
























































John Snow Labs is proud to continue contributing towards AI innovation in the Healthcare and Life Science industries by introducing remarkable improvements to state-of-the-art clinical & biomedical natural language processing, with the latest release of Spark NLP for Healthcare 3.0.
Back in 2019, The Spark NLP 2.0 library obtained the best performing academic peer-reviewed results. Today, Spark NLP is one of the most widely used NLP libraries in the Healthcare industry and Enterprise. But as the saying goes “With Great Power, Comes Great Responsibility” and John Snow Labs has lived up to expectations by delivering another breakthrough with the latest major release of Spark NLP for Healthcare. Here are the major upgrades in this release.
New Implementation of Medical Named Entity Recognition
This release introduces the new MedicalNerModel annotator – improving on the implementation that delivers the state-of-the-art accuracy for which John Snow Labs’ named entity recognition is academically validated and peer-reviewed.
All the licensed clinical and biomedical pre-trained NER models will now run with MedicalNerModel instead of its parent NerDLModel from Spark NLP. To make this happen, the JSL retrained all the clinical NER models (more than 80) and uploaded them to the Models Hub.
Richer Pre-Trained Clinical Named Entity Recognition
The new jsl_ner_wip pre-trained model for clinical named entity recognition can identity over 80 types of entities out of the box:

This is the richest clinical NER model we have ever trained, consolidating feedback and annotation guidelines from several real-world projects. It has been under development for over six months and required manual annotation of more than 4,000 clinical notes to cover such a high number of entities in a single model.
This new model has 4 variants at the moment:

Richer Clinical Assertion Status Detection Model
A brand-new clinical assertion status model jsl_assertion_wip now supports 8 assertion statuses:

This model has also been trained with a combination of external and in-house manually annotated data by our team of clinicians. As such, the annotation guidelines have been refined and some discrepancies and mistakes in academic datasets have been resolved. While no model is perfect, this should result in higher accuracy results for real-world use cases.
Speed!
This release includes major speed and performance enhancements. Compared to the previous 2.7 release, Spark NLP for Healthcare 3.0 does Named Entity Recognition and Entity Resolution 2 times faster on CPU and 3 times faster on GPU.
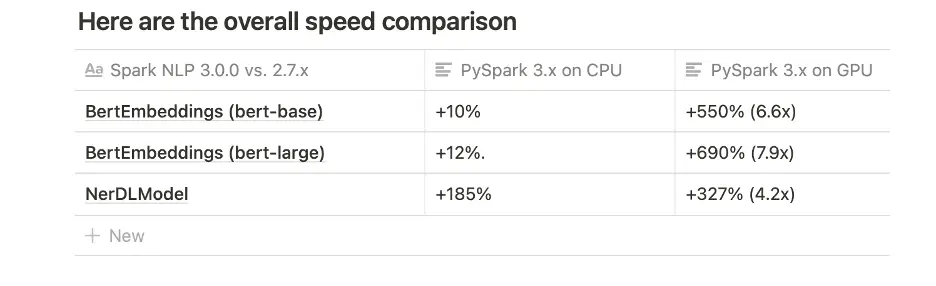
Thanks to a new batch annotation technique implemented in Spark NLP 3.0 for NerDLModel, BertEmbeddings, and BertSentenceEmbeddings annotators, which are reflected in MedicalNerModel, which also improves prediction/inferencing performance radically.
From now on, the batchSize for these annotators means the number of rows that can be fed into the models for prediction instead of sentences per row. You can control the throughput when we are on accelerated hardware such as GPU – to make sure the hardware is fully utilized.
Scalability & Platform Integrations
Spark NLP for Healthcare welcomes 9 new Databricks runtimes that are now fully tested & supported:
- Databricks 7.3
- Databricks 7.3 ML GPU
- Databricks 7.4
- Databricks 7.4 ML GPU
- Databricks 7.5
- Databricks 7.5 ML GPU
- Databricks 7.6
- Databricks 7.6 ML GPU
- Databricks 8.0
- Databricks 8.0 ML (there is no GPU in 8.0)
- Databricks 8.1 Beta
In addition, this latest release welcomes 2 new EMR 6.x series to the Spark NLP family:
- EMR 6.1.0 (Apache Spark 3.0.0 / Hadoop 3.2.1)
- EMR 6.2.0 (Apache Spark 3.0.1 / Hadoop 3.2.1)
This release provides a hassle-free experience for migrating from earlier Apache Spark versions since you do not have to upgrade and can choose when to do it: All the last 4 major Apache Spark versions are fully supported (2.3.x, 2.4.x, 3.0.x, and 3.1.x).
Support for Apache Spark 3.0.x and 3.1.x is new in this release, along with support for Scala 2.12 with both Hadoop 2.7. and 3.2. Both CPU and GPU optimized builds are available.
To learn more and get started with the software:
- Get started here
- Live demos here
- Find more information on the page Medical NLP
- Read information about more specific Clinical NLP




