
























































There’s always been some debate over what data operations means and still term DataOps is undergoing a process of getting commonly acceptable definition. But for sure interest to it is rapidly growing in IT communities and it is already clear that DataOps is becoming a new trend.
So why DataOps is more and more in demand? Today is no longer enough to just deploy analytics platform to production as part of the Data Engineering activities. Very soon you will face a need to maintain the data used by a system and start Data Curation initiative. Mind that the data should go through all five level of Data Quality maturity model. Looks complex enough? And this is not the end of the efforts! Don’t forget the need to do Data Integration and provide Data Security & Privacy.
Here at John Snow Labs we’ve got quite a bit of experience in analytics platform maturity areas and we believe we know how to help you accelerate data science. We’ve summarized the most typical problems, pain points and complains that we get when we start working with new clients.
This blog post kicks off a series of blog posts in which we will give recommendations on doing your DataOps right.
In this first post, we will focus on Data Engineering.
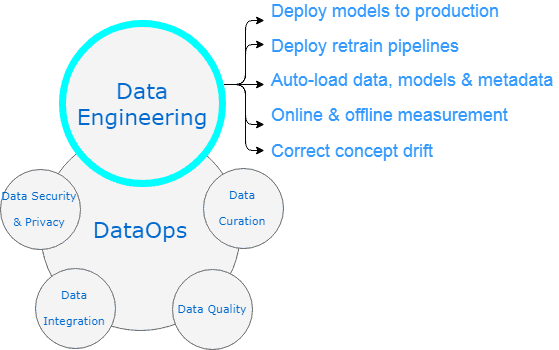
Data Engineering
Use list or picture
- Deploy models to production
- Deploy retrain pipelines
- Auto-load data, models & metadata
- Online & offline measurement
- Correct concept drift
Data Scientists are good at prototyping machine learning models, but may experience hard times while deploying models to production especially when it comes to maintenance including availability, reliability and security of the platform. These two activities – building model and deploying it to production environment at scale – demand completely different skillsets. On one hand, data scientists conduct research, perform analysis and implement machine learning projects. They are busy with visualizing data and preparing reports. Most of the time they have degree in statistics. On the other hand, models’ deployment usually requires computer science education, knowledge of programming languages (Java, Scala, C++, Python) and parallel data processing frameworks (Apache Spark, Hadoop MapReduce). You are lucky if you have a person in team who is equally good at both, but most of the time there needs to be an engineer who will partner with Data Scientist to make prototyped model work smoothly on production.
To keep the model effective requires deploying retrain pipelines which is rather time-consuming if the process is not automated. This automation is also a job of the data engineer.
Another way to save time (and ultimately budget) utilizing data engineer is to setup auto-load of data, models & metadata. It was never so easy to push new data and retrain models on production.
Did you ever check how accurate is your model? Or what is the performance? A crucial component to ensuring the success of your project is being able to measure model performance. If you had online & offline measurements of the model, you would be already looking for ways to improve those indicators. The more performant your model is, the more extensive would be operational use of your model in production. Remember a very important point: do not treat performance measured on test datasets as real performance of data analytics platform. Compare performance on several independent production-like datasets. Although performance is an important measurement, you should always keep balance between spending efforts on performance optimization and improvement of accuracy of data analytics platform. Rate of correct predictions from all predictions made is an ultimate key to success. Depending on area of application and corresponding cost of error even 99% of accuracy may be not enough.
Also specialists tend to forget how crucial is to keep models up-to-date and don’t let them degrade with time. How many times did you see the concept drift (also known as dataset shift) when accuracy of the model dropped from 99% to almost 50%? Concept drift is a generic term covering changes and corresponding computational problems as time passes. These changes may be of different types and there are different adaptation techniques. Thus, a generic solution is hardly possible. A reliable detection of such changes must be used to maintain high performance and meaningful analyses of datasets.
Role of data engineer is becoming extremely important as you look for a person who will assist you with those five problems mentioned above. You may also request help from JSL specialists who have considerable experience in resolving such situations in production. How you decide to proceed further – tackle those potential problems or ignore them – is up to you. Important that you’ve got the awareness and can evaluate the risks.
In this blog post, we discussed levels of maturity model of productive analytics platform focusing on Data Engineering.
In the future blog posts in this series, we’ll cover other levels of maturity model of productive analytics platform:
- Data Curation
- Data Quality
- Data Integration
- Data Security & Privacy
To enhance your understanding of data engineering, consider exploring the impact of Generative AI in Healthcare on analytics. Additionally, the rise of the Healthcare Chatbot can significantly improve patient engagement and data collection processes.




