Medicare Advantage Program and Risk Adjustment
The Medicare Advantage (MA) program allows Medicare beneficiaries to benefits from private insurers, otherwise known as Medicare Advantage Organizations (MAOs) that contract with the Centers for Medicare and Medicaid Services (CMS). Anyone who is eligible for Medicare may elect to enroll in a Medicare Advantage plan offered in the service area in which he or she resides.

CMS pays each MAO a monthly per-person amount for each beneficiary enrolled in its plan. The plan payment rates are determined by the plan’s bid, which is submitted to CMS on an annual basis and represents the dollar amount that the plan estimates will cover the benefit package for a beneficiary of average health status in the area where service is offered. The per-person amount paid to each plan for enrolled beneficiaries is adjusted to account for differences in health status between enrolled beneficiaries. This is referred to as “risk adjustment”.
CMS began implementing health-based risk adjustment using the Principal Inpatient Diagnostic Cost Group (PIP-DCG) model in 2000. Some changes were made to this model in years. As a result, CMS started to implement a new risk adjustment model to begin using for payment in 2004: the Centers for Medicare & Medicaid Services (CMS) Hierarchical Condition Categories (CMS-HCC) model, which included diagnoses recorded on professional, inpatient, and outpatient claims.
The risk adjustment models used in the Medicare Advantage program function as a more comprehensive method of underwriting in which diagnoses and demographic information are used to adjust each enrollee’s monthly capitation rate to account for the expected cost associated with their age, sex, and the conditions they have.
CMS-HCC Model
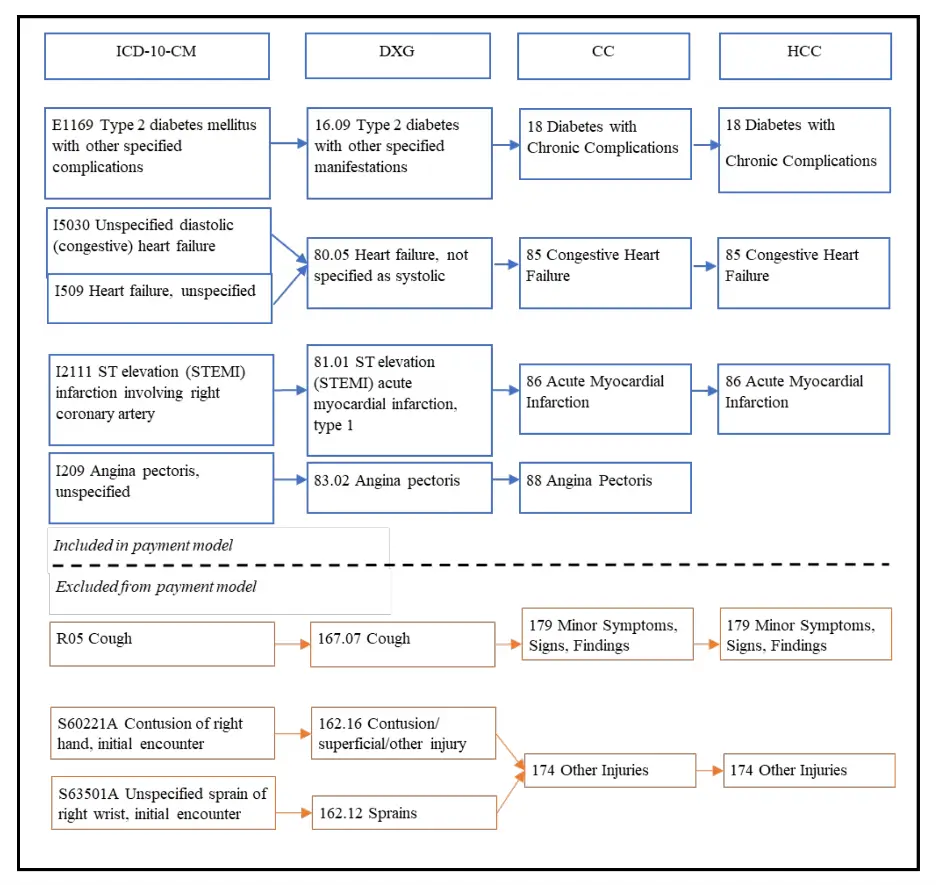
The HCC diagnostic classification system begins by classifying over 71,000 ICD-10-CM diagnosis codes into diagnostic groups (DXG). Hierarchies are imposed among related condition categories (CC) so that a person is coded for only the most severe manifestation among related diseases. And finally, a hierarchy is implemented between those CCs. In the following figure, we can see a patient’s diseases and how they are converted to HCC. The patient’s disease list contains 8 different ICD-10 codes. Those ICD codes are converted to 7 diagnostic groups and then to 6 condition groups. And finally, HCC comes. The patient has several diseases, and we fill focus on “86 Acute Myocardial” and “88 Angina Pectoris”. After the CC code converts to HCC, we only see “86 Acute Myocardial” in the HCC column. This is because HCC 86 is riskier, and it occupies a higher level hierarchically than HCC 88. Besides this, some diseases are excluded from the payment model.
How Spark NLP handles Medicare Adjustment Score?
The most challenging part of calculating risk scores is having the right ICD Codes. Spark NLP has an ICD-10 resolver which is very useful for extracting ICD-Codes from unstructured texts.
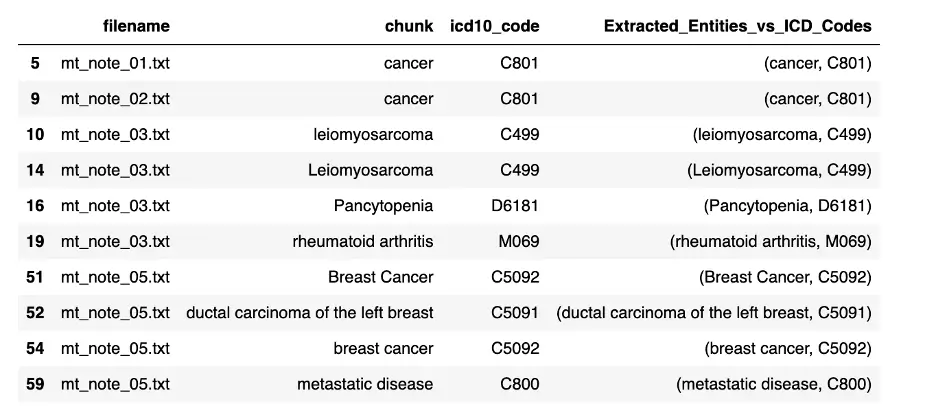
After getting ICD codes of diseases by Spark NLP Healthcare ICD resolvers, a risk score can be calculated by Spark NLP Healthcare CMS-HCC risk-adjustment score calculation module. Currently, the supported version for the model is CMS-HCC V24.
The model needs the following parameters in order to calculate the risk score:
- ICD Codes
- Age
- Gender
- The eligibility segment of the patient
- The original reason for entitlement
- If the patient is in Medicaid or not
- If the patient is disabled or not
Like ICD Codes, age and gender can also be extracted from the unstructured text by using Spark NLP libraries. The other four parameters should be verified by other authorities. So those parameters need to be imported into the model separately.
We have that information extracted from text patients’ clinical notes.

We can use those values and calculate risk scores by profile function in the sparknlp_jsl.functions module.
from sparknlp_jsl.functions import profile
df = df.withColumn("hcc_profile", profile(df.ICD_codes, df.Age, df.Gender))
df = df.withColumn("hcc_profile", F.from_json(F.col("hcc_profile"), schema))
df= df.withColumn("risk_score", df.hcc_profile.getItem("risk_score"))\
.withColumn("hcc_lst", df.hcc_profile.getItem("hcc_map"))\
.withColumn("parameters", df.hcc_profile.getItem("parameters"))\
.withColumn("details", df.hcc_profile.getItem("details"))\
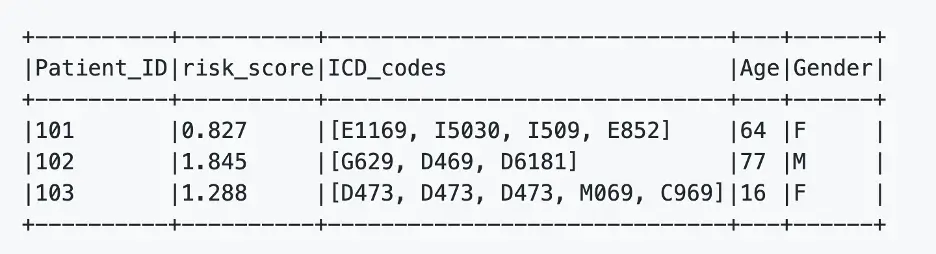
df.select('Patient_ID', 'risk_score','ICD_codes', 'Age', 'Gender').show(truncate=False )
df.show(truncate=100, vertical=True)