























































Spark NLP for Healthcare comes with 600+ pretrained clinical pipelines & models out of the box and is consistently making 4–6x less error than Azure, AWS, and Google Cloud on extracting medical named entities from clinical notes. It comes with clinical and biomedical named entity recognition (NER), assertion status, relation extraction, entity resolution, and de identification NLP modules that are all trainable. Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomies.
Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment. Spark NLP comes with 5000+ pretrained pipelines and models in more than 200+ languages. It supports nearly all the NLP tasks and modules that can be used seamlessly in a cluster. Downloaded more than 25 million times and experiencing 10x growth over the last year, Spark NLP is used by 41% of healthcare organizations as the world’s most widely used NLP library in the enterprise [1]. In order to learn more about the components of the Spark NLP ecosystem, please watch this recording, visit https://nlp.johnsnowlabs.com/ and also check out a quick deep dive session for free.

https://pepy.tech/project/spark-nlp (last visit May 1st, 2022)
Spark NLP for Healthcare
There is a growing need for automated text mining of Electronic health records (EHRs) in order to find clinical indications that new research points to. EHRs are the primary source of information for clinicians tracking the care of their patients. Information fed into these systems may be found in structured fields for which values are inputted electronically (e.g. laboratory test orders or results)but most of the time information in these records is unstructured making it largely inaccessible for statistical analysis. These records include information such as the reason for administering drugs, previous disorders of the patient, or the outcome of past treatments, and they are the largest source of empirical data in biomedical research, allowing for major scientific findings in highly relevant disorders such as cancer and Alzheimer’s disease.
Despite the growing interest and groundbreaking advances in NLP research and NER systems, easy-to-use production-ready models and tools are scarce in the biomedical and clinical domains and it is one of the major obstacles for clinical NLP researchers to implement the latest algorithms into their workflow and start using immediately. On the other hand, NLP tool kits specialized for processing biomedical and clinical text, such as MetaMap and cTAKES typically do not make use of new research innovations such as word representations or neural networks discussed above, hence producing less accurate results.

Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomies
Recent developments highlight that multimodal NLP systems are becoming essential in healthcare. In 2025, several large studies confirmed that combining text with medical images, genomics, and real-time patient data significantly improves diagnostic accuracy. These systems not only analyze notes and reports but also integrate imaging findings and lab results, offering clinicians holistic insights that were previously difficult to obtain.
Another important trend is the shift toward federated and privacy-preserving NLP. Hospitals and research networks increasingly adopt approaches that allow training and fine-tuning models on distributed datasets without moving sensitive health information. This addresses regulatory requirements while still enabling institutions to collaborate on building more robust models. Initial results from pilot programs show strong improvements in both compliance and model generalization across diverse patient populations.
Finally, generative AI capabilities are reshaping healthcare NLP workflows. Beyond extracting and structuring information, advanced models are now used to generate patient summaries, draft clinical trial reports, and even provide decision support for treatment planning. Recent benchmarks indicate that generative scribing tools can reduce clinician documentation time by approximately 20%, demonstrating a tangible impact on workflow efficiency (JAMA Network Open).
We introduce Spark NLP for Healthcare as the one-stop solution to address all these issues [2]. Spark NLP already powers leading healthcare and pharmaceutical companies including Kaiser Permanente, McKesson, Merck, Mt Sinai, and Roche. Since Spark NLP can also be used offline and deployed in air-gapped networks, with no internet connection, the companies and healthcare facilities do not need to worry about exposing the protected health information (PHI). You can check NLP case studies regarding each of these companies that are utilizing Spark NLP for Healthcare for their workflows.
Spark NLP for Healthcare is built on a pipeline concept in which all the individual components can be stacked together to accomplish what you need to solve a certain problem in healthcare analytics. Since every component, parameter, and model in the library are precisely distilled and fine-tuned through the years of experience while working on large-scale Healthcare Data Science projects run by the magnificent team behind this library, it just works!

Modular Approach to Solve Problems at Scale in Healthcare NLP (learn more at https://youtu.be/4KDEafHifL8)
The journey of any NLP task in healthcare analytics usually goes as follows:
- extracting the useful information from unstructured EHR (electronic health records)
- mapping the clinical facts into a common format (e.g. FHIR, HL7, OMOP),
- building a temporal sequencing (putting clinical facts on a timeline)
- Using all the bits and bolts for the later downstream tasks.
At the end of a Spark NLP for Healthcare, here is what we want to see ideally at the end of the day:

an output from Spark NLP for the Healthcare pipeline
You can build such a pipeline from scratch and integrate it into your codebase (supports Java, Scala, Python, and R) as well as just use the prebuilt pipelines and models within an NLP Server, just another product within a Spark NLP ecosystem. NLP Server is ready to use the server for analyzing text documents using Spark NLP & NLU library via a simple and intuitive UI, without writing a line of code. For more expert users and more complex tasks, NLP Server also provides a REST API that can be used to process high amounts of data.
How to work with pretrained models and tune the parameters to achieve what you need is a topic for another day. Now, let’s dive into our main topic for this blog post: Comparison of Key Medical NLP Benchmarks — Spark NLP, AWS, GCP, Azure
Commercial Clinical NLP Solutions (APIs)
 Commercial & in-house healthcare NLP services
Commercial & in-house healthcare NLP services
There are already several commercial NLP solutions for healthcare in the market but most of them are built and maintained by a small team of in-house developers to serve the daily needs of the company it is built for. In this study, we’ll explore publicly available, pay-as-you-go solutions developed and maintained by major cloud providers that use natural language processing to meet the challenge — Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health. For the sake of brevity, I’ll mention these services as GCP, AMC and Azure respectively.

Google Cloud Healthcare API, Amazon Comprehend Medical, and Microsoft Azure Text Analytics for Health
Since the data used by these services to train & fine-tune their own models are confidential, and given the fact that it is highly expensive and time-consuming to develop in-house datasets, we can strongly assume that apart from the proprietary in-house datasets, they must have included publicly available datasets as well for training purposes.
There is a similar study already done by Gigaom to compare these 3 services and I suggest readers check that out for further details but Spark NLP for Healthcare was out of the scope in that study. Since the recent Gigaom’s report nicely summarizes the features of these services, I’ll just pick some wordings from that study to introduce these cloud services. For the details, please refer to that study.
Amazon Comprehend Medical
https://docs.aws.amazon.com/comprehend-medical/index.html
Part of the AWS cloud computing platform, Amazon Comprehend Medical is an API that extracts information such as medical conditions, medications, dosages, tests, treatments, procedures, and protected health information while retaining the context of the information. It can identify the relationships among the extracted information to help build applications for use cases like population health analytics, clinical trial management, pharmacovigilance, and summarisation.
Amazon Comprehend Medical is also linked to medical ontologies, such as ICD10-CM or RxNorm, to help build applications for use cases like revenue cycle management (medical coding), claim validation and processing, and electronic health records creation. The version being used in this study is v2.
Azure Cognitive Services for Language — Text Analytics for Health
https://docs.microsoft.com/en-us/azure/cognitive-services/language-service/text-analytics-for-health/quickstart
Azure Cognitive Services for Language, under the Cognitive Services umbrella, is a set of machine learning and AI algorithms for developing intelligent applications that involve natural language processing. Text Analytics for Health extracts and labels relevant medical information from unstructured texts such as physician notes, discharge recommendations, clinical documents, and electronic health records.
The Text Analytics for Health API performs the following functions for English-language medical text documents: NER, Relation Extraction, Entity Linking, and Negation (the meaning of a text can be greatly affected by modifiers such as negation, which can have critical implications if misinterpretation leads to a misdiagnosis.). The version being used in this study is v3.1.
Google Cloud Healthcare API
https://cloud.google.com/healthcare-api
Launched in 2018, the Google Cloud Healthcare API is a fully managed solution for storing, accessing, and analyzing healthcare data within the Google Cloud Platform (GCP) umbrella. The API comprises three modality-specific interfaces that implement key industry-wide standards for healthcare data: HL7 FHIR, HL7 v2, and DICOM. Each of these interfaces is backed by a standards-compliant data store that provides read, write, search, and other operations on the data.
The Healthcare Natural Language API extracts healthcare information from medical textual data. This healthcare information can include medical concepts (medications, procedures, and medical conditions), functional features (temporal relationships, subjects, and certainty assessments), and relationships (side effects and medication dosages). The Healthcare Natural Language API supports a wide range of medical vocabularies and taxonomies, including but not limited to ICD-10, SNOMED-CT, gene nomenclatures, MedlinePlus, and RxNorm. The version being used in this study is v1.
Comparison Setup and Methodology
As stated above, Spark NLP for Healthcare can extract and analyse 400+ different clinical & biomedical entities via 100+ NER models, 60+ Entity Resolution models from 10+ medical terminologies (ICD10, CPT-4, UMLS etc.), 50+ Relation Extraction models, 10+ Assertion Status Detection models and 40+ De-Identification models and pipelines. On the contrary, the number of entities and features of the major cloud providers are quite limited. Here is the list of entities that can be extracted from these services vs what Spark NLP can do:
That is, Spark NLP can extract entities at a more granular level and it is tricky to make a 1:1 mapping to evaluate these services fairly. The cloud services also do not support all the taxonomies when it comes to entity resolution (only 3–4 different terminologies are supported at most) and details are not clear from their documentation. That is why we decided to create a set of entities and medical terminologies to run this comparison.
- Named Entity Recognition -> Test, Treatment, Medication, Anatomy, Condition, Procedure
- Entity Resolution -> ICD10CM, SNOMED CT, RxNorm
- De-Identification and obfuscation (handling sensitive — PHI data)
For this study, we had to find an open-source dataset for the reproducibility concerns and mtsamples.com looked like a perfect venue. MTSamples.com is designed to give you access to a big collection of transcribed medical reports and contains sample transcription reports for many specialties and different work types. At the time of writing this article, mtsamples.com hosts 5,003 Samples in 40 types. For this study, we randomly picked 8,000 clinical notes from various types and have human annotators (physicians having substantial experience in each domain) annotate all for NER and entity resolution tasks.
Named Entity Recognition
First of all, we annotated this test dataset within the annotation guideline that we used our most popular clinical NER model named ner_jsl. Then we applied the following mapping to indicate which entity from the new annotation corresponds to an entity from Spark NLP vs other cloud services.
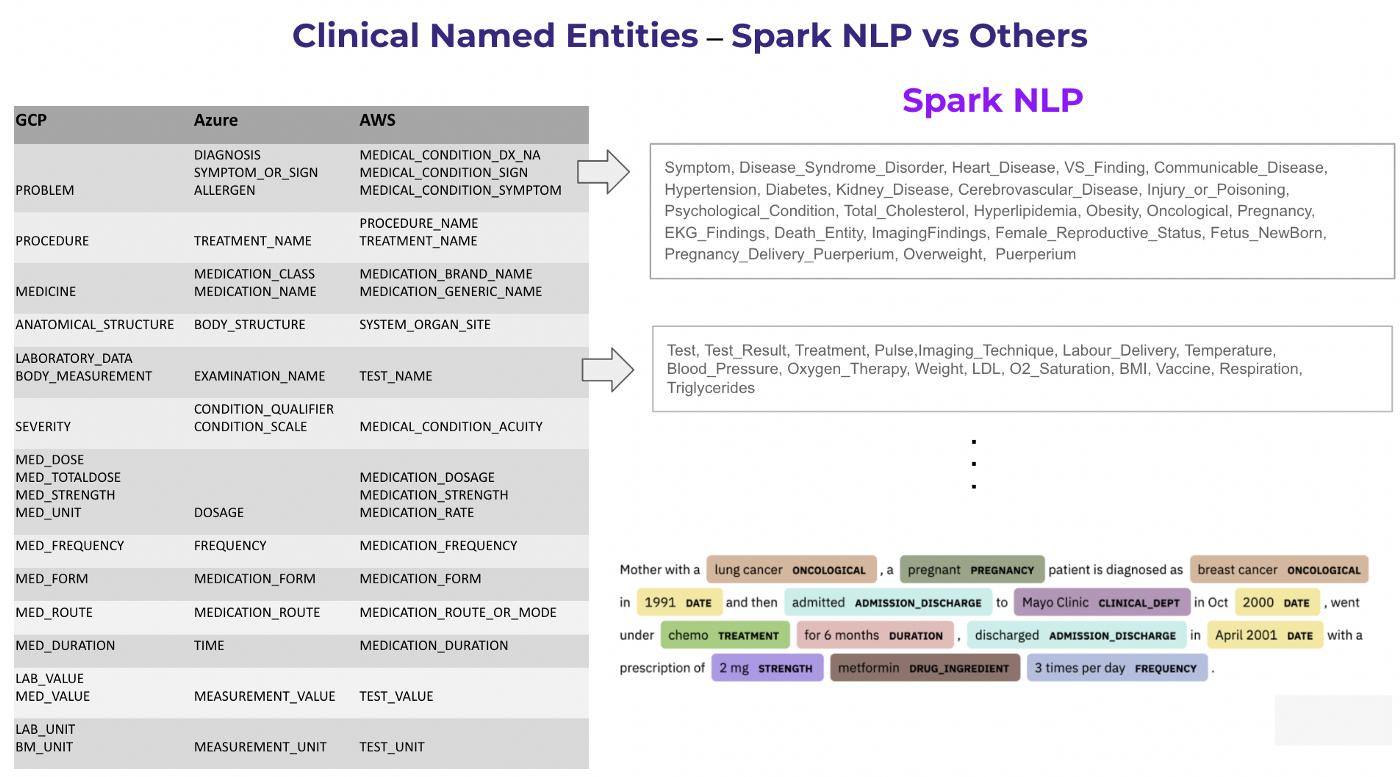
Entity mapping across various cloud services and Spark NLP
Entity Resolution
Being the only medical terminologies supported by 3 major cloud providers at the same time, we picked ICD10CM, SNOMED CT, and RxNorm terminologies to do the benchmarks. We asked clinical annotators to assign top-5 most appropriate codes from each terminology for each entity that makes sense. For instance, if there is an entity such as ‘ diabetes’ (labeled as a clinical condition), they assigned the most probable five ICD10CM codes (E11, E10, E23.2, Z83.3, etc.) for that entity given the entire context (sentence context). If it’s a medication-related entity such as ‘metformin 100 mg’, they assigned the top five RxNorm codes (861024, 861026, 861025, etc.) for that drug.
De-Identification
De-Identification is a process that needs to be applied to de-identify (anonymize) or obfuscates (replacing with fake entities) PHI (protected health information) data from clinical notes. It is offered out of the box as part of these cloud services at various entity levels. Here are the entities covered by all of the cloud APIs at the same time:
Date, Age, Doctor, Patient, Hospital, ID, Location, Phone
Spark NLP for Healthcare comes with 50+ different NER models to support de-identification tasks from 6 spoken languages (English, German, Spanish, Italian, French, Portuguese). It also comes with several pretrained pipelines that the deid NER models are supported with several rule-based contextual parsers to fill the gaps (i.e. when NER fails to detect a date, regex-based modules can catch that anyway).
In Spark NLP for Healthcare, we have two types of deidentification NER models: Generic (7 types of entities) and Subentity (13 types of entities). More information regarding deidentification modules can be found in this Colab notebook. In this study, we used pretrained deidentification pipeline with no additional fine-tuning.
Comparison Results
Now it is time to share the benchmarks! First of all, we aim to provide fully reproducible results with the code and the annotated dataset; and we’ll share the resources very soon. In the following subsections, we’ll cover the binary comparisons (Spark NLP vs one of the cloud APIs), along with the number of the entities. Please mind that the number of entities differs from one comparison to another due to the overlapping entities provided by the respective APIs.
Named Entity Recognition
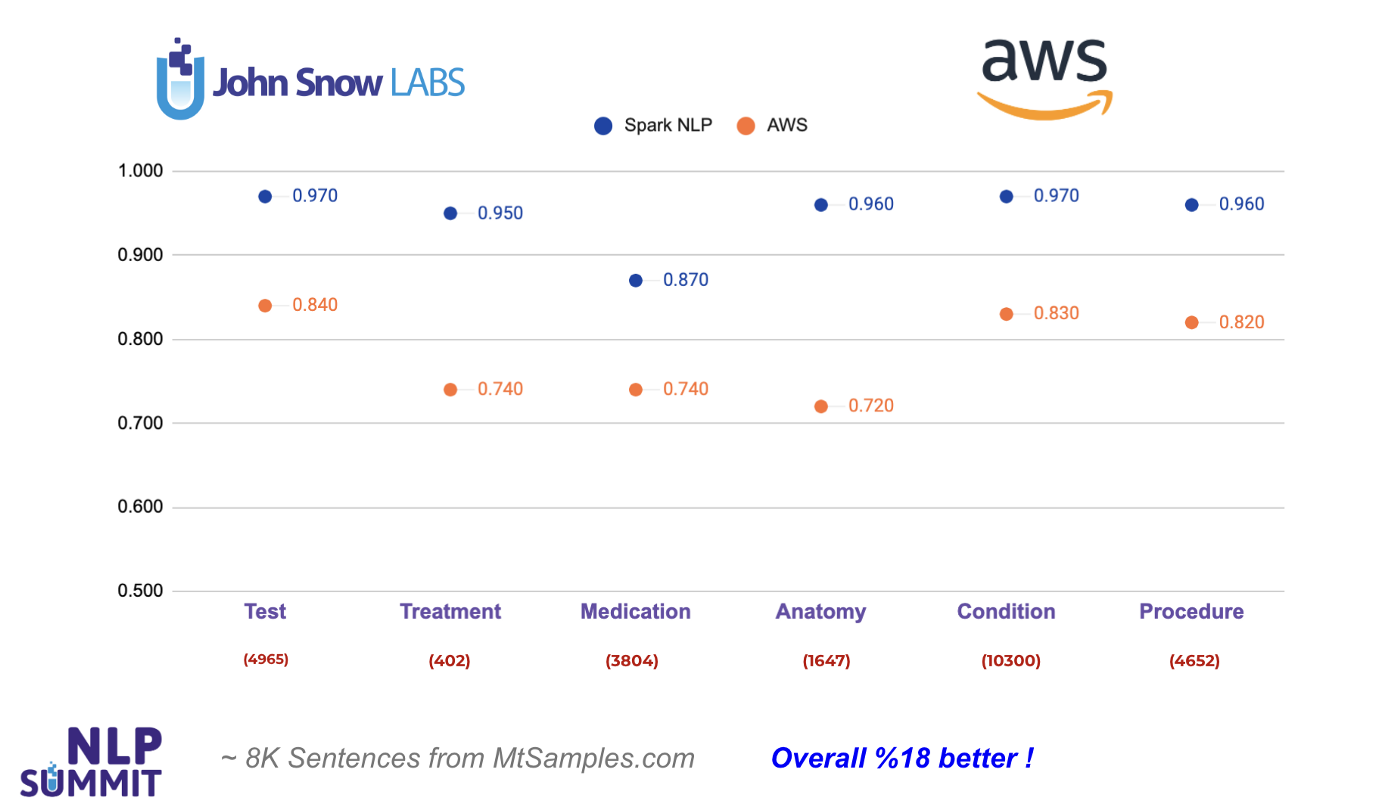
Let’s start with Amazon Medical Comprehend, one of the most popular healthcare NLP APIs out there. We managed to find 6 common entity types returned by AWS and mapped with the entities in Spark NLP using ner_jsl and ner_clinical_large models: Test, Treatment, Medication, Anatomy, Condition, Procedure.
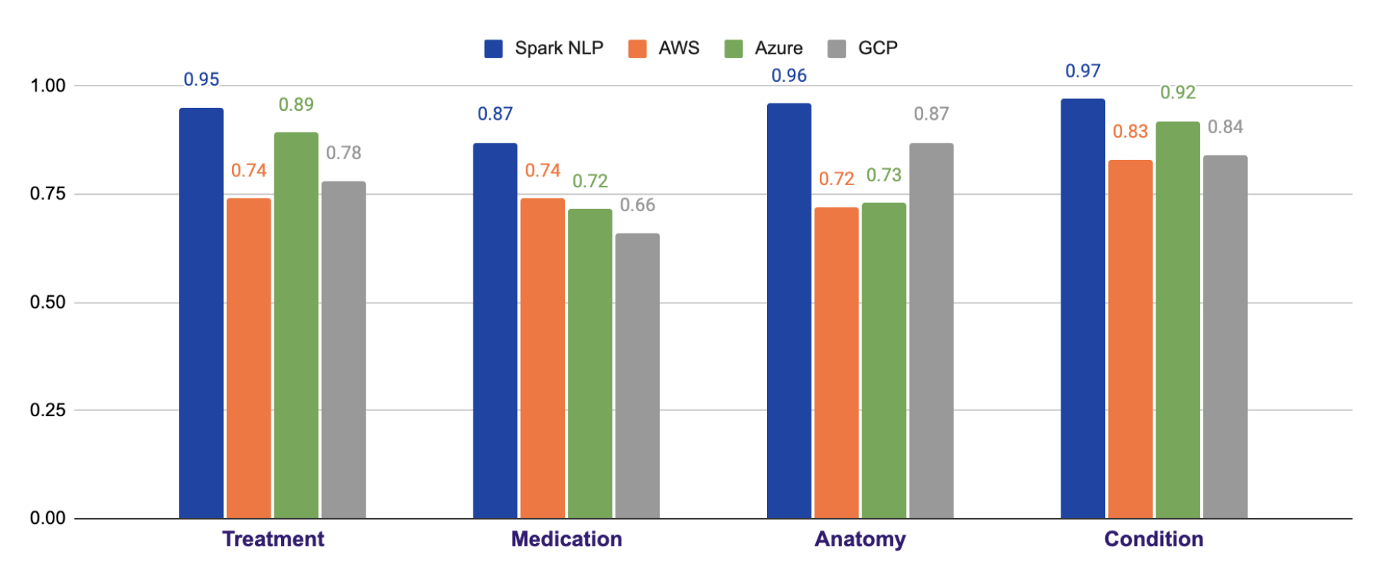
As you can see from the chart below, Spark NLP does 13% better when it comes to Test entities, and 19% better in Treatment entities. The largest difference is observed in Anatomy entities by 24%. In all the entities compared, Spark NLP performs better in all of them and exceeds AWS by 18% on average. The numbers in red puntos under each entity on the chart’s x-axis denote the number of tokens for the corresponding entity. That is, out of 10,300 Condition-labeled (clinical disorders, symptoms, etc.) tokens, AWS fails to detect 1,300 of them while Spark NLP fails only with 300 of them (makes more than 4x less error).
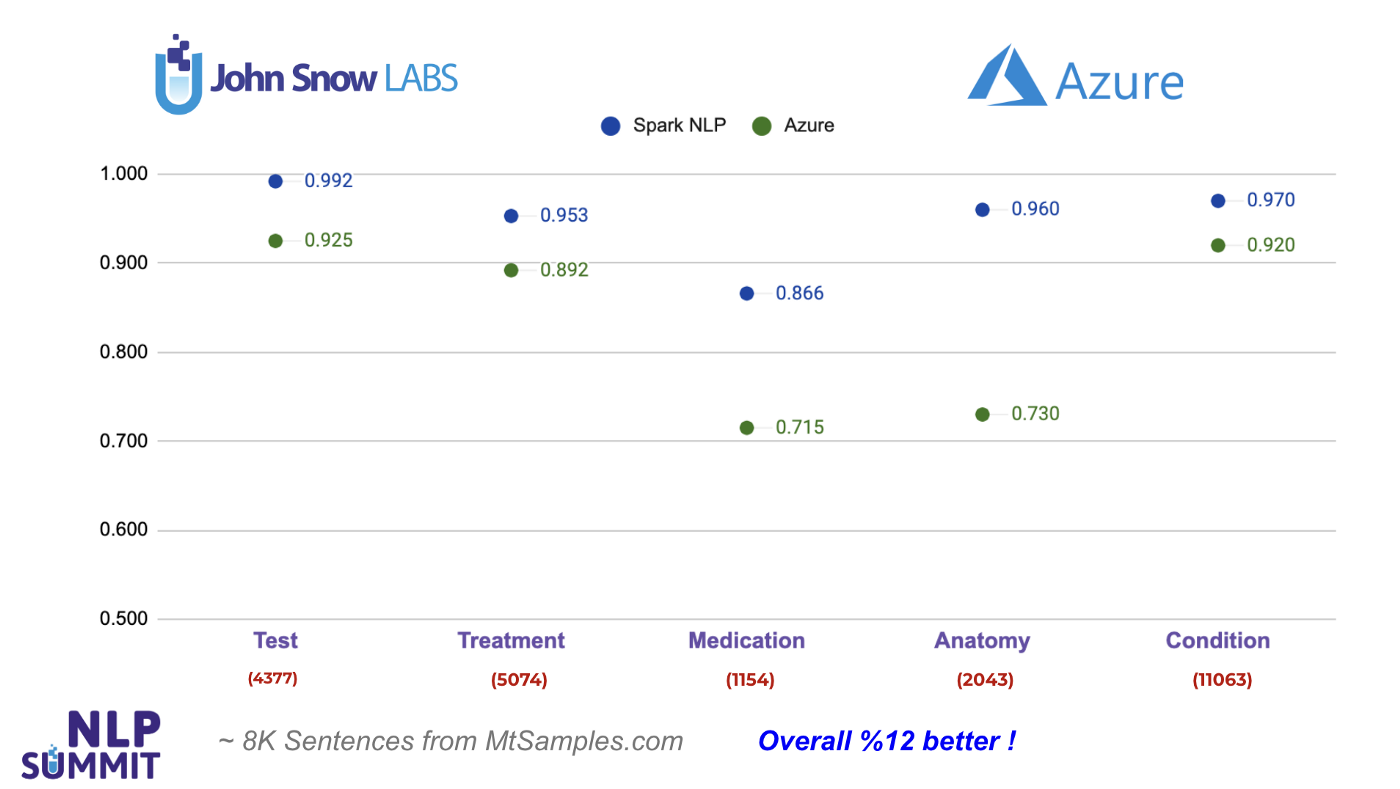
Next, we’ll study Azure Text Analytics for Health API. We see 5 common entity types returned by Azure that can be mapped with the entities in Spark NLP using ner_jsl and ner_clinical_large models: Test, Treatment, Medication, Anatomy, Condition.
As you can see from the chart below, Spark NLP does 7% better when it comes to Test entities, and 15% better in Medication entities. The largest difference is observed in Anatomy entities by 23%. In all the entities compared, Spark NLP performs better in all of them and exceeds Azure by 12% on average. For instance, out of 2,043 Anatomy-labeled (body parts) tokens, Azure fails to detect 550 of them while Spark NLP fails only with 80 of them (makes more than 6x less error).
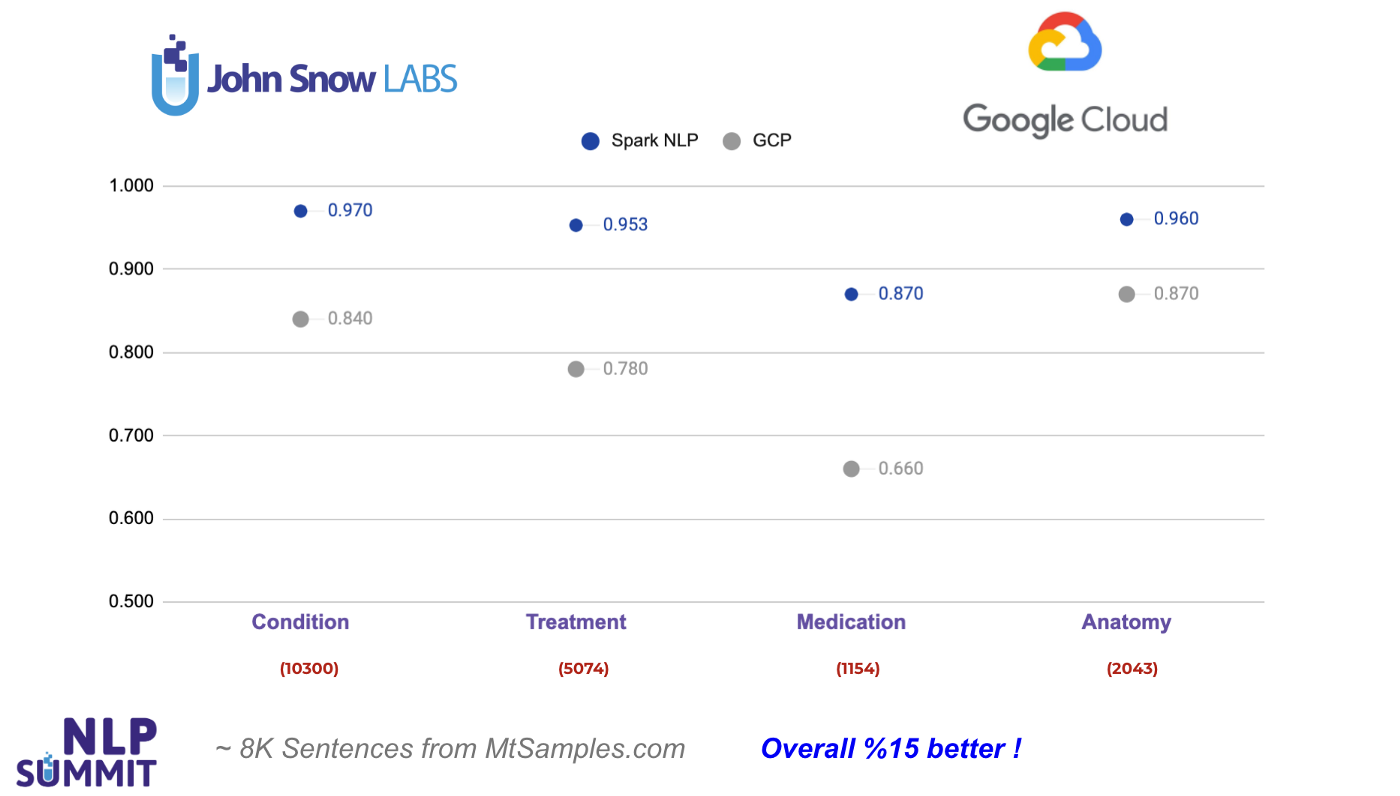
Finally, let’s check out Google Cloud Healthcare API. We see only 4 common entity types returned by GCP that can be mapped with the entities in Spark NLP using ner_jsl and ner_clinical_large models: Condition, Treatment, Medication, Anatomy.
As you can see from the chart below, Spark NLP does 13% better when it comes to Condition entities, and 17% better in Treatment entities. The largest difference is observed in Medication entities by 21%. In all the entities compared, Spark NLP performs better in all of them and exceeds GCP by 15% on average. For instance, out of 1,154 Medication-labeled (drugs, dosages, etc.) tokens, GCP fails to detect 390 of them while Spark NLP fails only with 150 of them (makes more than 2x less error).
Here is the overall comparison of the common entities from all the other cloud APIs. As depicted clearly, Spark NLP exceeds each one of them by a large margin in all the entities compared.
Entity Resolution
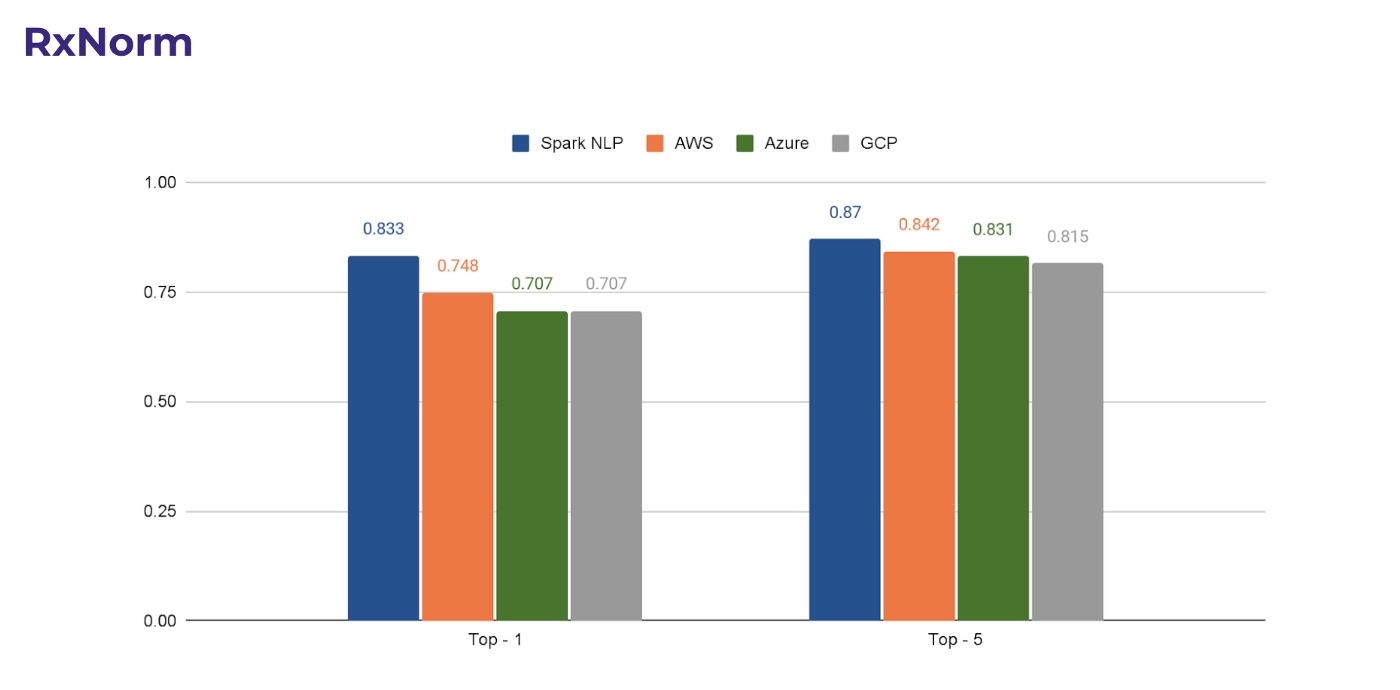
Let’s start with RxNorm, a common drug terminology. RxNorm provides normalized names for clinical drugs and links its names to many of the drug vocabularies commonly used in pharmacy management and drug interaction software.
As you can see from the following chart, Spark NLP can match the top-1 code 83% of the time while its closest competitor AWS can only match 75% of the time. When it comes to matching top-5 terms, the difference between Spark NLP and others narrows down but Spark NLP still leads by a small margin (3%).
As you can see from the following chart, Spark NLP can match the top-1 code 82% of the time while its closest competitor AWS can only match 64% of the time. When it comes to matching top-5 terms, the difference between Spark NLP and others narrows down but Spark NLP still leads by a large margin (16%) compared to the next best one. The reason for such a large margin can be attributed to the contextual sBert-based clustering technique that Spark NLP for Healthcare adopts via various weighting regimes to let the model maps to the right code by checking the entire context that which the entity lives in.
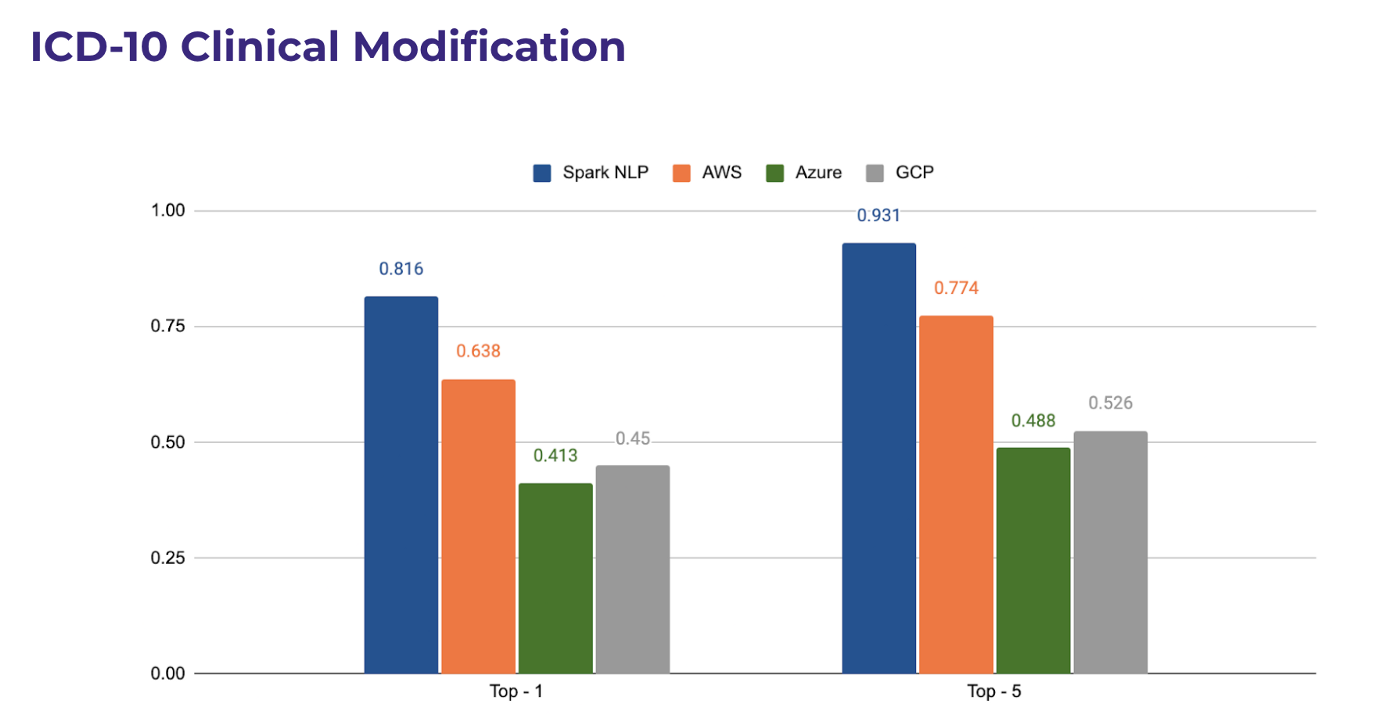
For instance, imagine a sentence talking about a historical condition of gestational diabetes. If NER returns only ‘gestational diabetes’ and we try to map with ICD10, it will map to O24.4 which corresponds to a 4-char code for ‘gestational diabetes’. However, since Spark NLP entity resolution algorithm can read the entire sentence and grab the context, even if NER returns only ‘gestational diabetes’, the embeddings representation of that entity will contain information regarding ‘historical’ condition and it will map to Z86.32 that corresponds to 5-char code (a much granular level) for ‘personal history of gestational diabetes’.
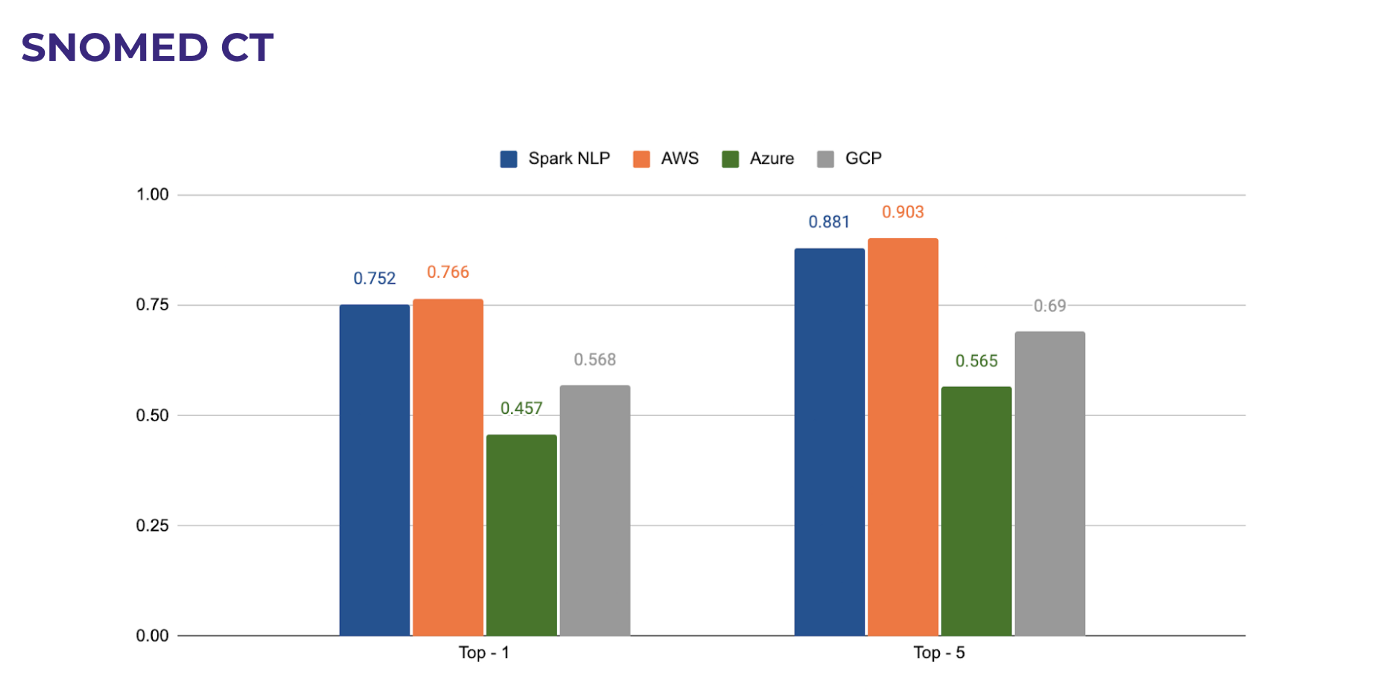
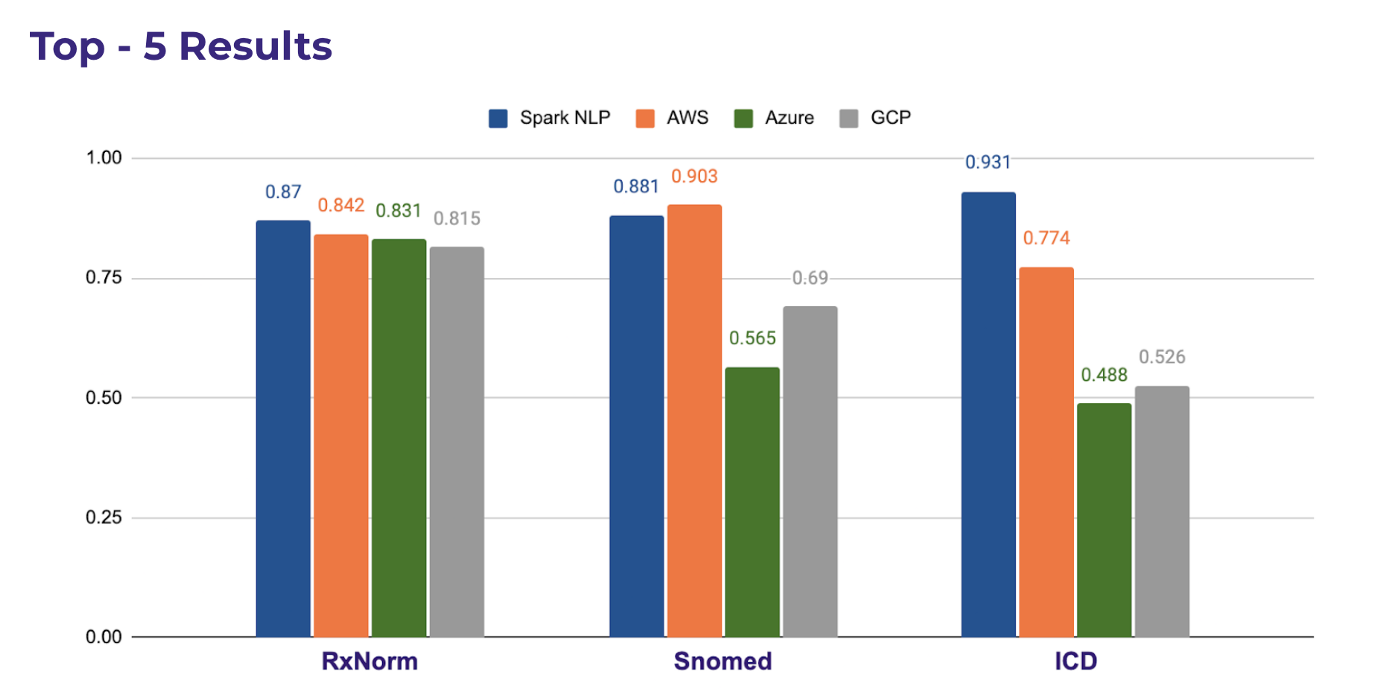
Finally, we can investigate SNOMED-CT (Systematised Nomenclature of Medicine) which isa systematic, computer-processable collection of medical terms. It allows a consistent way to index, store, retrieve, and aggregate medical data across specialties and sites of care.
As you can see from the following chart, t is the only medical terminology that Spark NLP can do a little bit worse only by 1% compared to its closest competitor AWS. It already exceeds Azure by 30% and GCP by 17%. When it comes to matching top-5 terms, the difference between Spark NLP and others still holds true.
Here is the overall comparison of the top-5 resolutions of common terminologies from all the other cloud APIs.
De-Identification
As stated above, Spark NLP for Healthcare has data de identification tools to de-identify clinical notes in 6 spoken languages. Here are the supported languages and the accuracy metrics for each one of them. This is the only library that can support that many languages out of the box with zero code change (switching from one language to another is as easy as using two-letter language symbols while downloading the models).
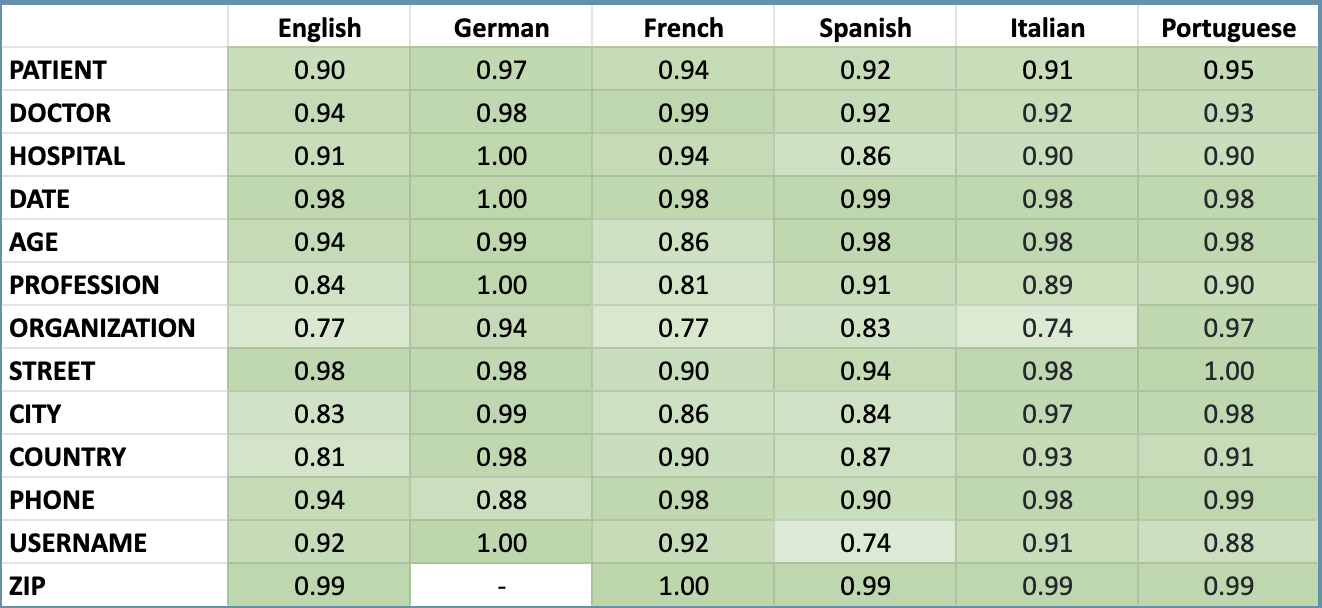
Spark NLP for Healthcare De-Identification NER models F1 scores
As the other cloud solutions support De-Identification only in the English language, we can compare the performance as shown below.
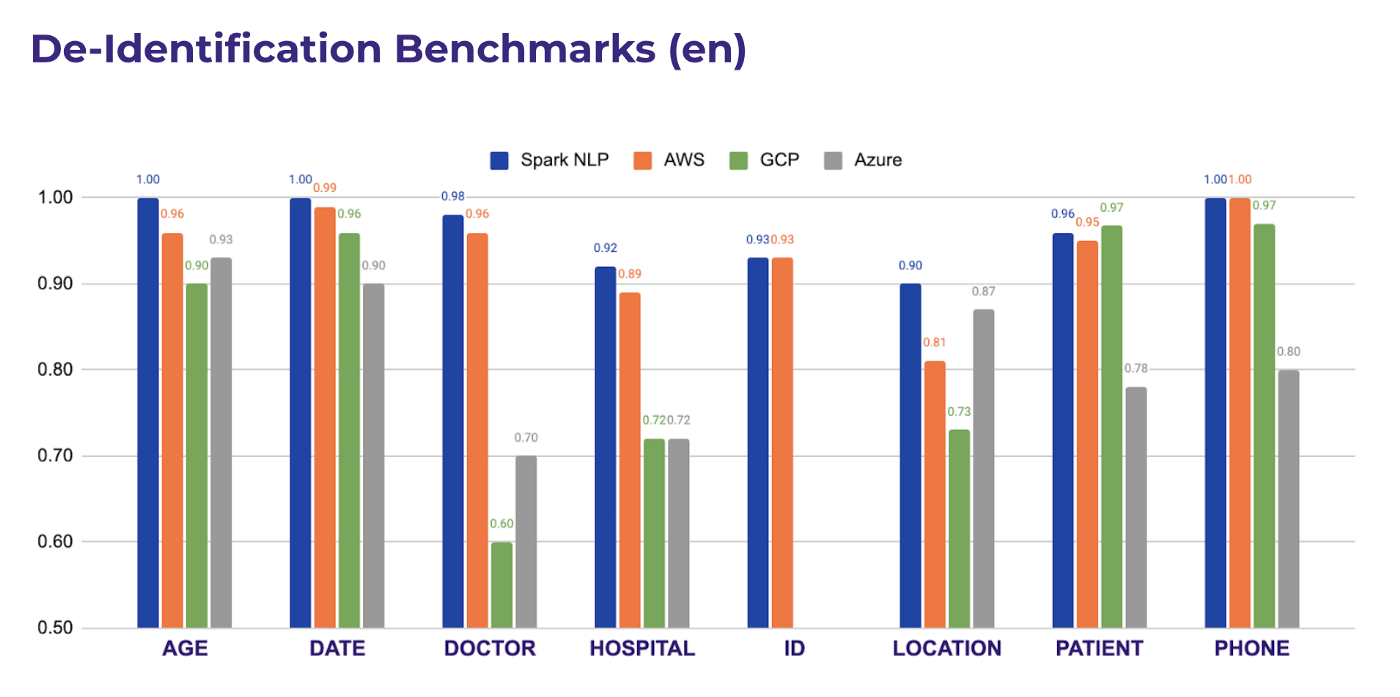
As you can see, Spark NLP performs better than all the other cloud services in every entity type evaluated. These results can be reproduced by using the Colab notebook we shared in our repo.
Given the simplicity of employing a De-Identification service with a one-liner in Spark NLP and all can work in air-gapped environments with no internet connection, it is clear that Spark NLP is a leading solution in this domain. Here is what you can achieve in Spark NLP while running a De-Identification pipeline in only one line of code with no fine-tuning.
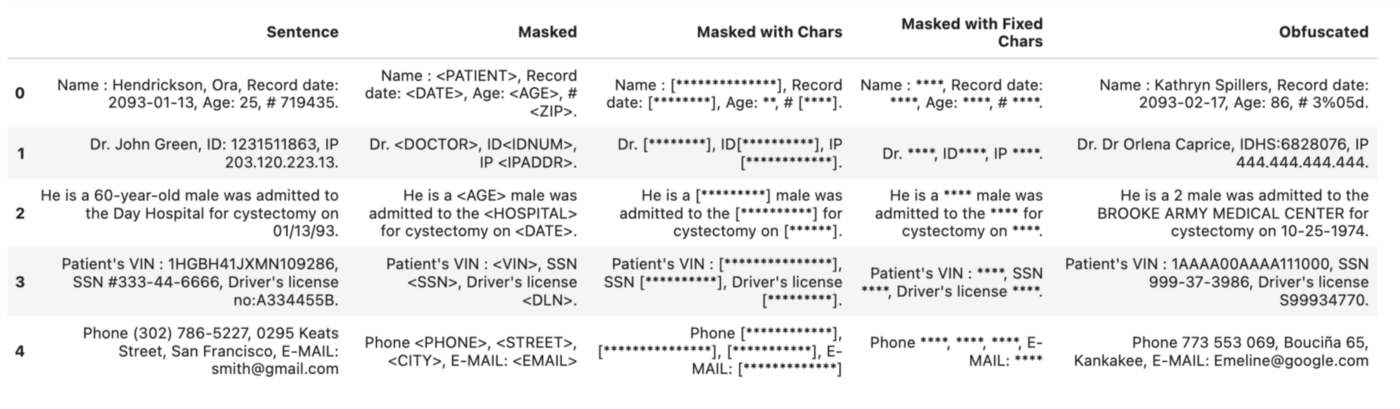
Conclusion
Spark NLP for Healthcare comes with 600+ pretrained clinical pipelines & models out of the box and is performing way better than AWS, Azure, and Google Cloud healthcare APIs by 18%, 12%, and 15% (making 4–6x less error) respectively on extracting medical named entities from clinical notes. It’s also doing better consistently on entity resolution to map clinical entities to medical terminologies. Here are the other advantages of using Spark NLP for Healthcare against cloud APIs:
- Spark NLP for Healthcare offers highly customizable models and pipelines that can be shipped within the existing codebase while cloud APIs are basically black-box services that you should be OK with whatever you get in.
- The DL models shipped within Spark NLP for Healthcare can be fine-tuned and extended using the custom terminologies and new datasets annotated in-house.
- Spark NLP is the only NLP library out there that can scale over Apache Spark clusters to process large volumes of data.
- Spark NLP for Healthcare can work in air-gapped environments with no internet connection and requires no other dependency other than Spark itself. Given that Healthcare APIs offered by major cloud providers require an internet connection, this is a highly important aspect when it comes to preserving the privacy of sensitive information (PHI data) while running some analytics.
- Healthcare APIs offered by major cloud providers are pay-as-you-go solutions and can cost too much when it comes to processing a large volume of clinical texts. On the other hand, Spark NLP for Healthcare is licensed once and has no limitation in that regard. So, you can process TBs of clinical notes with the state of the art accuracy without paying anything other than the one-time annual license.
I also gave a keynote speech on this very same topic that is recorded at the Healthcare NLP Summit ’22. I suggest you check out all the summit videos shared online to get to learn from the industry experts.
You can follow us on medium and Linkedin to get further updates or join the NLP for Healthcare to get instant technical support from the developers of Spark NLP. If you want to learn more about the library and start coding right away, please check our certification training notebooks.
References
[1] https://gradientflow.com/2021nlpsurvey/
[2] Kocaman, V. and Talby, D., 2021. Spark NLP: Natural Language Understanding at Scale. Software Impacts, 8, p.100058. (https://www.sciencedirect.com/science/article/pii/S2665963821000063)
FAQ
- How does Spark NLP for Healthcare outperform AWS, Azure, and Google Cloud in clinical NLP tasks?
Spark NLP consistently delivers a way fewer errors in extracting medical named entities from clinical notes compared to cloud providers. It also offers broader support for clinical taxonomies, entity resolution, and de-identification, making it more precise and reliable in real-world healthcare workflows. - What clinical entities can Spark NLP for Healthcare extract that others cannot?
Spark NLP supports over 400 different entities across medical conditions, treatments, anatomy, medications, and procedures, whereas cloud APIs typically cover fewer categories and taxonomies. This allows for more granular and accurate clinical documentation and analytics. - Why is de-identification an important benchmark in healthcare NLP?
De-identification ensures that protected health information (PHI) is anonymized while preserving the clinical context. Spark NLP supports de-identification in multiple languages and achieves higher accuracy than AWS, Azure, or Google Cloud, making it especially valuable for global healthcare organizations that must comply with privacy regulations. - Can Spark NLP be deployed in secure or offline environments?
Yes. Unlike cloud APIs, Spark NLP can run in air-gapped environments with no internet connection. This makes it an ideal solution for hospitals and research institutions that must comply with strict data privacy regulations such as HIPAA and GDPR. - What are the cost and customization advantages of Spark NLP compared to cloud APIs?
Cloud APIs follow a pay-as-you-go model, which can become expensive when processing large volumes of clinical text. Spark NLP, on the other hand, is licensed once annually with no usage limits. It also allows full customization and fine-tuning on in-house datasets, while cloud APIs remain largely black-box solutions.




