
























































In today’s hyper-connected world, every organization is a data company, whether they realize it or not. From hospitals and banks to startups and SaaS platforms, sensitive data flows through every layer of business operations. But with that data comes a growing responsibility: to protect individual privacy and prevent misuse.
The risks of mishandling sensitive information are no longer theoretical; they are a reality. High-profile data breaches and privacy violations are making headlines regularly, costing companies millions in fines, legal actions, and customer trust. Regulations like HIPAA, GDPR, and India’s DPDP Act now enforce strict controls on how personally identifiable information (PII) and protected health information (PHI) are stored, processed, and shared.
And the stakes are high; GDPR fines can reach up to €20 million, or 4% of a company’s global annual revenue. HIPAA violations may cost $50,000 per incident, even for unintentional leaks. Reputational damage is hard to quantify and even harder to repair.
Yet, data is also an asset, crucial for research, innovation, and AI development. That’s where smart de-identification and obfuscation come in. Our solutions enable organizations to safely unlock the value of their data without compromising privacy, compliance, or security.
Introduction to John Snow Labs
John Snow Labs is an award-winning Healthcare AI company specializing in privacy-preserving and compliant AI solutions. One of our core offerings is PHI de-identification, which leverages a powerful combination of our Visual NLP and Healthcare NLP products, both available under a commercial license alongside the open-source Spark NLP library. These components work seamlessly together to deliver accurate, scalable, and production-ready de-identification workflows for a wide range of healthcare documents and formats.
Our solutions are designed for flexibility and scalability. We offer ready-to-deploy AWS SageMaker endpoints for seamless integration into cloud workflows, and our tools run across various environments, including Databricks, Google Colab, on-premise servers, or any Spark-compatible infrastructure.
What is De-Identification/Obfuscation?
At John Snow Labs, we provide two key methods for safeguarding sensitive personal information in documents: de-identification and obfuscation. De-identification involves using box redaction to remove and visually mask personal information entirely, ensuring that any identifiers are completely hidden. Obfuscation, on the other hand, takes it a step further by generating realistic but fake text of similar length to replace the original content, ensuring that the document remains contextually intact while concealing sensitive details.
Note: In the case of obfuscation, memory is maintained at the file level. For example, if the name “John Snow” is obfuscated as “Jerr Bolt” on the first page of a PDF, the same replacement will be consistently applied throughout the entire document.
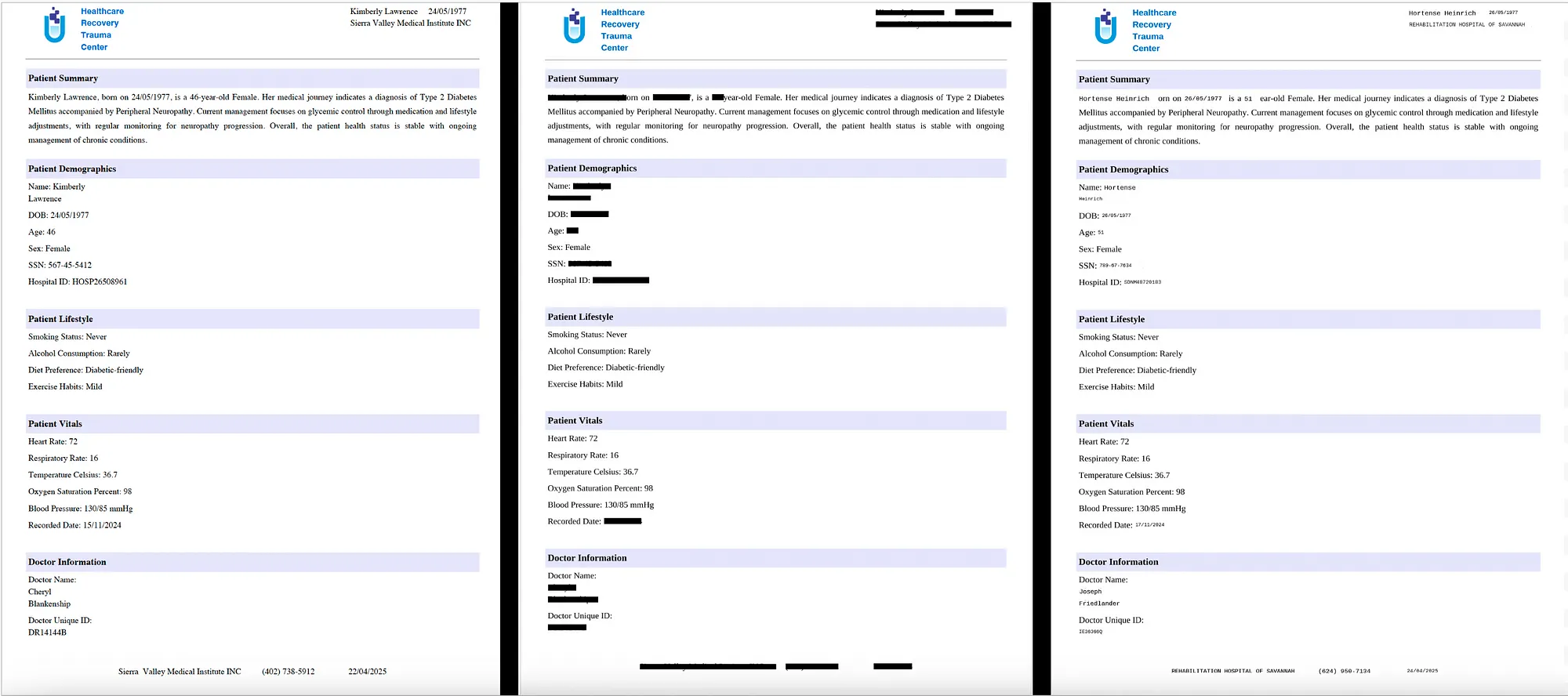
Original, De-Identified, Obfuscated (Left to Right)
Our solution leverages both Healthcare and Visual products to deliver comprehensive data protection. The Visual tools handle the processing of various document types — including PDFs, Images, DICOM, and SVS files by extracting text and region-level information.
Once the text is extracted, the Healthcare tools take over to perform NLP operations, such as document assembly, sentence detection, tokenization, NER entity detection, using a combination of zero-shot models, pre-trained models, and regex-rule-based approaches to generate Annotations.
At this stage, we go back to the Visual NLP tools to generate precise coordinates for the PHIs within the document. These coordinates enable us to accurately apply de-identification or obfuscation techniques directly to the original document, rendering a new PDF as the final output.
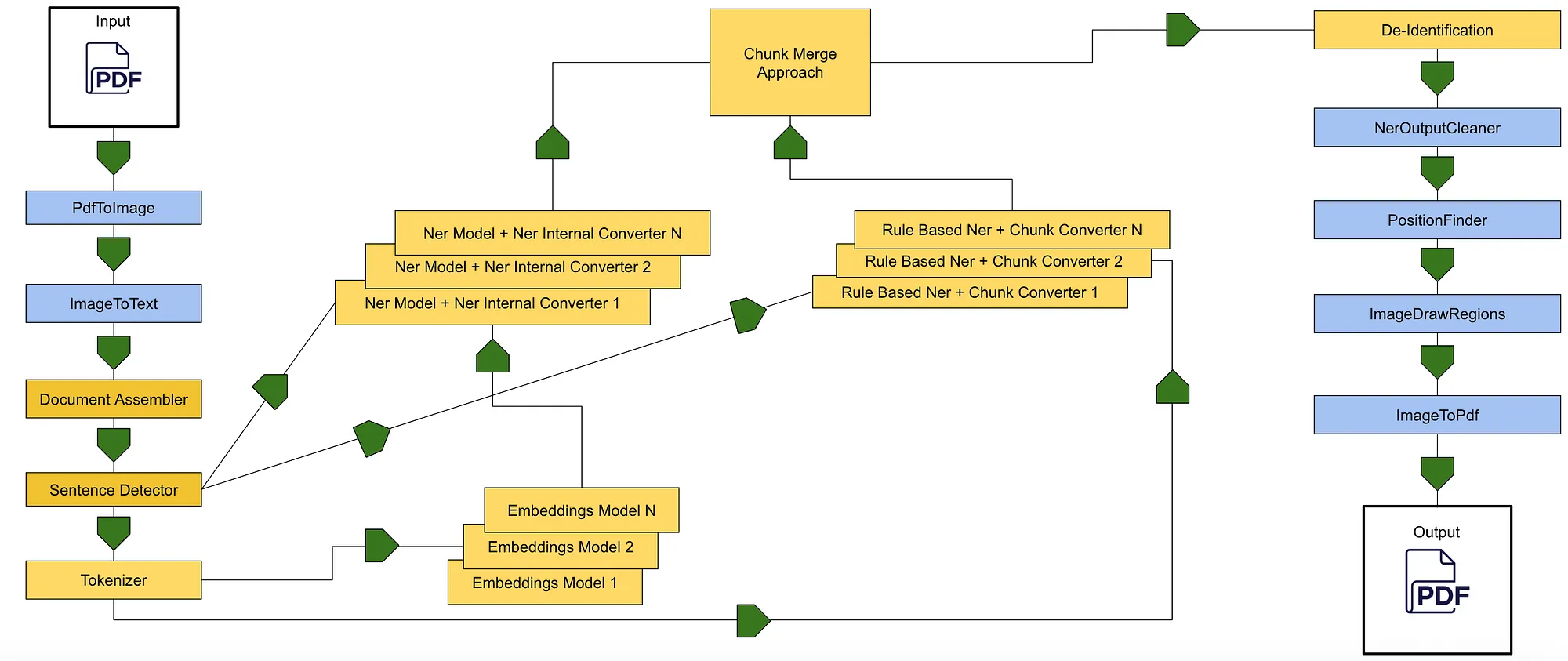
Visual NLP (Blue Stages), Healthcare NLP (Yellow Stages)
Implementing such solutions involves multiple intricate steps, and managing each component individually can be overwhelming, especially for beginners. To simplify this complexity, we offer PretrainedPipelines.
Pretrained Pipelines:
PretrainedPipelines abstract away all the underlying stages, allowing you to execute the entire workflow with a single transform() call to generate results.
from sparknlp.pretrained import PretrainedPipeline
from sparknlp.pretrained import PretrainedPipeline
# Download Pretrained Pipeline
pipeline_name = "pdf_deid_multi_model_context_signature_aware_pipeline"
deid_pipeline = PretrainedPipeline(pipeline_name, "en", "clinical/ocr")
# Read Input PDF
input_pdf_path = "/content/sample.pdf"
df = spark.read.format("binaryFile").load(input_pdf_path)
# Transform Call
result = deid_pipeline.transform(df)
# Extract Final PDF from dataframe
for row in result.select("path", "pdf").toLocalIterator():
saveLocalDir = "/content/sample_cleaned.pdf"
pdfFile = open(savename, "wb")
pdfFile.write(row.asDict()["pdf"])
pdfFile.close()
Pretrained pipelines for de-identification/obfuscation, which are available on ModelsHub
- pdf_deid_multi_model_context_pipeline
– Task: Deidentification
– Removes the following entity classesAGE,CITY,COUNTRY,DATE,DOCTOR,EMAIL,HOSPITAL,IDNUM,ORGANIZATION,PATIENT,PHONE,PROFESSION,STATE,STREET,USERNAME,ZIP - pdf_deid_multi_model_context_signature_aware_pipeline
– Task: Deidentification & Signature Removal
– Removes the same entity class as above. - pdf_obfuscation_multi_model_context_pipeline
– Task: Obfuscation
– Removes the same entity class as above. - pdf_deid_multilingual_name_plus
– Tasks: Deidentification
– Removes the following entity classesHOSPITAL,NAME,PATIENT,ID,MEDICALRECORD,IDNUM,COUNTRY,LOCATION,STREET,STATE,ZIP,CONTACT,PHONE,DATE - pdf_deid_multilingual_name_plus_signature_aware
– Task: Deidentification & Signature Removal
– Removes the same entity class as above. - pdf_obfuscate_multilingual_name_plus
– Task: Obfuscation
– Removes the same entity class as above. - pdf_deid_subentity_context_augmented_pipeline
– Tasks: Deidentification
– Removes the following entity classesAGE,BIOID,CITY,COUNTRY,DATE,DEVICE,DOCTOR,EMAIL,FAX,HEALTHPLAN,HOSPITAL,IDNUM,LOCATION,MEDICALRECORD,ORGANIZATION,PATIENT,PHONE,PROFESSION,STATE,STREET,URL,USERNAME,ZIP,ACCOUNT,LICENSE,VIN,SSN,DLN,PLATE,IPADDR
Note: Refer to this notebook for a demonstration of how to run all the PretrainedPipelines mentioned above on both single and multiple PDF input files.

Sample PDF Files Easy, Medium, Hard (Left to Right)
Sample PDF Files Easy, Medium, Hard (Left to Right)
- The Easy set contains 30 PDF files. The Medium set builds on this by including all Easy files plus 10 additional, moderately noisy documents. The Hard set extends the Medium set further with 10 additional challenging files, introducing advanced visual noise and layout complexities.
- Despite the increasing difficulty across datasets, performance remained strong. Naturally, as more noise was introduced in the Medium and Hard sets for demonstration purposes, a slight degradation in performance was observed.
- For the Zero-Shot, we used 10 Medium files, focusing on de-identifying only three PHI entity types: Patient Name, SSN and Date of birth.
- If you’re interested in exploring the workflow or regenerating these results, please refer to this notebook. Pretrained Pipelines are designed to deliver end-to-end solutions. The result will contain the final output only; all intermediate stages are lost due to the final stage, as it performs aggregations.
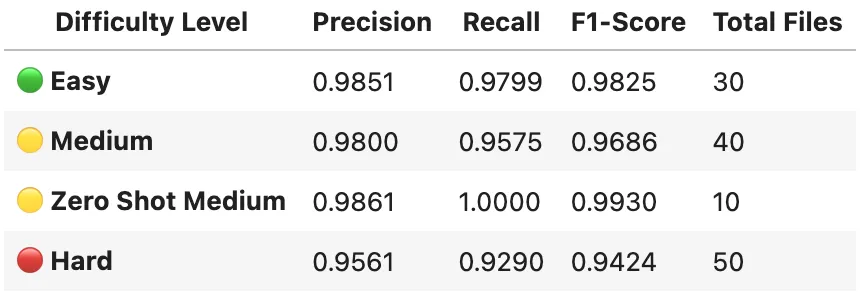
NER Detection Metrics
Ready to try John Snow Labs document de-identification/Obfuscation solutions on your data securely, within your environment, where nothing ever leaves your network? We invite you to explore our capabilities using either your in-house datasets or our synthetic dataset. See for yourself the powerful impact our solutions can have on your data privacy and compliance workflows.
Have questions? Want a personalised demo or features? Get in touch with us, we’d love to help you get started.
De-identifying a handful of images is one thing—but healthcare institutions process thousands. That’s why John Snow Labs’ Visual NLP, built on Apache Spark, is designed for scale. Learn how this scalable architecture helps institutions de-identify SVS and DICOM files efficiently and reliably in this article.





