality and manage annotator performance effectively. Additionally, the absence of team collaboration tools (e.g., comments and notifications), consensus matrices, and dataset distribution insights further restricts its suitability for complex or enterprise-grade annotation workflows.
- Annotation types and Annotation content type: Versatile open-source platform supporting multiple data modalities, including text, images, audio, video, and time series. It offers a range of annotation types: for images, it supports semantic segmentation, object detection, and keypoint detection; for text, it provides tools for NER, classification, and sentiment analysis; for audio, it enables transcription and sound event detection; and for video, it offers object tracking and timeline segmentation.
Ideal Use Case
Research teams and startups building custom workflows for LLM evaluation or training.
5. CVAT
For Vision-Based Annotation with Light NLP Support
CVAT (Computer Vision Annotation Tool) is an open-source data labeling and annotation tool designed for machine learning and artificial intelligence workflows. It is primarily used to annotate visual data such as images, videos, and 3D models to train machine learning models for computer vision tasks.
Key Features
- Support for various annotation types: Supports image classification, object detection, semantic and instance segmentation, point clouds/LIDAR, 3D cuboids, video annotation, and skeleton annotations.
- Auto-Annotation: Uses AI models to speed up the annotation process by automatically suggesting labels, increasing annotation efficiency.
- Integration with Machine Learning workflows: CVAT is built with machine learning professionals in mind. So, it provides tools for annotation that seamlessly integrate into the broader ML pipeline.
- Custom annotation templates: Design the interface to suit specific text annotation tasks. Create fields for annotations, such as keywords, tags, or relationships between pieces of text.
- Export and import annotations: Once annotations are made in CVAT, they can be exported in formats compatible with text-based machine learning tools (e.g., JSON, CSV). This makes it easy to integrate the annotated data with ML pipelines or other text-processing workflows.
- OPA for user access control: Open Policy Agent (OPA) is integrated with CVAT as a microservice that makes policy decisions based on queries sent by CVAT. It determines whether actions are allowed or denied according to predefined policies.
- Annotations types and Annotation content type: CVAT is built for computer vision and excels at image and video annotation with tools like bounding boxes, polygons, cuboids, and masks. It also handles 3D point cloud annotations. Supported formats include various image types (JPEG, PNG, TIFF), videos (MP4, AVI), and point cloud files (.pcd, .las).
Ideal Use Case
Vision-heavy AI teams that need occasional NLP support or hybrid annotation tasks (e.g., visual question answering, OCR + text labeling).
6. Prodigy
Lightweight and Developer-Centric
Developed by the makers of spaCy, Prodigy is focused on data scientists and developers looking to rapidly iterate on custom NLP models using real-world examples.
Key Features
- Custom AI systems for information extraction: Build custom AI systems for text annotation by focusing on real-world examples that define your specific needs. Create effective AI solutions without requiring expertise in machine learning.
- Language model training: Create better, faster, and fully private text annotation pipelines by incorporating expert workflows and the latest best practices. Build transparent AI systems that use domain-specific knowledge from both large models and human experts.
- Transform PDF into AI-ready data: Extract structured data from PDF documents or convert scanned images into text using OCR. Efficiently combine image and text-based annotation tasks to streamline the process of turning raw data into usable, labeled datasets for machine learning.
- Prompt engineering: Identify and refine the best annotation prompts for a given task. Tests different prompts on real-world data to evaluate the prompts that are most effective at guiding annotators in labeling text accurately.
- SSO with OpenID Connect (OIDC): Authenticate using existing organizational credentials to improve security by reducing the need for multiple passwords and providing a centralized dauthentication system.
- Annotations types and Annotation content type: Prodigy is ideal for fast, iterative NLP and ML data labeling. It focuses on text (NER, classification, sentiment, POS tagging), with image support for bounding boxes and classification, and audio for transcription and classification. It works with plain text, images (JPEG, PNG), and audio formats.
Ideal Use Case
Teams that want to build compact, specialized models using expert-labeled examples and run everything locally.
Choosing the Right Tool for Modern AI Workflows
Now that we’ve looked at their major features, let’s compare the tools with each other to select the most suitable one for you. To choose the best text annotation tool for you, you must answer the following questions:
- What content do I need to process?
- How can I automate the annotation process and how do I test the accuracy of my model?
- Do I need a Data Scientist to train/tune my model?
- How do I keep my data safe?
- How do I manage my team and projects?
Supported Content Types
The foundation of any annotation project lies in evaluating the input documents—both their content type (text, video, or audio) and the labeling tasks required (e.g., named entities, relations, bounding boxes, etc.).

When comparing tools for multimodal support, John Snow Labs’ Generative AI Labeling Tool stands out for text and image-based workflows—particularly for specialized use cases like OCR text extraction from images. As highlighted in the comparison table, competing tools offer comparable support for core data types but may lack this extended functionality.
AI-Assisted Annotation
In evaluating AI-assisted annotation tools, John Snow Labs’ Generative AI Lab distinguishes itself by offering a comprehensive suite of advanced features not commonly found in other platforms. The Generative AI Lab notably supports model testing, custom de-identification pipelines, local zero-shot prompts, OpenAI prompts, synthetic task generation, and Hierarchical Condition Category (HCC) coding reviews. These capabilities enable domain experts to train, tune, and test AI models without coding, facilitating efficient and accurate annotation processes.
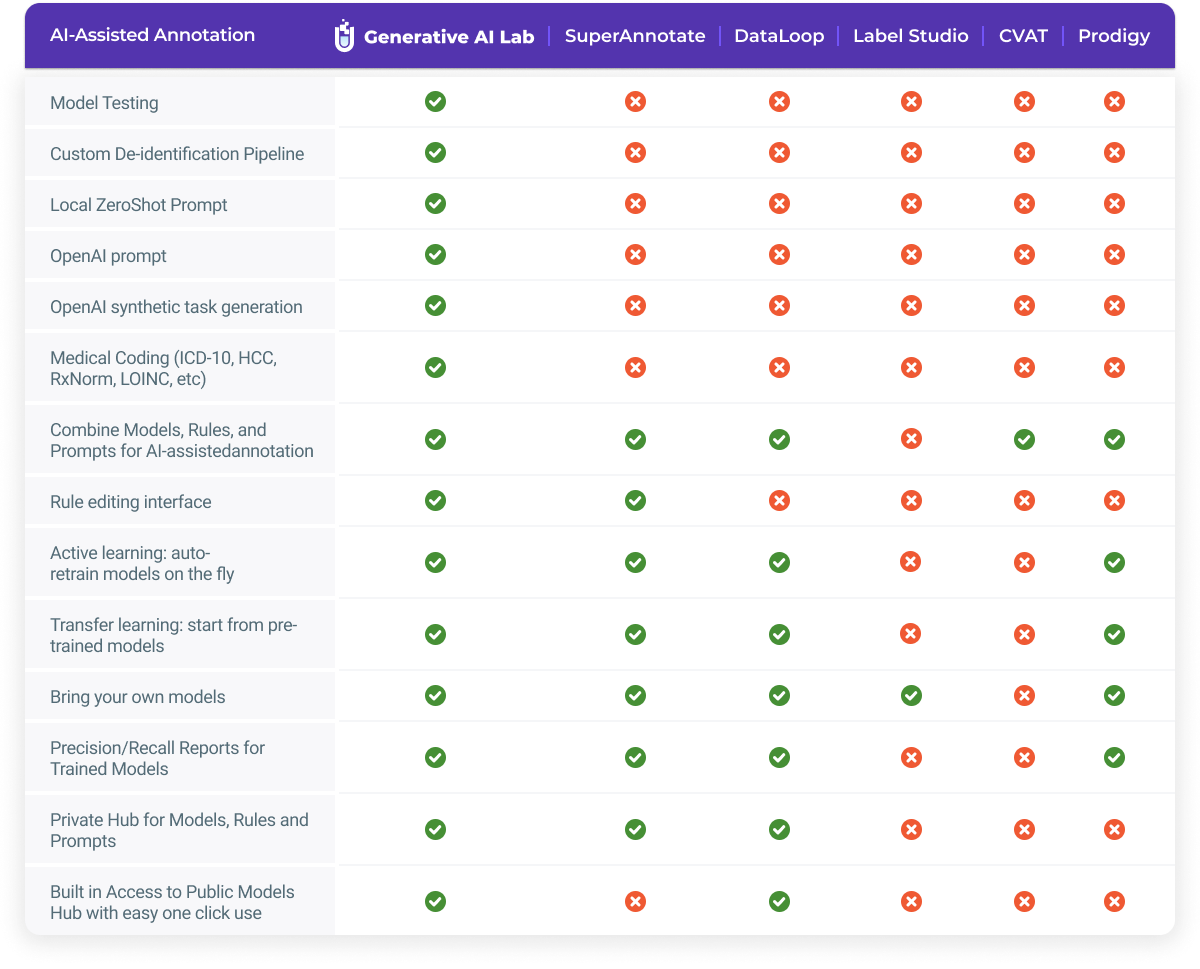 Additionally, the Generative AI Lab provides a rule editing interface, active learning for dynamic model retraining, transfer learning from pre-trained models, integration of custom models, precision/recall reporting, and model hub integration. These features collectively enhance the platform’s versatility and performance in natural language processing tasks across various industries. In contrast, while platforms like SuperAnnotate and DataLoop offer some of these functionalities, they do not encompass the full range of features available in the Generative AI Lab.
Additionally, the Generative AI Lab provides a rule editing interface, active learning for dynamic model retraining, transfer learning from pre-trained models, integration of custom models, precision/recall reporting, and model hub integration. These features collectively enhance the platform’s versatility and performance in natural language processing tasks across various industries. In contrast, while platforms like SuperAnnotate and DataLoop offer some of these functionalities, they do not encompass the full range of features available in the Generative AI Lab.
Finally, Generative AI Lab is a high-performance engine for natural language processing, fine-tuned for specialized domains like healthcare, finance, and legal work. While other tools handle general labeling tasks, the Lab supercharges annotation with deep learning, making it a top choice for teams that need both speed and domain expertise.
LangTest for Model Testing
John Snow Labs’ Generative AI Lab doesn’t just keep up with the competition—it outpaces them with a game-changing feature: built-in model testing via the LangTest framework. While other platforms leave you guessing about your AI’s reliability, Generative AI Lab actively stress-tests models for robustness, fairness, and real-world performance.
How It Works:
- Rigorous Testing: LangTest runs your model through a battery of evaluations—like adversarial attacks, bias checks, and edge cases—so you know exactly where it struggles.
- Self-Improving AI: Failed a test? The platform automatically generates augmented data to retrain your model, closing gaps without manual hassle. Just hit “Improve Test Results” and let it work.
- No More Blind Spots: Unlike tools that stop at basic accuracy metrics, this tests how your model handles tricky, varied, or sensitive scenarios—critical for production-ready AI.
Why It Matters:
Other platforms make you cobble together testing solutions. Generative AI Lab bakes it right in, turning what’s usually a painstaking chore into a seamless part of the workflow. The result? Stronger and faster models with proof they’ll hold up under pressure.
No Code Model Training
John Snow Labs’ Generative AI Lab is a no-code platform that enables domain experts to train AI models for tasks such as Named Entity Recognition (NER), Visual NER, assertion status detection, classification, and relation extraction without writing any code. Once sufficient training data is annotated—typically 40–50 examples per entity—users can initiate model training either from scratch or by fine-tuning existing pre-trained models. The platform also features active learning, automatically triggering model training upon reaching predefined milestones, such as 50, 100, or 200 new annotations.
Security and Privacy
When you’re labeling enterprise data, chances are you’ll run into sensitive information like PII or PHI—and that means security and privacy can’t be an afterthought.
 John Snow Labs’ Generative AI Lab stands out for its strong focus on security and privacy, offering features like granular role-based access, annotation versioning, detailed audit logs, seamless LDAP/Active Directory integration, single sign-on (SSO) support, and flexible deployment options (including on-premise and air-gapped setups). When compared to other tools, John Snow Labs provides a more robust and well-rounded security framework, especially in key areas like tracking annotation changes, maintaining audit trails, and integrating with enterprise authentication systems. This makes it a compelling choice for organizations prioritizing data security and compliance.
John Snow Labs’ Generative AI Lab stands out for its strong focus on security and privacy, offering features like granular role-based access, annotation versioning, detailed audit logs, seamless LDAP/Active Directory integration, single sign-on (SSO) support, and flexible deployment options (including on-premise and air-gapped setups). When compared to other tools, John Snow Labs provides a more robust and well-rounded security framework, especially in key areas like tracking annotation changes, maintaining audit trails, and integrating with enterprise authentication systems. This makes it a compelling choice for organizations prioritizing data security and compliance.
Projects and Teams
When working on complex data extraction and validation projects, tasks are typically distributed among a team of domain experts, including annotators and reviewers. Effective project management requires a robust software tool that facilitates task assignment, tracking, and quality assurance. Clear annotation guidelines are critical in such workflows, and Generative AI Lab addresses this by allowing users to attach detailed instructions to each label, ensuring consistency and clarity during the annotation process.
Among the six tools in this comparison, John Snow Labs’ Generative AI Lab offers the most comprehensive suite of project management and collaboration features.
While other annotation tools support essential functions such as multiple project management and API access, their capabilities are often limited in standard editions. For instance, task assignment, a critical feature for managing team-based projects, is standard in Generative AI Lab but varies across other platforms like SuperAnnotate, Dataloop, Label Studio, and CVAT.
The gap is even more pronounced when considering collaboration features. Key functionalities such as consensus analysis, feedback and comment tracking, built-in review workflows, and performance dashboards are readily available in Generative AI Lab, but are less present in the competitor solutions.
 Thus, for teams requiring an all-in-one annotation platform with seamless project management, label-specific guidance, and collaboration capabilities, Generative AI Lab stands out as the most feature-rich and accessible choice.
Thus, for teams requiring an all-in-one annotation platform with seamless project management, label-specific guidance, and collaboration capabilities, Generative AI Lab stands out as the most feature-rich and accessible choice.
Final Thoughts
Modern AI workflows require more than labeling—they require continuous validation, iterative improvements, and training smaller models that outperform general-purpose LLMs on narrow tasks. Whether you’re building PHI de-identification models or validating LLM summarization in legal documents, your choice of annotation platform can accelerate or bottleneck your pipeline.
Among all, John Snow Labs’ Generative AI Lab emerges as the most comprehensive solution for LLM-centric workflows. It enables human feedback at scale, audit-ready fine-tuning, and enterprise-grade deployment—all without writing a single line of code. It’s built for both data scientists and domain experts, with all features available through both a user interface and API.
Let the right annotation tool do the heavy lifting—so your team can focus on building better, faster, and safer AI!




