






















































Spark NLP for Healthcare
There is a growing need for automated text mining of Electronic health records (EHRs) in order to find clinical indications that new research points to. EHRs are the primary source of information for clinicians tracking the care of their patients. Information fed into these systems may be found in structured fields for which values are inputted electronically (e.g. laboratory test orders or results)but most of the time information in these records is unstructured making it largely inaccessible for statistical analysis. These records include information such as the reason for administering drugs, previous disorders of the patient or the outcome of past treatments, and they are the largest source of empirical data in biomedical research, allowing for major scientific findings in highly relevant disorders such as cancer and Alzheimer’s disease. Despite the growing interest and groundbreaking advances in NLP research and NER systems, easy to use production-ready models and tools are scarce in the biomedical and clinical domains and it is one of the major obstacles for clinical NLP researchers to implement the latest algorithms into their workflow and start using immediately. On the other hand, NLP tool kits specialised for processing biomedical and clinical text, such as MetaMap and cTAKES typically do not make use of new research innovations such as word representations or neural networks discussed above, hence producing less accurate results.
We introduce Spark NLP for Healthcare as the one-stop solution to address all these issues [2].
Commercial Clinical NLP Solutions (APIs)
There are already several commercial healthcare NLP solutions in the market but most of them are built and maintained by a small team of in-house developers to serve the daily needs of the company it is built for. In this study, we’ll explore publicly available, pay-as-you-go solutions developed and maintained by major cloud providers that use natural language processing to meet the challenge — Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health.
 Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
 Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Since the data used by these services to train & fine-tune their own models is confidential, and given the fact that it is highly expensive and time-consuming to develop in-house datasets, we can strongly assume that apart from the proprietary in-house datasets, they must have included publicly available datasets as well for training purposes.
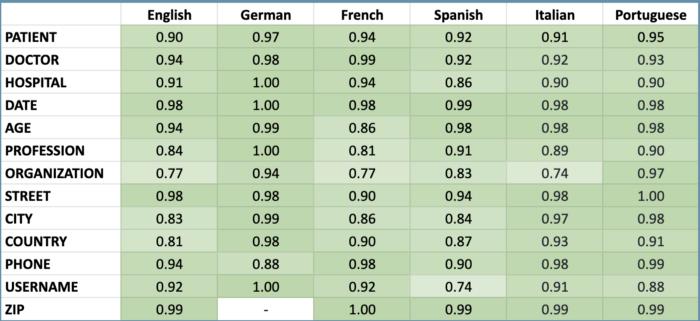
Spark NLP for Healthcare can de-identify clinical notes in 6 spoken languages. Here are the supported languages and the accuracy metrics for each one of them. This is the only library that can support that many languages out of the box with zero code change (switching from one language to another is as easy as using two-letter language symbols while downloading the models).
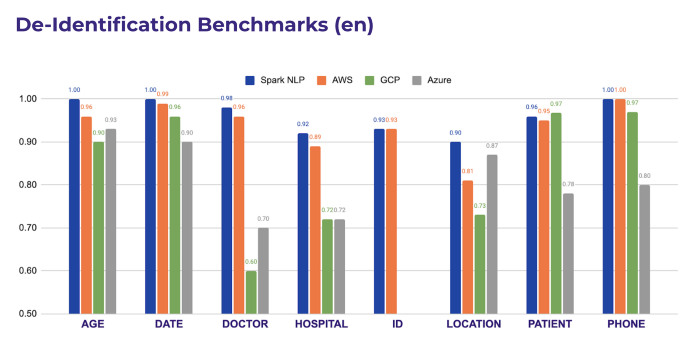
As the other cloud solutions support De-Identification only in the English language, we can compare the performance as shown below.
Comparison Setup and Methodology
Now we can compare the deidentification capabilities of different libraries on 100 random clinical notes taken from n2C2 Deidentification dataset. We are just taking into account all the capabilities the libraries offer without needing to do any further training, finetuning or defining in-house rules.
Important notes to consider before moving forward
-
All libraries tested here have different tags. A map of entities is provided.
-
All libraries have different annotations guidelines, so we have considered as value fuzzy matches, with similarity bigger than the 60% of the annotated by JSL chunk (For some APIs, the chunk “Children Care Clinic” is detected including the word “Clinic”, for others only proper names (“Children Care”). Both may be valid, they just depend on the annotation guidelines).
-
All libraries have customization capabilities, that mean you can get much better results if you use some in-house knowledge, rule-based approach or finetunning. However, the aim of this benchmark is to check OUT OF THE BOX capabilities without any customization.
-
All libraries have more labels that the ones we included here, we just got a sample of 8 representative labels (ID, DATE, HOSPITAL, LOCATION, AGE, PATIENT, DOCTOR, PHONE)
-
Only SparkNLP and AWS had a good coverage of all the tags. Azure and GCP needed a combination of the PHI endpoint + a commong NER for detecting other entities (as Locations, Names, etc)
Not all the API have the same specificity using labels. Some of them use more high-level tags (for example, NAME for both Doctor and Patient names, or LOCATION City, ZIP, even Hospital) but some others go low-level, so you can be able to differentiate between Doctors and Patients, what we should appreaciate.
The more specificity – the better, because as a rule of thumb, the more specific the less accurate you usually are: detecting NAME is evidently easier than detecting and asserting if that name is a Doctor’s name or a Patient’s name.
Same happens with LOCATIONS and subentities (Street, City, etc) and many other tasks.
Comparison Results
The most specific library is Spark NLP for Healthcare, since it’s the only one able to distinguish between a Patient and a Doctor Name, a Hospital and other Organizations or Addresses, etc.
This does not say anything about the accuracy of those tags. At the end of the day, you can have just one tag NAME or LOCATION and be able to detect all patients vs doctors, or organizations vs hospitals.
However, just imagine you want to mas or obfuscate the Hospital name. If you detect it as ORGANIZATION* you may mask it as ORG and obfuscate it as “McDonalds”. It is much better to be aware it’s a Hospital and obfuscate is as Mt. Sinai instead.
As you can see, Spark NLP performs better than all the other cloud services in every entity type evaluated. These results can be reproduced by using the Colab notebook we shared in our repo.
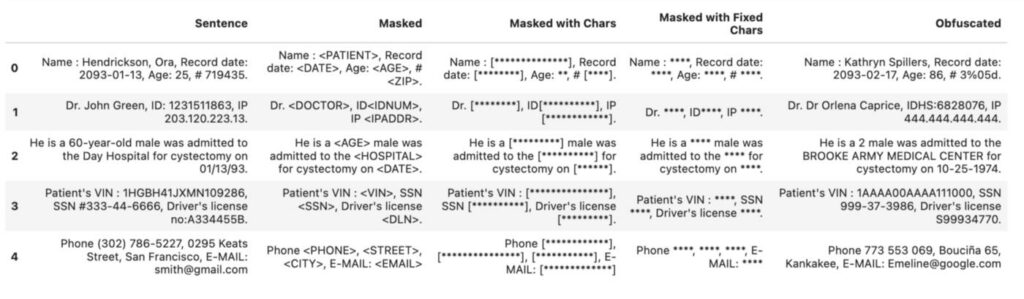
Given the simplicity of employing a De-Identification service with a one-liner in Spark NLP and all can work in air-gapped environments with no internet connection, it is clear that Spark NLP is a leading solution in this domain. Here is what you can achieve in Spark NLP while running a De-Identification pipeline in only one line of code with no fine-tuning.
Conclusion
Spark NLP for Healthcare comes with 600+ pretrained clinical pipelines & models out of the box and is performing way better than AWS, Azure and Google Cloud healthcare APIs by 18%, 12% and 15% (making 4–6x less error) respectively on extracting medical named entities from clinical notes. It’s also doing better consistently on entity resolution to map clinical entities to medical terminologies. Here are the other advantages of using Spark NLP for Healthcare against cloud APIs:
- Spark NLP for Healthcare offers highly customisable models and pipelines that can be shipped within the existing codebase while cloud APIs are basically black-box services that you should be OK with whatever you get in.
- The DL models shipped within Spark NLP for Healthcare can be fine-tuned and extended using the custom terminologies and new datasets annotated in-house.
- Spark NLP is the only NLP library out there that can scale over Apache Spark clusters to process large volumes of data.
- Spark NLP for Healthcare can work in air-gapped environments with no internet connection and requires no other dependency other than Spark itself. Given that Healthcare APIs offered by major cloud providers require an internet connection, this is a highly important aspect when it comes to preserving the privacy of sensitive information (PHI data) while running some analytics.
- Healthcare APIs offered by major cloud providers are pay-as-you-go solutions and can cost too much when it comes to processing a large volume of clinical texts. On the other hand, Spark NLP for Healthcare is licensed once and has no limitation in that regard. So, you can process TBs of clinical notes with the state of the art accuracy without paying anything other than the one-time annual license.
Do you want to know more?
- Check the example notebooks in the Spark NLP Workshop repository, available here
- Visit John Snow Labs and Spark NLP Technical Documentation websites
- Write to support@johnsnowlabs.com for any additional request you may have




