






















































Are you curious about the groundbreaking advancements in Natural Language Processing (NLP) and LLM? Ever wondered how machines can understand, predict and generate human-like text using open source technologies and cloud computing? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. In this comprehensive overview, designed for data scientists and enthusiasts alike, we will explore the definition, significance, and real-world applications of these game-changing models, highlighting their role in the evolving landscape of NLP and LLM.

What are Large Language Models (LLMs)?
A large language model (LLM) is an advanced AI algorithm using deep learning and vast data to read, understand, summarize, recognize, translate, and generate content in different languages with remarkable accuracy. These models are trained on massive datasets, encompassing billions of sentences, to capture the intricate nuances of language.
At their core, LLMs are built upon deep neural networks, enabling them to process vast amounts of text and learn complex patterns. They employ a technique known as unsupervised learning, where they extract knowledge from unlabelled text data, making them incredibly versatile and adaptable to various NLP tasks.

Imagine a scenario where a customer needs help understanding their recent credit card statement. Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time.
The Large Language Model (LLM) understands the customer’s intent, extracts key information from their query, and delivers accurate and relevant answers. It can interpret complex questions, address specific concerns about transactions, provide explanations of fees or charges, and even suggest suitable financial products based on the customer’s needs.
Moreover, LLMs continuously learn from customer interactions, allowing them to improve their responses and accuracy over time. They can adapt to new industry trends, regulatory changes, and evolving customer needs, providing up-to-date and relevant information.
In the table below, you can find the list of large language models and their development date.
History of large language models
| Year | Model | Developer | Key Features |
| 1966 | ELIZA | Joseph Weizenbaum | First large language model, simulating a psychotherapist, basic pattern matching techniques. |
| 1988 | PARRY | Kenneth Colby | Aimed to simulate a person with paranoid schizophrenia, more advanced than ELIZA in conversation. |
| 2003 | GPT | OpenAI | Early generative model, foundational for future GPT developments. |
| 2018 | BERT | Google AI | Bidirectional training, excels in understanding context in language processing. |
| 2019 | GPT-2 | OpenAI | 1.5 billion parameters, improved text generation capabilities. |
| 2020 | T5 | Google AI | Text-to-Text approach, treating every NLP task as a text generation problem. |
| 2020 | GPT-3 model | OpenAI | 175 billion parameters, advanced text generation, capable of zero-shot learning. |
| 2021 | Jurassic-1 | AI21 Labs | 178 billion parameters, focuses on specific applications like content creation and coding assistance. |
| 2022 | GPT-4 | OpenAI | Multimodal abilities, handling both text and images, improved context understanding. |
| 2023 | LaMDA | Specialized in conversational AI, focusing on generating more natural and sensible responses. | |
| 2023 | LLaMA | Meta | Emphasizes on efficiency and scalability, with fewer parameters but high accuracy. |
The components of large language models
Large language models consist of several neural network layers, including recurrent, feedforward, embedding, and attention layers, which collaboratively process and generate text.
- Embedding layers transform input text into embeddings, capturing its semantic and syntactic essence for contextual understanding by the model.
- Feedforward layers, comprising multiple fully connected layers, transform these embeddings, allowing the model to extract higher-level abstractions and grasp the user’s intent.
- Recurrent layers sequentially interpret words in the text, understanding the relationships within sentences.
- Attention mechanisms in these models focus on specific parts of the input text crucial for the task, ensuring precise output generation.
Common types of large language models, including private large language models:
- Zero-shot models: These broad-spectrum models, trained on diverse datasets, are capable of delivering reasonably accurate outcomes across a range of general applications without additional training. GPT-3 is a notable example of a zero-shot model, often used in both public and private settings.
- Fine-tuned or domain-specific models: Building upon zero-shot models like GPT-3, these models receive additional training for specific fields, making them ideal for private sector applications where specialized knowledge is crucial. OpenAI Codex, tailored for programming, is a prime example, derived from GPT-3.
- Language representation models: BERT (Bidirectional Encoder Representations from Transformers) represents this category, utilizing deep learning and transformers. It’s highly effective for natural language processing tasks and can be adapted for private use in specific industries.
- Multimodal models: Initially text-focused, LLMs have evolved into multimodal models capable of processing both text and images, suitable for private applications requiring complex data interpretation. GPT-4 is an advanced example of this type.
- Private Large Language Models: These are customized versions of LLMs, tailored to specific organizational needs. They are trained on proprietary data, ensuring confidentiality and alignment with specific business goals. Private LLMs are ideal for industries handling sensitive information, like medical LLM or finance, where data privacy is paramount.
Some scientists additionally identify these types of models by large language models architecture and the way they work:
- Autoregressive LLM (GPT-3);
- Transformer-based models (RoBERTa);
- Encoder-decoder LLM (MarianMT);
- Pre-trained and fine-tuned models (ELECTRA);
- Multilingual (XLM);
- Hybrid models (UniLM).
It is also customary to distinguish between foundation models which are trained on broad data and can be applied across a wide range of fields and specific ones. The term “foundational models” was created by The Stanford Institute for Human-Centered Artificial Intelligence’s (HAI) Center for Research on Foundation Models (CRFM).
Significance of Large Language Models (LLMs) in NLP
The advent of Large Language Models (LLMs) has revolutionized the field of NLP, unlocking numerous possibilities and transforming the way machines interact with human language. Let’s explore the significance of these models in detail:
- Enhanced Language Understanding: LLMs possess an extraordinary ability to comprehend and interpret human language. Language understanding models can decipher context, extract meaning, and discern the subtle nuances of grammar and semantics. They can decipher context, extract meaning, and discern the subtle nuances of grammar and semantics. This breakthrough enables machines to understand and respond to text in a more human-like manner.
- Contextual Word Representations: Traditional language models often treat words as isolated entities, but LLMs go a step further by considering the context in which words appear. By capturing contextual information, LLMs create dynamic word representations that adapt to the specific meaning of a word within a given sentence or document. This contextual understanding greatly improves the accuracy and relevance of language processing tasks.
- State-of-the-Art Language model’s NLP Performance: LLMs have set new benchmarks in various NLP tasks, including sentiment analysis, question-answering, machine translation, text summarization, and more. Their ability to leverage massive amounts of training data and learn intricate language patterns empowers them to outperform traditional models and achieve unprecedented results.
- Transfer Learning Capabilities: One of the most significant advantages of Large Language Models (LLMs) is their transfer learning capabilities. Pre-trained on massive corpora, LLMs acquire a deep understanding of language, which can be fine-tuned for specific downstream tasks. This transfer learning approach significantly reduces the need for large task-specific datasets, making it easier and more efficient to develop NLP applications.
- Time and Cost Efficiency: By utilizing LLMs, organizations can save substantial time and resources in developing and fine-tuning NLP models from scratch. The pre-trained models serve as a solid foundation, requiring only fine-tuning for specific tasks, reducing the development cycle and associated costs.
- Automation and Scalability: LLMs enable automation of various NLP tasks, eliminating the need for manual intervention. They can process and analyze large volumes of text data efficiently, enabling scalable solutions for text-related challenges in industries such as customer support, content generation, and data analysis.
- Improved Decision Making: LLMs provide valuable insights from unstructured text data, enabling better decision making in domains like finance, healthcare, and marketing. They can analyze customer feedback, market trends, and industry news to derive actionable intelligence, leading to more informed and data-driven decisions.
- Enhanced Accuracy and Performance: LLMs have significantly improved the accuracy of NLP tasks compared to traditional models. They leverage vast amounts of pre-training data and can capture complex language patterns and semantics, resulting in more accurate predictions and better performance across different tasks.
Popular Large Language Models (LLMs)
As natural language processing (NLP) continues to advance, several large language models (LLMs) have gained significant attention and popularity for their exceptional capabilities. In this section, we will provide an overview of popular language models BERT and GPT, and introduce other examples of large language models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna.
Overview of BERT (Bidirectional Encoder Representations from Transformers)
BERT, short for Bidirectional Encoder Representations from Transformers, is a revolutionary LLM introduced by Google in 2018. BERT excels in understanding context and generating contextually relevant representations for a given text. It utilizes the Transformer architecture and is pre-trained on a massive amount of unlabeled text from the web.
BERT’s uniqueness lies in its bidirectional approach, which allows it to capture the context from both preceding and succeeding words. This bidirectional understanding significantly enhances its ability to comprehend nuanced language structures, leading to improved performance in various NLP tasks such as text classification, question answering, and named entity recognition.
Overview of GPT (Generative Pre-trained Transformer)
GPT, short for Generative Pre-trained Transformer, is a widely known and influential large language model developed by OpenAI. It is designed to generate human-like text by predicting the next word or token in a sequence based on the context provided. GPT utilizes the transformer architecture, which allows it to capture long-range dependencies in text and generate coherent and contextually relevant responses.
GPT is trained in an unsupervised manner on a vast amount of publicly available text from the internet. This pre-training phase enables the model to learn the statistical properties of language, including grammar, semantics, and even some level of reasoning. The model’s ability to generate high-quality text has made it popular in various natural language processing (NLP) tasks such as text completion, question answering, and text generation.
Comparison of BERT and GPT
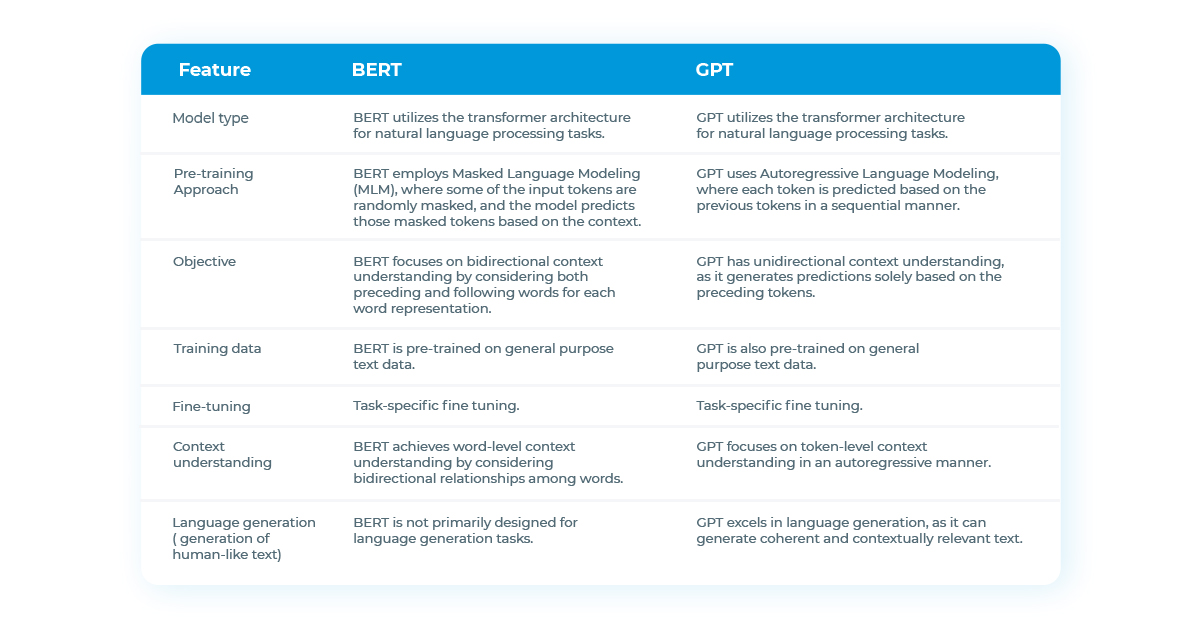
Newer Versions of GPT
GPT-2, the precursor to subsequent versions like GPT-3, GPT-3.5, and GPT-4, marked a significant advancement in the field of large language models. Released by OpenAI, GPT-2 demonstrated impressive capabilities in generating coherent and contextually relevant text.
- GPT-2: With GPT-2, OpenAI boasted a vast number of parameters, enabling it to capture intricate patterns and dependencies in the data. One of the standout features of GPT-2 was its ability to generate high-quality text across various domains. Its text generation capabilities covered a wide range of applications, including creative writing, content generation, and language understanding tasks.
- GPT-3: It is known for its remarkable text generation abilities and has achieved significant advancements in generating human-like text. GPT-3 has been used for various creative applications, such as generating stories, poetry, and even computer code.
- GPT-3.5: This version further enhances the language generation capabilities of GPT-3, offering improved coherence, context understanding, and a more nuanced writing style. GPT-3.5 has demonstrated exceptional performance in generating high-quality text for a wide range of applications.
- GPT-4: Building upon the strengths of its predecessors, GPT-4 aims to take large language models to new heights. With even larger model sizes, improved training techniques, and better contextual understanding, GPT-4 promises to deliver more accurate and contextually coherent text generation across various domains.
These newer versions of GPT continue to drive innovation and open up exciting possibilities in natural language processing, content generation, and other NLP applications.
Introduction to Other Popular Models
In addition to well-known models like BERT and GPT, there are several other popular large language models (LLMs) that have made significant contributions to the field of natural language processing. These models exhibit powerful capabilities and have been instrumental in various NLP applications. Let’s explore some of these noteworthy models briefly:
- T5 (Text-to-Text Transfer Transformer): T5 is a state-of-the-art model developed by Google Research. The pre-training approach of T5 involves training the model to solve a variety of text-based tasks using a “text-to-text” format. It is trained on large-scale datasets containing examples of various NLP tasks, including text classification, summarization, translation, question-answering, and more. This approach allows T5 to learn general-purpose language representations that can be adapted to specific tasks through fine-tuning.
- Pythia: Pythia is a vision and language LLM developed by EleutherAI. It is designed to excel in the field of question-answering and natural language understanding. Pythia is built on the powerful Transformer architecture, which has proven to be highly effective in various natural language processing tasks. The model is trained using a large corpus of text data, allowing it to understand and generate human-like responses to questions. Pythia leverages advanced techniques such as pre-training and fine-tuning to achieve high levels of accuracy and fluency in its responses.
- Dolly: Dolly is an LLM developed by Databricks. It is designed to understand and generate human-like text based on the context provided. With a model size of 12 billion parameters, Dolly possesses a significant capacity to capture intricate patterns and dependencies in textual data. It has been trained on a large corpus of text data, enabling it to generate coherent and contextually relevant responses to various prompts. Dolly’s training involves advanced techniques such as pre-training and fine-tuning, which enhance its ability to understand and generate high-quality text across multiple domains and applications. The model has been evaluated on various benchmarks, demonstrating its proficiency in language understanding and generation tasks.
- Bloom: Bloom is an autoregressive Large Language Model (LLM) developed by BigScience. It has been trained on massive amounts of text data using industrial-scale computational resources. With its autoregressive nature, Bloom excels at continuing text from a given prompt, generating coherent and human-like output. One of the remarkable aspects of Bloom is its versatility in generating text across a wide range of languages. It supports 46 languages, enabling users to generate text in their preferred language. Additionally, Bloom demonstrates proficiency in generating text in 13 programming languages, making it a valuable tool for code generation and related tasks.
- Falcon: Developed by Technology Innovation Institute (TII-UAE), Falcon is trained on an extensive corpus of text data. It exhibits impressive language generation capabilities and can generate text with remarkable coherence and context understanding. With a model size of 40 billion parameters, Falcon represents a significant advancement in large-scale language models. It leverages its vast capacity to capture intricate language patterns and nuances, resulting in text that closely resembles human-generated content. Falcon supports a wide range of natural language processing tasks, including text generation, sentiment analysis, question answering, and more. Its extensive training enables it to understand and generate text in multiple languages, making it a versatile tool for multilingual applications.
- StarCoder: StarCoder is a set of powerful Large Language Models (LLMs) developed by BigCode. These models, with a staggering parameter count of 15.5 billion, have been meticulously trained on an extensive dataset comprising over 80 programming languages extracted from The Stack (v1.2). It’s worth noting that the training data excludes opt-out requests, ensuring privacy and compliance. Utilizing advanced techniques like Multi Query Attention, StarCoder exhibits a deep understanding of diverse programming languages and their syntax. The models leverage a wide context window of 8192 tokens, allowing them to capture long-range dependencies and contextual information crucial for accurate code generation.
- Orca: Orca is an impressive LLM developed by Microsoft AI. It is designed to understand and generate text with high accuracy and coherence. It exhibits a deep understanding of language semantics, enabling it to grasp complex contextual information and produce meaningful responses. With its extensive training on diverse datasets, Orca has demonstrated remarkable proficiency across various language-related tasks. One notable aspect of Orca is its ability to generate text in multiple languages. The model has been trained on a wide range of multilingual data, allowing it to effectively handle diverse language inputs and produce coherent and contextually appropriate text outputs.
- LLAMA (Large Language Model Meta AI): LLAMA is developed by the FAIR (Facebook AI Research) team of Meta AI. It is an auto-regressive language model based on the transformer architecture that comes in different sizes: 7B, 13B, 33B and 65B parameters. LLAMA has shown promising results in several language-based applications. It can be used for generating text, summarizing documents, answering questions, and assisting in language translation. Its large parameter size and extensive training enable it to generate text that is contextually coherent and exhibits a high level of language understanding.
- Vicuna: It is an LLM developed by the Vicuna team with members from UC Berkeley, CMU, Stanford, and UC San Diego. The model comes in different sizes: 7B, 13B, 33B and 65B parameters. By leveraging the transformer architecture, Vicuna can effectively process and generate text, enabling interactive and dynamic conversations with users. Its training on real-world conversations allows it to understand and respond to a wide range of user inputs. These models showcase the wide range of applications and capabilities of large language models (LLMs) beyond BERT and GPT. Each model addresses specific NLP challenges and contributes to advancing the field of natural language understanding and generation.
Applications of Large Language Models (LLMs) in NLP
Large Language Models (LLMs) have diverse applications across multiple fields, enhancing Natural Language Processing (NLP) capabilities:
- Large Language Models in Healthcare: Analyzing patient records, interpreting clinical notes, and summarizing medical literature.
- Biomedical Large Language Models: Drug discovery through research paper and clinical trial data analysis.
- Legal: Legal document analysis, contract review, and case law research.
- Customer Support: Powering chatbots for quick, accurate customer responses and feedback analysis.
- Finance: Analyzing financial documents, market trend insights, and understanding complex regulations.
- Banking: Personalized financial advice, fraud detection, and customer query processing.
- Marketing: Content creation, market analysis, and customer sentiment analysis.
- Education: Personalizing learning materials, grading, and identifying learning gaps.
- Retail: Product description generation, customer reviews analysis, and shopping assistance.
- Human Resources: Resume analysis, automating candidate responses, and onboarding assistance.
- Entertainment: Scriptwriting, content recommendation, and viewer feedback analysis.
- Travel and Hospitality: Travel planning assistance, booking help, and personalized recommendations.
Large language models (LLMs) have revolutionized the field of natural language processing (NLP) by enabling a wide range of applications. In this section, we will explore some popular use cases of LLMs and delve into the benefits they bring to the table.
Text Generation and Summarization with Large language models (LLMs)
LLMs have revolutionized the field of text generation and summarization by enabling the creation of coherent and contextually relevant text. They can generate human-like articles, stories, and even code snippets. LLMs like OpenAI’s GPT-3 have been used to generate creative pieces of writing. They can mimic different writing styles and produce engaging stories, poems, and essays. For example, GPT-3 has been utilized to write compelling narratives, generate fictional characters, and even compose music lyrics.
LLMs can generate news articles on various topics by analyzing existing news articles and understanding the context. For instance, The Guardian, a renowned British newspaper, used an LLM to automatically generate summaries of articles related to the 2020 Olympics. This allowed them to provide readers with quick and informative summaries of the latest news.
Large Language Models (LLMs) have been employed to enhance the conversational capabilities of chatbots and virtual assistants. They can generate dynamic and contextually appropriate responses to user queries, resulting in more engaging and natural conversations. For example, Microsoft’s XiaoIce, a Chinese chatbot, utilizes LLMs to generate personalized responses and engage users in interactive conversations.
John Snow Labs utilizes Large Language Models (LLMs) in NLP to generate coherent and contextually relevant text. By fine-tuning these models, they enable automated text generation for various applications, such as content creation, chatbots, and personalized summaries.
Large language models (LLMs) for Question Answering
LLMs have significantly advanced the field of Question Answering (QA) in NLP, allowing machines to comprehend and respond to natural language questions accurately. Large Language Models are utilized in virtual assistants and chatbots to provide accurate and relevant answers to user queries. These systems employ large language models to understand the context and semantics of the questions asked and generate appropriate responses. For instance, Google Assistant, powered by LLMs, can answer a wide range of user queries, including general knowledge, weather updates, directions, and more.
LLMs are employed in customer support systems and help desks to provide automated responses to user inquiries. They can understand the intent of the user’s question and extract relevant information to generate helpful answers. For example, large e-commerce platforms often utilize LLM-powered chatbots to answer customer queries about product specifications, shipping details, and return policies.
Leveraging LLMs, John Snow Labs develops question answering systems that can comprehend and provide accurate answers to user queries. By utilizing pre-trained models and fine-tuning them on specific domains, they enable effective retrieval and extraction of information from textual data.
Sentiment Analysis using Large language models (LLMs)
LLMs have been leveraged for sentiment analysis tasks, where they can determine the sentiment (positive, negative, or neutral) expressed in a given piece of text. Large Language Models (LLMs) leverage their advanced natural language processing capabilities to accurately determine and classify sentiment, enabling businesses and organizations to gain valuable insights from customer feedback, social media posts, reviews, and other forms of text data.
Here’s how LLMs are used for sentiment analysis:
- Understanding Context: LLMs excel at capturing the contextual information and semantics of text, allowing them to comprehend the sentiment expressed in a more nuanced way. They can decipher the underlying sentiment behind words, phrases, and even complex sentence structures.
- Fine-grained Sentiment Analysis: Large Language Models (LLMs) enable fine-grained sentiment analysis by classifying text into multiple sentiment categories such as positive, negative, neutral, or even more granular categories like very positive, slightly negative, etc. This level of granularity provides a deeper understanding of sentiment distributions within the text.
- Domain-specific Sentiment Analysis: LLMs can be trained on domain-specific datasets, making them capable of performing sentiment analysis tailored to specific industries or domains such as finance, healthcare, or e-commerce. This specialization allows for more accurate sentiment classification within specific contexts.
- Transfer Learning: Large Language Models (LLMs) leverage transfer learning, which involves pre-training the model on a large corpus of general text data and then fine-tuning it on domain-specific or task-specific datasets. This transfer learning approach enhances the model’s performance and reduces the need for extensive training data for every specific sentiment analysis task.
- Real-time Analysis: LLMs can handle real-time sentiment analysis, providing businesses with the ability to monitor and analyze sentiment in near real-time. This enables timely response and intervention, allowing organizations to address customer concerns, identify emerging trends, or evaluate the success of marketing campaigns promptly.
John Snow Labs utilizes Large Language Models (LLMs) to perform sentiment analysis on large volumes of text. By training these models on labeled sentiment datasets, they can classify text into positive, negative, or neutral sentiments. This helps businesses gauge public opinion, analyze customer feedback, and monitor brand reputation.
Large Language Models in Machine Translation
LLMs have revolutionized the field of language translation by significantly improving the accuracy and quality of automated translation systems. LLMs utilize their vast knowledge of different languages and their ability to understand complex linguistic structures to provide more accurate and fluent translations. For instance, Large Language Models (LLMs) enable Google Translate to generate more accurate and natural-sounding translations across a wide range of languages. By training on massive amounts of multilingual data, LLMs improve the quality and fluency of translations, making the service more reliable and effective for users.
Microsoft Translator is another popular translation platform that harnesses the power of LLMs. Large Language Models (LLMs) enable Microsoft Translator to perform automatic translation of text, documents, and even real-time speech translation. By leveraging the contextual understanding and linguistic nuances captured by Large Language Models (LLMs), Microsoft Translator provides accurate translations in various languages, catering to the needs of businesses, travelers, and individuals worldwide.
John Snow Labs employs LLMs in NLP for language translation tasks. By leveraging the power of these models, they develop translation systems capable of accurately converting text from one language to another. This enables efficient communication and localization across different regions and cultures.
Named Entity Recognition (NER) with Large language models (LLMs)
LLMs play a crucial role in extracting and identifying named entities from text. They can accurately identify entities such as names of people, organizations, locations, and dates. For instance, Google Cloud Natural Language API leverages Large Language Models (LLMs) to provide powerful Named Entity Recognition capabilities. By utilizing their extensive training on diverse datasets, LLMs enable the API to accurately identify and classify named entities in various contexts. This allows businesses to extract valuable insights from unstructured text, automate data extraction processes, and enhance information retrieval systems.
SpaCy, a popular open-source library for NLP, utilizes Large Language Models (LLMs) for Named Entity Recognition tasks. With the help of LLMs, SpaCy is able to achieve state-of-the-art performance in identifying named entities in different languages. This enables developers and researchers to build NER systems that can accurately extract entities from texts in domains such as healthcare, finance, and legal documents.
John Snow Labs utilizes Large Language Models (LLMs) to enhance Named Entity Recognition capabilities. By fine-tuning these models on domain-specific data, they can accurately identify and classify named entities, such as people, organizations, and locations, within unstructured text. This facilitates information extraction and knowledge discovery in various industries.
Benefits of large language models for business
Large language models (LLMs) offer numerous benefits for businesses across various industries.
- Enhanced Customer Service: LLMs can power sophisticated chatbots and virtual assistants, providing quick, accurate, and contextually relevant responses to customer inquiries. This improves customer experience and can lead to higher satisfaction rates.
- Efficient Data Processing: Businesses often deal with vast amounts of unstructured data. LLMs can analyze and interpret this data, extracting valuable insights that can inform decision-making and strategy.
- Content Generation: LLMs can assist in generating high-quality written content, from marketing materials and reports to personalized emails and social media posts. This can save time and resources while maintaining a consistent brand voice.
- Personalization: By analyzing customer data, LLMs can help businesses personalize their offerings, recommendations, and communications, leading to more effective marketing and improved customer engagement.
- Language Translation and Localization: LLMs can quickly and accurately translate content into multiple languages, making it easier for businesses to operate and communicate in global markets.
- Market Analysis and Trend Prediction: By processing current news, market reports, and social media data, LLMs can help businesses stay ahead of market trends and make data-driven decisions.
- Automating Routine Tasks: Tasks like data entry, scheduling, and basic customer queries can be automated using LLMs, freeing up human employees to focus on more complex and creative tasks.
- Risk Management: In fields like finance and law, LLMs can analyze documents and data to identify potential risks and compliance issues, aiding in more effective risk management.
- Innovation in Product Development: By analyzing customer feedback and market trends, LLMs can provide insights that drive innovation in product development and business strategies.
- Cost Reduction: Automating routine tasks and improving efficiency with LLMs can lead to significant cost savings for businesses.
- Improved Decision Making: With their ability to process and analyze large datasets, LLMs can provide comprehensive insights that support better-informed business decisions.
- Employee Training and Support: LLMs can be used to create interactive training materials and provide real-time assistance to employees, enhancing learning and productivity.
In summary, large language models offer transformative potential for businesses, enabling them to enhance customer experiences, streamline operations, and leverage data for strategic advantage.
Large language models (LLMs): Conclusion
LLMs have revolutionized the field of Natural Language Processing (NLP). These powerful models, such as BERT, GPT, and others, have demonstrated their effectiveness in various NLP tasks, including text generation, question answering, sentiment analysis, language translation, and named entity recognition.
Throughout this article, we have explored the definition and importance of LLMs in NLP. We have discussed popular models like BERT and GPT, compared their training approaches and pre-training objectives. Additionally, we have examined the applications of LLMs in NLP, including text generation, question answering, sentiment analysis, language translation, and named entity recognition, with real-world examples showcasing their effectiveness.
To leverage the power of Large Language Models (LLMs) in your own projects, it is recommended to explore the offerings of John Snow Labs as it provides comprehensive solutions and frameworks for NLP tasks.
Take action now and explore John Snow Labs’ Large Language Models (LLMs) to discover the immense potential they hold for your specific use cases. Embrace the power of LLMs in your NLP endeavors and unlock new frontiers of language processing and understanding.
Remember, with large language models (LLMs), the possibilities are endless, and the future of NLP is brighter than ever before.
FAQs about Large Language Models (LLMs)
Below are the frequently asked questions about Large Language models.
1. What are Large Language models (LLMs)?
LLMs are advanced artificial intelligence models designed to understand and generate human-like language. They are trained on massive amounts of text data to learn patterns, context, and semantic relationships in language. LLMs have the capability to process and generate text in a way that closely resembles human language.
2. How do Large Language models (LLMs) work?
Large language models (LLMs) work by utilizing deep learning techniques, specifically LLM transformers, to process and understand natural language. These models consist of multiple layers of self-attention mechanisms that allow them to capture long-range dependencies and contextual information in text. By learning from vast amounts of data, LLMs can generate coherent and contextually relevant responses or predictions.
3. How are Large Language models (LLMs) trained?
The training process of Large Language Models (LLMs) involves two key stages: pre-training and fine-tuning. During pre-training, models learn language patterns and statistical properties from a vast corpus, including synthetic data, involving billions of parameters, which extends the training time. Fine-tuning then tailors these models to specific tasks using labeled data and reinforcement learning from human feedback, enhancing their application accuracy. This process, crucial in large language model development, is influenced by the LLM model size and is a step towards achieving milestones like artificial general intelligence.
4. What are the best types of LLMs?
Some of the best-known and widely used large language models (LLMs) include BERT, GPT, T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. These models have shown exceptional performance in various NLP tasks and have been widely adopted in both research and industry.
5. What are the differences between Large Language models (LLMs) and traditional NLP?
Traditional NLP approaches rely on rule-based systems and handcrafted features, whereas large language models (LLMs) leverage the power of deep learning and neural networks to learn language representations from data. LLMs are trained on massive amounts of text and have the ability to capture complex language patterns and contextual understanding, leading to more accurate and contextually relevant results compared to traditional methods.
NLP Summit 2023
Investigation of LLMs for Financial Use Cases






