If your organization runs analytics on OMOP CDM and needs to deliver patient data to a clinical trial sponsor, a payer API, or a regulatory submission, you need a FHIR bundle that validates against the required implementation guide (for example, US Core 6.1.0). Getting there reliably — every record, every required element, every patient — is where many organizations encounter implementation challenges. Few mature OMOP-to-FHIR implementations are publicly available, the official standard doesn’t cover this direction, and the gap between a bundle that reads correctly and one that passes validation is larger than expected.
What is OMOP CDM?
OMOP CDM (Observational Medical Outcomes Partnership Common Data Model) is an open, community-developed standard for organizing observational healthcare data from sources such as electronic health records, claims, and laboratory systems. IP standardizes both data structure and clinical vocabularies, enabling researchers and healthcare organizations to perform consistent analytics, cohort discovery, and population-level studies across diverse datasets.
What is FHIR?
FHIR (Fast Healthcare Interoperability Resources) is an HL7 standard for exchanging healthcare information electronically. It represents clinical data as structured resources that can be shared through modern web APIs, allowing healthcare providers, payers, applications, and researchers to exchange and consume health data in a consistent and interoperable manner.
Two models, two purposes — and why one doesn’t speak the other’s language
OMOP CDM is a relational research schema. Clinical data from EHRs, claims, and lab systems are normalized into flat, interconnected tables, optimized for population queries and cohort building. The model prescribes a fixed set of standard vocabularies: SNOMED CT for conditions, RxNorm for drugs, LOINC for labs, CVX for vaccines. Every clinical event carries an OMOP concept ID that resolves through these vocabularies.
HL7 FHIR R4 is a nested, resource-based exchange standard. Clinical data is represented as typed resources (Patient, Encounter, Condition, Observation, MedicationRequest), each a self-contained JSON document with typed fields, required elements, and references to other resources by URL. FHIR does not prescribe a fixed vocabulary. It allows any code system and specifies terminology bindings per profile. The structural difference is fundamental: OMOP stores a condition (diagnosis or symptom) as a row in the condition_occurrence table by standardizing it as a condition_concept_id value; FHIR represents it as a Condition resource with a coded reference, a patient reference, an encounter reference, and profile-specific required elements.
US Core 6.1.0 is the U.S. implementation guide for FHIR (Fast Healthcare Interoperability Resources), the standard used to exchange healthcare data electronically. While FHIR provides the general framework for data exchange, US Core defines the specific U.S. requirements needed for interoperability and regulatory compliance. It standardizes how common healthcare data—such as patients, allergies, medications, conditions, immunizations, and laboratory results—should be represented, coded, and exchanged. The guide specifies which resources and data elements are required, which terminology standards apply, and how systems are expected to exchange and access data. As a result, a bundle that validates against base FHIR R4 may still fail US Core validation if it does not meet these additional requirements. Because these requirements change between releases, conformance to an older US Core version does not guarantee conformance to a newer one.
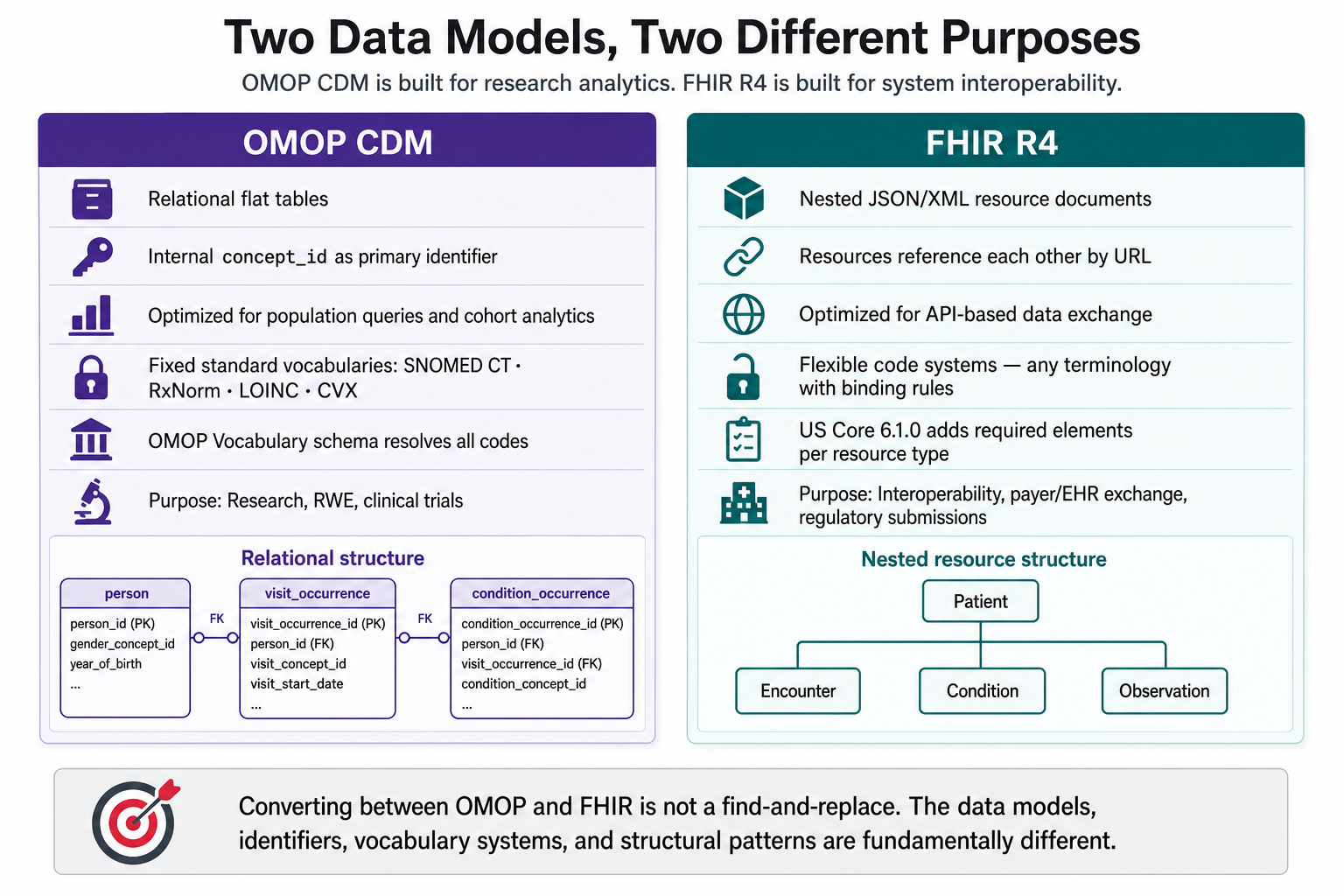
OMOP and FHIR solve different problems. Converting between them is not a find-and-replace.
A direction for which no broadly adopted standard mapping currently exists
The direction from FHIR to OMOP (ingesting clinical exchange data into a research database) has attracted significant investment. HL7’s official implementation guide covers it. Multiple open-source projects and the OHDSI community have built and maintained tools for it, because loading EHR data into OMOP for research is a well-understood problem with clear demand.
The reverse direction has not received the same attention. As of today the HL7 FHIR-OMOP Implementation Guide focused on FHIR-to-OMOP mappings and did not include normative OMOP-to-FHIR mapping artifacts. Open-source tools that attempt it are fewer, narrower in scope, and target older US Core versions. This asymmetry means most organizations that have built an OMOP research database have no mature, validated path to export that data back to FHIR for operational or regulatory use.
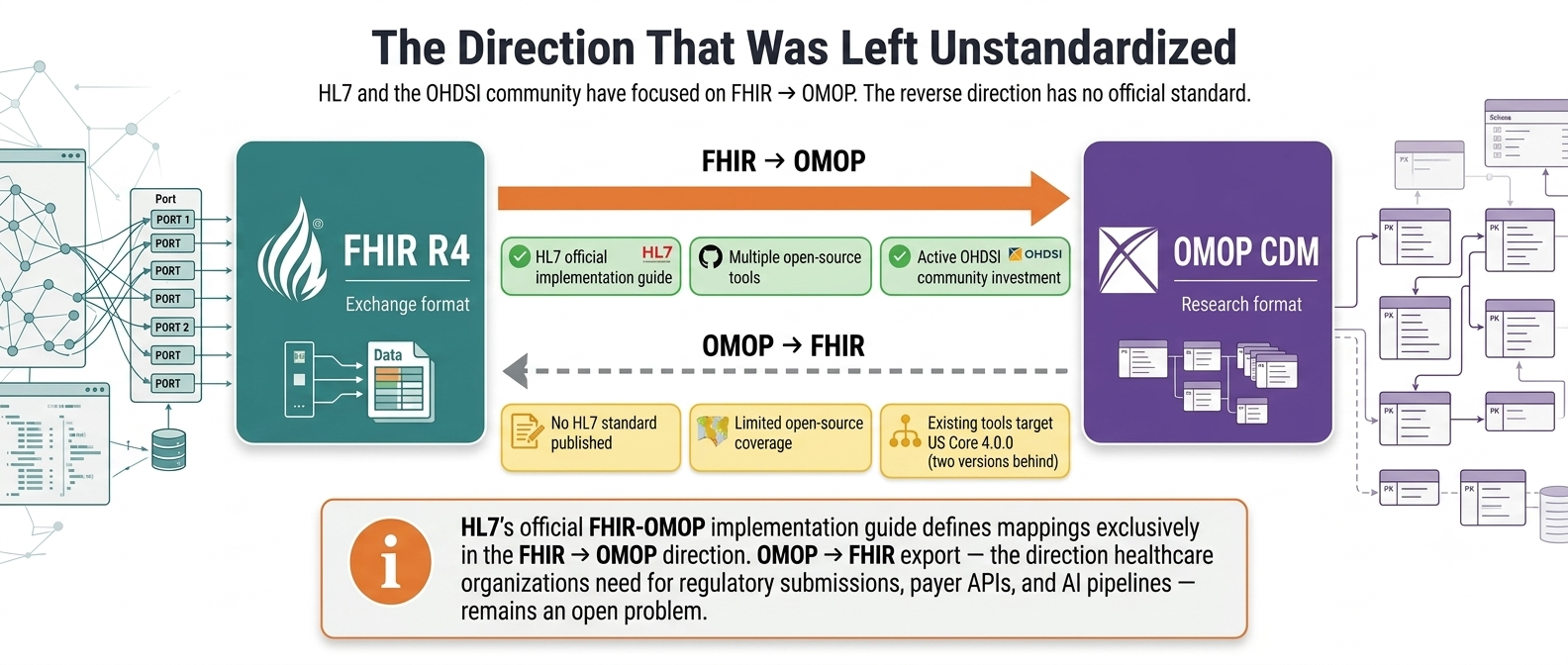
More paths lead into OMOP than out of it.
Getting from OMOP to a validated FHIR bundle is the direction the industry has not standardized — and where most organizations have no production-grade path.
What a complete, valid FHIR export actually requires
Three properties separate a reliable export from one that will break downstream.
Completeness. An OMOP patient record spans thousands of rows across a dozen clinical tables: visits, conditions, drugs, measurements, lab panels, clinical notes, providers, care sites, devices. A correct FHIR export accounts for every row, in the right resource type, with the right references. Most conversion approaches do not tell you how many rows they missed.
Context-dependent routing. A drug_exposure row in OMOP is not always a MedicationRequest. Depending on clinical context (how the drug was prescribed, administered, dispensed, or self-reported), it maps to one of five different FHIR resource types: MedicationRequest, MedicationAdministration, MedicationDispense, MedicationStatement, or Immunization. A measurement row maps to Observation in most cases, but a panel header row becomes a DiagnosticReport. Making these routing decisions correctly, at scale, requires coded logic.
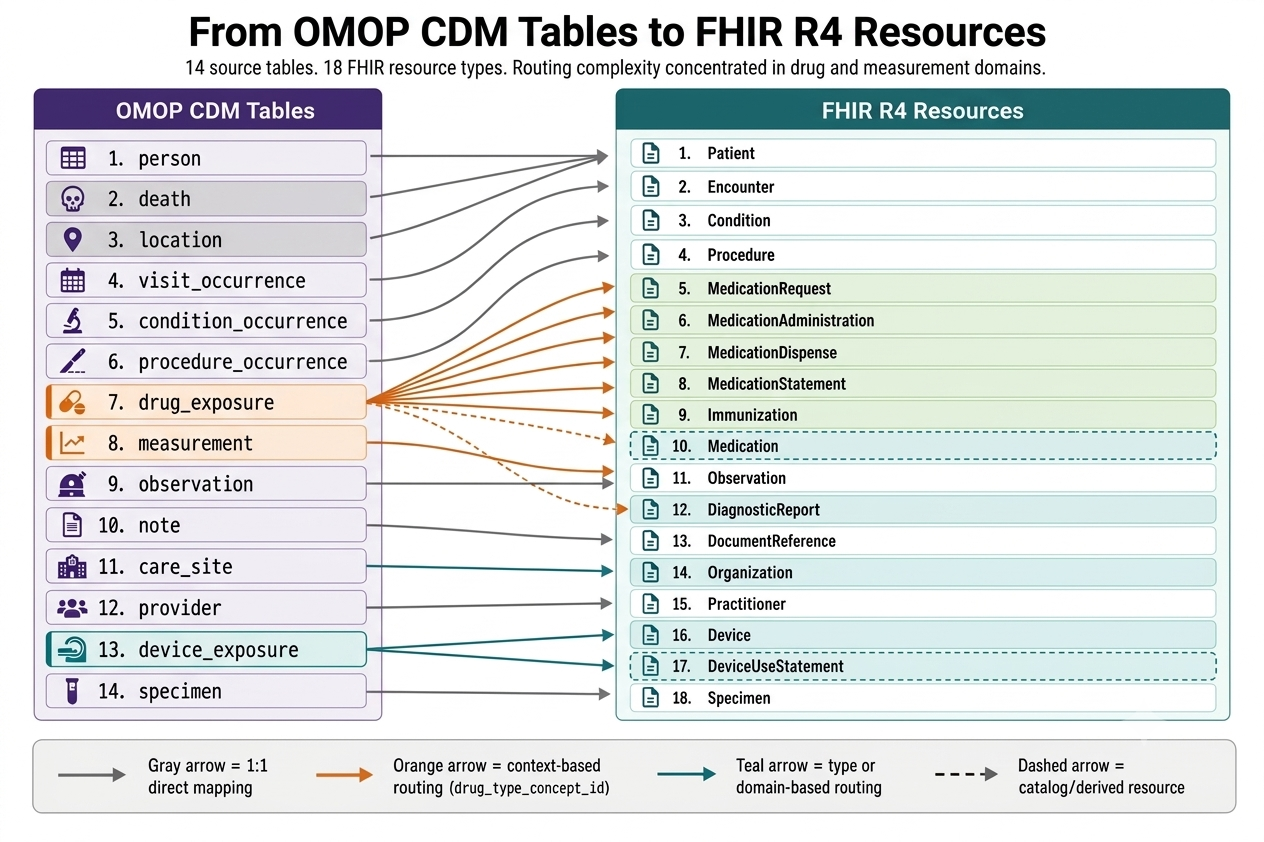
Most OMOP domains map cleanly to one FHIR resource. Drug exposures and measurements are the exceptions — each requires context-dependent routing to the correct resource type.
Conformance validation. A bundle that looks correct to a human reviewer can fail the HL7 FHIR Validator on required elements that are simply absent. US Core 6.1.0 requires specific structural elements (category slices, terminology system URIs, profile annotations) that do not exist in OMOP and must be derived during conversion. A bundle missing these elements will be rejected by any downstream system that validates input. The failure is invisible until that rejection happens.
Two additional requirements matter in regulated environments. Reference integrity must hold across the entire bundle: every Condition, Observation, and Procedure must reference the correct Encounter, Patient, Practitioner, and Organization. And reproducibility must be a design property: the same OMOP data must produce the same FHIR output every time, with resource identifiers traceable back to source rows.
Why existing tools and standards don’t close this gap
The HL7 standard covers only one direction. The official FHIR-OMOP implementation guide defines mappings exclusively from FHIR to OMOP. We examined the repository directly: every mapping artifact goes FHIR→OMOP (ingesting clinical data into a research database). There are no OMOP→FHIR maps. This is a gap in the specification itself.
Community implementations cover a partial slice of the OMOP model. Open-source tools typically handle the straightforward tables — Patient, Encounter, Condition — but omit or partially implement the harder domains. Drug exposure routing is a clear example: tools that skip it either drop medication records or collapse all drug events into a single resource type, losing clinical fidelity. In our review of publicly available OMOP-to-FHIR projects, we did not identify an implementation with DiagnosticReport support. (the resource for grouped lab panels) . Clinical notes (OMOP note table mapped to FHIR DocumentReference) are another common gap.
US Core version matters. The community tools that do cover broad resource types target US Core 4.0.0 — two major versions behind the current implementation guide. Profile requirements changed materially between 4.0.0 and 6.1.0. A bundle that conforms to the older version may fail validation against the current one.
Custom ETL scripts are the default fallback. Organizations write ad hoc Python or SQL transformations targeting the FHIR resources their specific downstream system needs. These scripts work until the US Core version changes, a new resource type is required, or a new patient cohort introduces a clinical profile the script never encountered. They also rarely include completeness checks: no mechanism confirms every source row produced a corresponding output resource.
The coverage gaps concentrate in the highest-volume OMOP domains: drug exposures, measurements and labs, clinical notes. An export that silently skips or misroutes these domains looks complete by record count while losing clinically significant data.
What the OMOP2FHIR converter in Patient Journey Intelligence covers
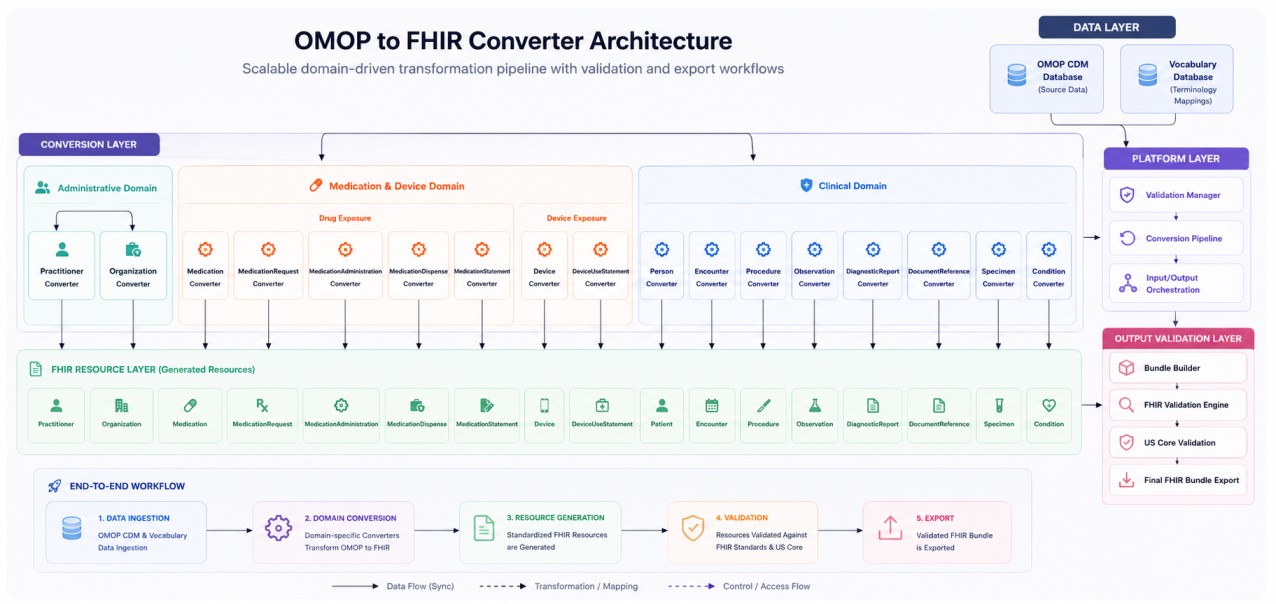 The OMOP2FHIR converter handles every OMOP clinical domain, including the high-volume tables that other approaches skip or misroute. The specific gaps identified above — drug routing collapsed into a single resource type, DiagnosticReport absent, clinical notes unmapped, US Core two versions behind, no completeness check — are each addressed by design. Tested on a cohort of 117 Synthea patients, the converter produced zero US Core 6.1.0 validation errors across all exported bundles, with full row-level coverage reporting. By comparison, in our benchmark, the highest-performing LLM run on a single patient achieved resource-count parity but failed on 248 validation errors across seven distinct conformance categories — after two rounds of prompt refinement.
The OMOP2FHIR converter handles every OMOP clinical domain, including the high-volume tables that other approaches skip or misroute. The specific gaps identified above — drug routing collapsed into a single resource type, DiagnosticReport absent, clinical notes unmapped, US Core two versions behind, no completeness check — are each addressed by design. Tested on a cohort of 117 Synthea patients, the converter produced zero US Core 6.1.0 validation errors across all exported bundles, with full row-level coverage reporting. By comparison, in our benchmark, the highest-performing LLM run on a single patient achieved resource-count parity but failed on 248 validation errors across seven distinct conformance categories — after two rounds of prompt refinement.
Full domain coverage across 14 OMOP source tables, producing 18 FHIR resource types. The converter maps person (joined with death and location tables), visit_occurrence, condition_occurrence, procedure_occurrence, drug_exposure, measurement, observation, note, care_site, provider, device_exposure, and specimen into their corresponding FHIR resources with complete reference integrity.
Drug routing that preserves clinical meaning. Most approaches either collapse all medication events into a single FHIR resource type or skip the routing entirely. That means a patient’s vaccination history, dispensing records, and self-reported medications all look the same in the output — or disappear. The OMOP2FHIR converter routes each drug event to the correct one of five medication resource types plus Immunization, preserving the clinical context of how and why the drug was recorded. This is where the widest coverage gap exists between existing tools and what a complete export requires.
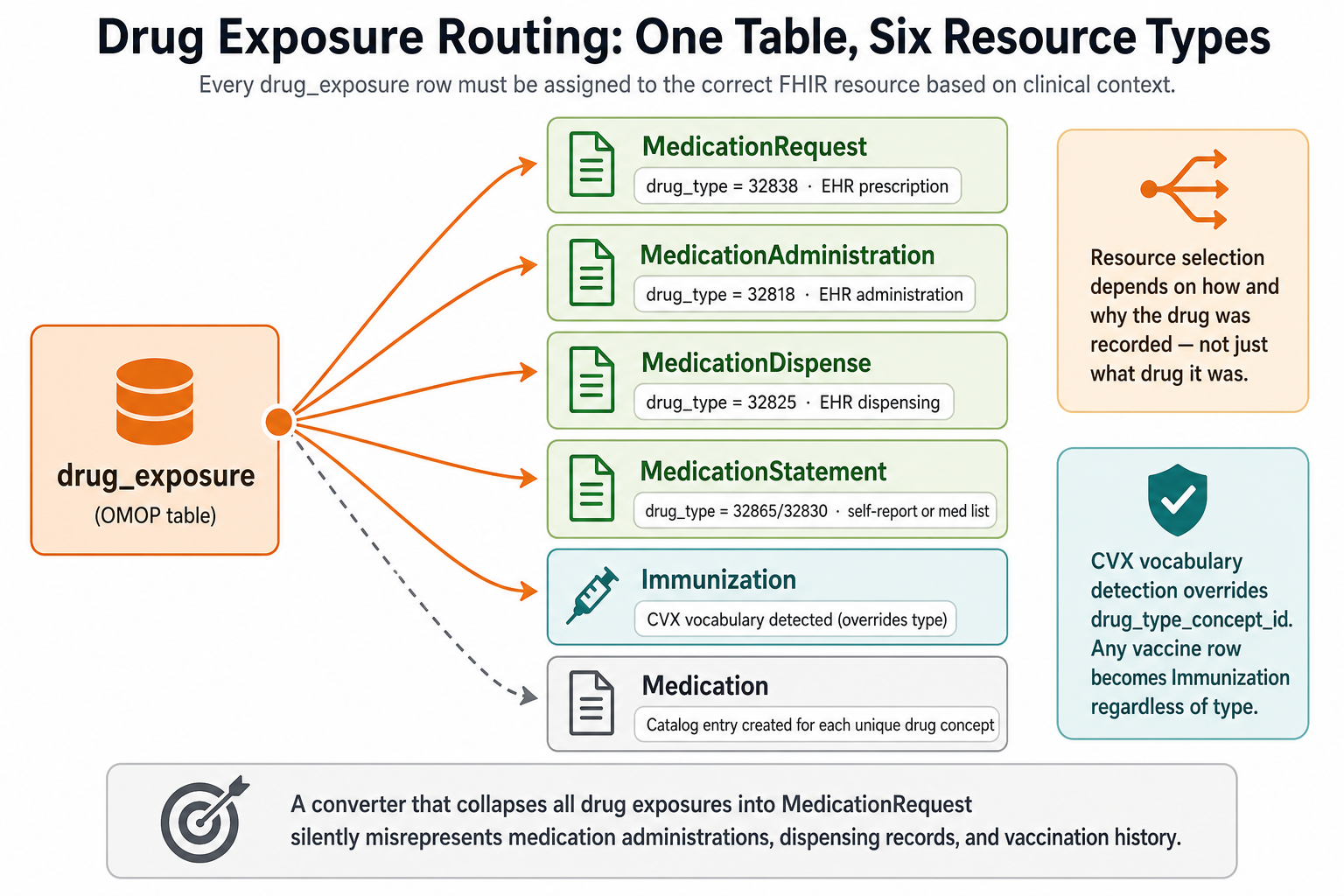
Every drug_exposure row must be assigned to the correct FHIR resource type based on clinical context. Collapsing these into one type produces an incomplete medication history.
Validated against the current US Core, not a legacy version. Community implementations that do cover broad resource types target US Core 4.0.0 — two major versions and multiple material conformance changes behind. The OMOP2FHIR converter targets US Core 6.1.0, the version commonly used in current U.S. interoperability implementations, including many payer and regulatory workflows. Tested across a cohort of 117 Synthea patients, the converter produced zero US Core 6.1.0 validation errors. That number matters because a single missing required element, repeated across dozens of resources, is how most exports fail silently.
Built-in completeness reporting. A coverage layer counts source rows per OMOP domain, counts exported FHIR resources, and surfaces the delta. The export tells you what it produced and what it could not.
Validation as a first-class step. The converter output is checked against the HL7 FHIR Validator as part of the workflow. You know whether the bundle passes before it reaches any downstream system.
If your use case requires exporting de-identified OMOP data to FHIR, Patient Journey Intelligence supports that end to end — de-identifying structured patient records at the OMOP layer before export, producing a US Core 6.1.0-compliant FHIR bundle from de-identified data.
The OMOP2FHIR converter is one component in Patient Journey Intelligence, John Snow Labs’ platform for end-to-end patient data harmonization. The platform extracts structured clinical facts from unstructured notes and reports (Healthcare NLP, Medical LLM), populates the OMOP CDM, de-identifies the records when required, and exports the structured data to compliant FHIR bundles.
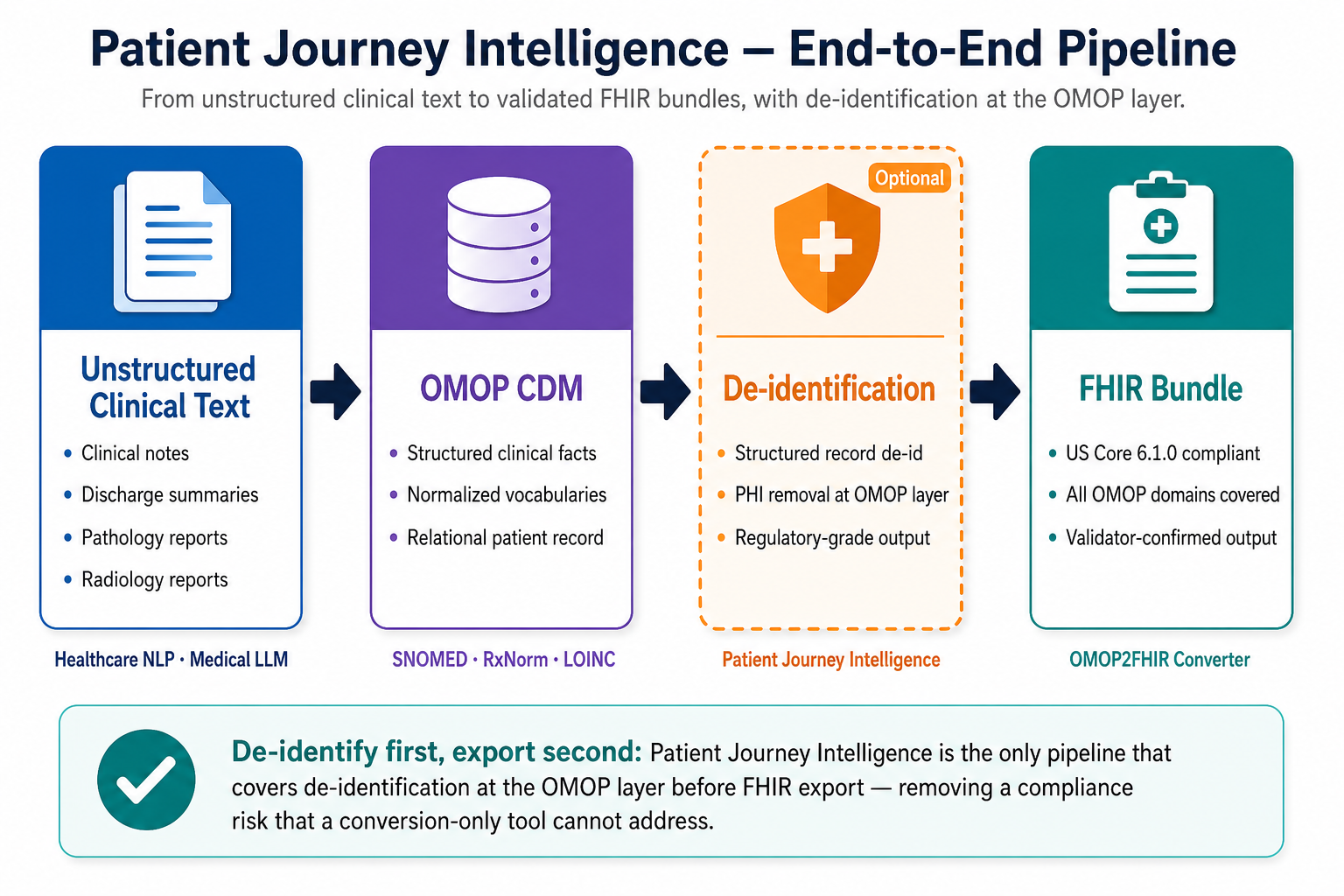
Patient Journey Intelligence covers the full path — from unstructured text to validated FHIR bundles, with de-identification available at the OMOP layer when required.
“The measure of a clinical data export is whether it passes validation on every resource, every time, without manual rework. That’s the standard we built the OMOP2FHIR converter to meet.” — David Talby, CEO, John Snow Labs
What happens when you ask an LLM to do this
The question is reasonable. Frontier LLMs produce structured JSON and can follow mapping rules in prose — workable for proof of concepts, not for regulated export at scale.
We tested Claude Opus 4.8 and GPT-5.5 on a set of patient data in OMOP CDM (US Core 6.1.0), each across two prompt iterations. The second prompts added JSON-only output, a completeness gate, and explicit US Core requirements for Encounter, Practitioner, and DocumentReference.
GPT-5.5’s first run exported 48 of 150 resources with 18 validation errors. The second run reached 150 of 150 which is correct, but errors rose to 248 — a 14× increase as coverage improved. Opus 4.8 showed the same pattern: 67 errors on a 140-resource bundle that still missed 10 Medication catalog entries.
| Error category | Count |
| Observation.category / VSCat profile slice missing | 182 |
| Immunization occurrenceDateTime invalid instant format | 17 |
| DocumentReference.category missing | 17 |
| Encounter.type / profile binding mismatch | 17 |
| Organization.active missing / profile mismatch | 10 |
| Condition.category missing | 2 |
| DocumentReference.type outside US Core value set | 1 |
Several of these could be improved with simple prompt additions — add Observation.category, set Organization.active, populate DocumentReference.category. A third prompt iteration might reduce the count. That is not the same as production conformance. Our v3 prompt already encoded US Core rules for Encounter, Practitioner, and DocumentReference. Errors still rose when we fixed completeness. It never specified the Observation.category VSCat slice that accounts for 182 failures, and it directed the model to use a LOINC code the validator rejected as outside the US Core DocumentReference value set.
Rules the prompt did include Encounter.type bindings, Immunization datetime format — still failed across every affected resource.
Continuous refinement can be time-consuming, requiring multiple rounds of prompt tuning, bundle regeneration, and validation before achieving compliance. While this approach may be adequate for a demonstration, it is difficult to scale reliably. It does not scale as a workflow: each revision is a manual regression across resource types and patient profiles; with no guarantee of the next cohort passes. And FHIR profiles keep moving — US Core 4.0.0 to 6.1.0 changed what downstream systems accept, and the next revision will change it again. A prompt tuned to today’s requirements needs to rework when the implementation guide updates; a deterministic converter encodes rules in versioned, testable code re-run against the validator on every release.
LLM generation also lacks determinism (same input, same output, every run) and can cost approximately $1.30–$1.50 per patient for relatively small patient records at current API rates. Costs increase as patient histories become more complex and contain larger volumes of clinical data. LLMs belong upstream — extracting clinical facts from unstructured text into OMOP. Exporting structured OMOP rows to FHIR is a schema mapping task for deterministic logic.
What to evaluate if you’re choosing an OMOP-to-FHIR approach
Domain coverage. Which OMOP tables does it handle? Person and Encounter are table stakes. Ask about drug_exposure routing, measurement-to-DiagnosticReport handling, clinical notes, device exposures, and specimens. These are the domains where most approaches have gaps.
Drug routing fidelity. Does it route drug_exposure rows to the correct FHIR medication resource type based on context, or does it collapse everything into MedicationRequest? Five resource types is the correct number. Anything less produces an incomplete medication history.
US Core version. US Core 4.0.0 and 6.1.0 have material differences in required elements and terminology bindings. Confirm which version the output conforms to — and whether it has been validated against that version, not just targeted.
Completeness reporting. Does the tool tell you how many source rows mapped to output resources, and whether any were dropped? Without this, you are validating by spot check.
De-identification support. If your use case involves regulated data sharing — clinical trials, payer exchange, research collaboration — can the pipeline de-identify at the OMOP layer before exporting? Handling de-identification and conversion separately introduces an integration seam and a compliance risk.
We did not identify an open-source tool or LLM-based approach that demonstrated all five criteria in our evaluation. The OMOP2FHIR converter was designed to address all five criteria and met them in our internal evaluation.
OMOP-to-FHIR export is an open problem with no official standard, limited tooling in the right direction, and significant operational and compliance implications when conversion errors are not detected. If you’re evaluating approaches, schedule a technical session to see the OMOP2FHIR converter run against your own patient data.
Frequently Asked Questions
What is OMOP CDM and how does it differ from FHIR?
OMOP CDM is a relational database schema designed for observational research — flat tables, fixed vocabularies (SNOMED CT, RxNorm, LOINC, CVX), optimized for population queries. FHIR R4 is a nested, resource-based exchange standard designed for system-to-system communication over APIs, with flexible code system bindings. They serve different purposes and have fundamentally different data structures.
What is US Core 6.1.0 and why does it matter for OMOP export?
US Core 6.1.0 is the US-specific FHIR implementation guide that defines which resources, elements, and terminology bindings are required for interoperability. It sits on top of base FHIR R4 and adds mandatory constraints. A bundle that validates against base FHIR can still fail US Core if required elements like category slices or profile annotations are missing. Most US payer and regulatory use cases require US Core conformance.
Why does drug exposure routing make OMOP-to-FHIR conversion hard?
A single OMOP table (drug_exposure) must be routed to one of five different FHIR resource types — MedicationRequest, MedicationAdministration, MedicationDispense, MedicationStatement, or Immunization — based on how the drug was recorded and whether it uses the CVX vaccine vocabulary. Tools that skip this routing either drop records or collapse all medications into one resource type, losing clinical context about how and why the drug was recorded.
Can I use GPT or Claude to convert OMOP data to FHIR?
LLMs can generate FHIR-shaped JSON from structured OMOP input, but they are not built for schema-level conformance at scale. US Core validation requires profile-specific slices, vocabulary-backed codings, and context-dependent routing applied consistently on every row — requirements that prose prompts do not enforce reliably. A prompt tuned to pass validation today may fail when US Core or FHIR profiles update, and each revision requires manual re-validation across your full clinical model. LLMs are a better fit upstream: extracting structured clinical facts from unstructured notes and reports to populate the OMOP CDM in the first place.
How do I know if my FHIR export is complete?
You need a completeness report that counts source rows per OMOP domain and compares them to the number of FHIR resources produced. Without this, you’re relying on spot checks. The OMOP2FHIR converter in Patient Journey Intelligence includes a built-in coverage layer that surfaces the row-level delta between source data and output bundle.
Can I export de-identified OMOP data to FHIR?
Patient Journey Intelligence supports de-identification at the OMOP layer — removing PHI from structured patient records before conversion to FHIR. The output is a US Core 6.1.0-compliant FHIR bundle generated from de-identified data. This end-to-end pipeline addresses regulated sharing use cases (clinical trials, payer exchange, research collaboration) where conversion alone is insufficient.
All patient data referenced in this article is synthetically generated for illustration.