























































Why We’re Different
Medical Data
De-identification
De-identify clinical notes, PDFs, DICOM images, structured data, and FHIR resources with regulatory-grade accuracy. Process billions of records without moving data from your secure environment. Includes Expert Determination, tokenization, and consistent obfuscation.

Used by Providence Health to De-identify
2 Billion Patient Notes
The largest independently validated and peer-reviewed de-identification deployment in healthcare
2B
Notes Processed
>99%
Accuracy
0
Red Team Re-identifications
500K
Notes in 2.5 Hours
Independent Validation Process
- Consistent obfuscation, date shifting, and tokenization per patient
- Equity analysis across gender, age, ethnicity, and geography
- 3-month "red teaming" by external security provider
- Manual review of 35,000+ notes by compliance team
- Validated at unprecedented scale on 2 billion real-world patient notes
- Adversarial testing on 790 patients with zero re-identifications
- Surpasses triple manual review by domain experts
- Published peer-reviewed methodology and results
Why This is the Most Widely Deployed
True Multimodal Processing
Consistent de-identification across modalities—unstructured clinical text, PDFs, DICOM images, structured tables, and FHIR resources. One solution, one pipeline, zero inconsistencies.
6 Data Formats Supported
Expert Determination Available
Complete HIPAA Expert Determination process with legal documentation. Not just de-identification—full regulatory compliance with auditable validation and statistical risk analysis.
HIPAA Compliant
De-identify Data Where It Lives
Process data in-place within your secure environment—Databricks, Snowflake, Azure, or AWS. Zero data movement. Everything happens in memory. Your data never leaves your control.
Zero Data Movement
Unmatched Accuracy at Scale
99%+ PHI detection rate proven at 2 billion note scale. Validated through independent audits and red team testing. Surpasses triple manual review by domain experts.
99%+ Accuracy
Deterministic &
Consistent
Same PHI always produces the same token. Maintains longitudinal patient linkage across records. Built for reproducible, auditable results.
Production Ready
Cost-Effective
at Scale
80%+ cheaper than API-based solutions. Fixed-cost deployment with no per-token fees. Proven economics at billion-record scale with predictable, transparent pricing.
80% Cost Savings
The Data De-identification Process
99.9%+ PHI Removal. HILT-Validated. Peer-Reviewed. Proven at Scale
1
Analyze

- Risk analysis
- Legal requirements review
- HIPAA Safe Harbor, HIPAA Expert Determination
- CCPA
- GDPR pseudoanonymization, GDPR anonymization
- Quality assurance strategy & process

2
Identify

- ID, name, email, patient ID, SSN, credit card, address, birthday, phone, URL, license number
- Physician name, hospital name, profession, employer, affiliation
- Racial or ethnic origin, religion, political or union affiliation, biometric or genetic data, sexual practice or orientation
3
Measure
- Cleanroom AI Platform (on-site)
- Annotation tool
- Active learning
- Accuracy Measurement & agreement processes
- Correct sampling
- Multi-lingual
4
De-identify
We support:
- Tabular (headers, values)
- Text (NER, text matching)
- PDF: Text or Scanned
- Images(OCR & metadata)
- DICOM (OCR & metadata)
So you can:
- Replace (or delete a field)
- Mask (hash identifiers or shift dates)
- Obfuscate (name, locations, organizations)
- Generalize (disease codes, dates, addresses)

5
Monitor
- Ongoing measurement & model improvement
- Missed sensitive data
- Incident response
- GDPR & CCPA requests
- Emergency unblinding
- Audits
See It In Action
De-identification Across All Medical Data Types
Works seamlessly with any healthcare data format—maintaining structure while removing PHI
Clinical Text Notes
Automatically identify and obfuscate 23+ PHI entity types including patient names, doctors, hospitals, medical records, locations, dates, and contact information.
Original Text

De-identified Text

PDF Documents (Text & Scanned)
Process PDFs directly—preserving original structure and formatting while removing PHI with 94%+ accuracy. Handles both digital and scanned documents with built-in OCR, ensuring HIPAA-compliant de-identification without document recreation.
Original Text

De-identified Text

DICOM Medical Images
Redact burned-in PHI using intelligent pixel inpainting with complete metadata de-identification. Handles all DICOM modalities while maintaining image utility, saving de-identified data into DCM format for further processing.
Original Text

De-identified Text
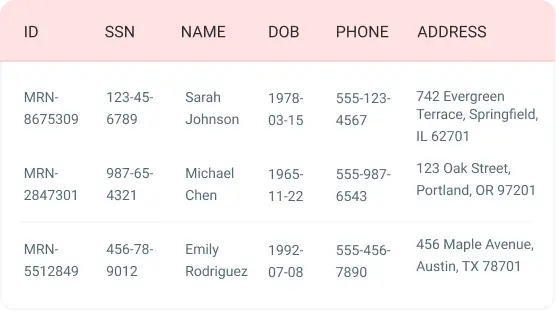
Structured Data & Databases
De-identify PHI from structured datasets automatically while enforcing GDPR and HIPAA compliance and maintaining linkage of clinical data across files. Process millions of records with consistent obfuscation.
Original Text
De-identified Text
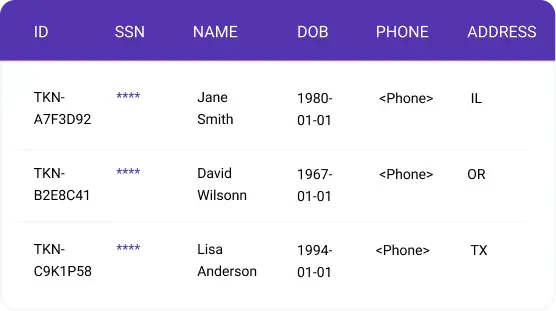
Consistent Tokenization & Obfuscation
Protect patient privacy without breaking data relationships: consistent tokenization ensures the same individual receives identical replacement values across all documents, preserving referential integrity for research and analysis while meeting regulatory requirements.
Original Text

De-identified Text

Link Multimodal Patient Data Over Time
Maintain complete patient context across longitudinal records—preserving temporal relationships, narrative continuity, and data linkability while ensuring privacy through consistent de-identification and intelligent date shifting.
Original Text

De-identified Text

Global Coverage
Multi-Language Support Across Healthcare Systems
De-identify clinical documents in 9+ languages with regulatory-grade accuracy. No fine-tuning required. Localized for multiple jurisdictions
US
English

GB
English

ES
Spanish

FR
French

DE
German

IT
Italian

PT
Portuguese

NL
Dutch

RO
Romanian

SA
Arabic

9+
Languages Supported
23+
PHI Entity Types Detected
99%
Detection Accuracy
Tailored to You
Customizable for Your Unique Requirements
Healthcare organizations have diverse data formats, custom identifiers, and specific compliance needs. Our solution flexibly adapts to your workflow – not the other way around.
Custom Entity Recognition
Define and train models to recognize your organization’s specific identifiers:
- Internal patient ID formats
- Custom medical record numbering
- Facility-specific codes
- Department identifiers
- Study participant IDs
Flexible Policies
Configure granular policies that balance data utility with privacy protection:
- Obfuscate names with realistic fakes
- Mask specific fields with asterisks
- Shift dates while preserving intervals
- Generalize locations (city → state)
- Tokenize for consistent linkage
Format-Specific Processing
Native support for every healthcare document format, preserving structure and content:
- Custom PDF templates and forms
- Proprietary EHR exports
- Legacy system formats
- Complex table layouts
- Embedded images and charts
Regulatory Compliance
Configure policies to meet your regulatory requirements:
- HIPAA Safe Harbor
- HIPAA Expert Determination
- GDPR compliance ready
- CCPA and state privacy laws
- Custom regulatory frameworks
Enterprise Integration
Seamless integration into your existing tech stack with robust API access:
- RESTful API Integration
- Real Time Processing
- Batch Processing
- Horizontal Scaling & High availability
- Full Audit Logs and Monitoring
Enterprise Security
Secured solution with multiple deployment options for any security posture
- End-to-end Data Encryption
- On-premise or Cloud Deployment
- Air-gapped Environments
- Zero Data Retention by Default
Peer-Reviewed, State-of-the-Art Accuracy
Can Zero-Shot Commercial APIs Deliver Regulatory-Grade Clinical Text DeIdentification?

Accepted at Text2Story Workshop at ECIR 2025
Beyond Accuracy: Automated De-Identification of Large Real-World Clinical Text Datasets

Machine Learning for Health (ML4H) 2023
Accurate Clinical and Biomedical Named Entity Recognition at Scale

Software Impacts, July 2022
Learn More
Watch Real-World De-identification Challenges Solved
See how healthcare teams tackle complex PHI removal: from messy clinical notes to billion-record databases, scanned PDFs to multimodal processing
Try It on Your Own Data
Run our pre-trained de-identification pipeline in a Google Colab notebook. See exactly how it works, test with your data, and customize for your needs.
Runs in One Click
Easy to Customize
Code Examples
