
























































Did you know that one AI query uses about the same power as charging a smartphone 11 times? And that cooling the servers behind it can take about 20 milliliters of water for every query? According to research led by Oliver Kleinig, ChatGPT alone uses about 15 times more energy than a Google search. Implementing LLMs and other generative AI tools in healthcare can therefore have very real environmental consequences.
What seems like a helpful digital assistant can quietly become a major drain on budgets, power grids, and even water supplies.
The good news is that hospitals don’t need to choose between advanced AI and responsible operations. New techniques can make LLMs lighter, cheaper, and more efficient without compromising clinical trust or regulatory compliance.
This article will give healthcare IT and compliance teams a clear roadmap. It provides steps they can take now to reduce costs, meet sustainability targets, and maintain the reliability and trustworthiness of AI systems in clinical care.
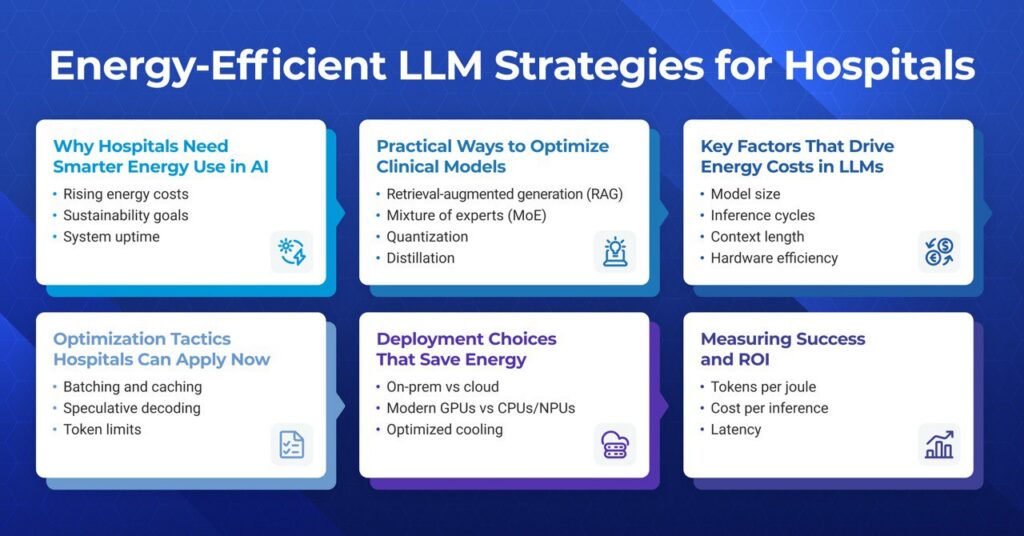
Why Hospitals Need Smarter Energy Use in AI
In 2023–24, NHS provider trusts in England reported an overall deficit of £1.2 billion, more than double the year before. As operating costs keep rising across healthcare, high-energy AI models risk adding even more pressure to already stretched budgets, making it one of the reasons to adopt energy-efficient AI in healthcare.
Some other reasons for the need for smarter energy in AI include:
- Sustainability goals: Hospitals are under pressure to meet environmental, social, and governance (ESG) targets. Running sustainable AI in healthcare helps cut emissions while showing responsibility to patients and regulators.
- System uptime: Generative AI in healthcare adds to the load on critical infrastructure, such as electrical and cooling systems and core IT networks. Smarter design reduces the risk of outages that could affect care.
- Operational trust: Energy-efficient LLMs reduce the compute and energy needed for each task. This makes it easier to scale these tools across departments or sites without straining budgets or IT systems.
Smarter, energy-efficient LLM design solves energy usage challenges in healthcare. Not only this, but energy-efficient AI also improves patient care by ensuring hospital systems’ responsiveness and availability.
Key Factors That Drive Energy Costs in LLMs
Not all large language models use energy the same way. Some design choices make them far more expensive to run. Understanding what drives LLM energy consumption helps hospitals control costs and maintain reliable systems.
Here are the main factors:
- Model size and efficiency: Bigger models use more parameters. Every extra parameter needs power to load and compute. Smaller, well-trained models can often deliver the same results with less energy.
- Inference cycles: Every time a model generates an answer (an “inference”), it spins up thousands of calculations. Frequent, high-volume inference requests quickly raise energy use. Smarter inference optimization, like batching requests or using cached results, can reduce waste.
- Context length: Longer prompts and responses mean more tokens for the model to process. More tokens mean more compute cycles, which leads to higher energy use. Trimming inputs and outputs where safe saves both time and power.
- Hardware efficiency: Old or mismatched hardware burns more power. Modern GPUs and accelerators run the same tasks with less electricity. Aligning hospital AI infrastructure with the right chips, cooling, and storage matters.
- Compute power in healthcare AI: Rising demand for AI-driven tools is changing hospital operations. A 2024 survey found that 66% of U.S. physicians now use healthcare AI. Combined demand can strain servers and power systems, raising costs and risking uptime. Load balancing and scaling help keep this under control.
For hospitals exploring the use of LLMs in healthcare, knowing these drivers is essential. It enables the planning of AI projects with clear cost, performance, and sustainability targets before new tools are ever deployed.
Practical Ways to Optimize Clinical Models
Hospitals can make AI models more energy-efficient with proven technical methods. Each approach comes with trade-offs. Some improve processing speed and reduce power use while causing small changes in accuracy. The goal is to apply these optimizations in a way that preserves clinical trust and compliance.
1. Quantization in Healthcare AI
Quantization lowers the numerical precision used in a model’s calculations. Models perform fewer computations by reducing the number of bits used to represent data. This decreases energy consumption and speeds up response times while keeping performance within safe clinical boundaries.
A study tested this approach on heart disease and breast cancer prediction datasets using KNN and SVM models. It showed that applying quantization and data bit reduction techniques reduced processing time noticeably, with only a minor decrease in accuracy. The results also highlighted that performance depends on both the dataset and the model, making testing in the hospital’s own environment essential.
2. Model Distillation
Hospitals can use model distillation to create a smaller, faster AI model by training it to mimic a larger, more accurate model. For example, Medical VLM-24B is a powerful vision-language model that can read X-rays, MRIs, pathology slides, and more. By distilling it into a task-specific version, health systems could keep most of its accuracy while lowering energy use. This also allows the model to run on existing hardware and provides clinicians with results they can trust.
One study applied this approach to medical image analysis. Researchers trained a traditional CNN as a teacher model and then distilled it into a smaller, simpler CNN. The distilled model kept most of the important features, reduced the number of network layers, and produced intuitive visual explanations through hierarchical feature analysis.
3. Low-Rank Adaptation (LoRA)
LoRA adapters are lightweight modules added to LLMs to enable them to adapt to new tasks without retraining every parameter. They significantly reduce the computational and energy cost of fine-tuning, which is critical in clinical environments where hardware resources are often limited.
A study tested four adapter techniques, Adapter, Lightweight, TinyAttention, and Gated Residual Network (GRN), on biomedical LLMs for clinical note classification under resource constraints (small dataset and limited GPU). The findings showed that GRN performed best among adapters.
4. Retrieval-Augmented Generation (RAG)
RAG is a method that combines a language model with an external database. Instead of storing all knowledge inside the model, it retrieves relevant information from a structured source at runtime. This allows models to stay smaller, use less compute, and remain up-to-date without retraining.
A study demonstrated that local RAG models, such as Llama 3.1-RAG, achieved 2.7 times more accuracy points per kilowatt-hour. Also, it consumed 172% less electricity compared to commercial LLMs, all while maintaining higher accuracy.
5. Mixture of Experts (MoE)
Mixture of Experts (MoE) models divide tasks among several smaller “expert” sub-models. Only the relevant experts are active for each input, which reduces unnecessary computation. This makes large models more energy-efficient without sacrificing overall performance.
A survey highlighted that MoE architectures significantly reduce the required computational resources and energy consumption while maintaining or even improving model performance.
Some platforms already support these approaches. Tools like the Generative AI Lab help teams build and monitor optimized models safely.
Deployment Choices That Save Energy
Once a model is optimized, how and where it runs matter just as much. The right setup for HIPAA-compliant AI infrastructure not only keeps patient data secure but also gives hospitals more control over performance, energy use, and cost.
Here are key considerations hospitals should weigh:
On-prem vs. Cloud Deployment for Healthcare AI
On-premises can offer better control over sensitive data (necessary for HIPAA compliance). They are cost-effective when used at scale, with predictable power and infrastructure costs.
Cloud platforms offer quick setup and access to energy-efficient data centers. Costs can rise if AI models run constantly. However, for hospitals experimenting with AI or needing burst capacity, this is often the most energy-sensible option.
Hardware Choices
Shifting from a CPU-only system to an energy-efficient GPU for hospitals or purpose-built AI hardware can yield notable energy savings. NVIDIA reports that this transition could save over 40 terawatt-hours each year globally. Moreover, research shows that a hybrid environment (GPU+CPU) can also help reduce energy costs.
For specialized workloads, embedded accelerators like Edge TPUs can be even more efficient. A study shows that processing a single medical image used less than 50 mJ on an Edge TPU than 190 mJ on a GPU. These gains mean hospitals can run complex AI models faster, reduce energy costs, and still meet compliance requirements.
Optimized Cooling Practices
Efficient hardware is important, but it’s not enough on its own. Hospitals that operate their own facilities should adopt green hospital data center strategies. These include liquid cooling, hot/cold aisle containment, renewable energy sources, and real-time energy tracking. These practices can help reduce operational emissions and support ESG goals.
Optimization Tactics Hospitals Can Apply Now
Hospitals can take immediate steps to make LLM inference faster and more energy-efficient. These simple optimizations reduce compute time, lower energy costs, and help maintain smooth clinical operations.
- Batching and caching: Group multiple inference requests together and reuse repeated computations to reduce redundant processing and save energy.
- Speculative decoding: Generate multiple token predictions in parallel and select the best one to speed up inference without running the model longer than needed.
- Token limits in healthcare AI: Set sensible maximum input and output lengths to avoid unnecessary computations and reduce energy use.
- Model selection: Use smaller or distilled models for routine tasks to lower compute requirements while maintaining acceptable accuracy.
- Hardware-aware scheduling: Run inference during off-peak times or distribute workloads to more efficient GPUs to optimize energy use.
- Monitor and profile LLM inference: Track which queries consume the most resources to identify LLM inference optimization opportunities.
Measuring Success and ROI
Every hospital needs to see clear results when investing in AI. Tracking the right LLM performance metrics converts technical work into measurable business and clinical value. It also sustains team focus on cost-reduction improvement that benefits both patient care and sustainability goals.
Here are key measures and how they help:
- Tokens per Joule: Measures how much work a model does per unit of energy. A higher value means better energy efficiency in hospitals, lowering electricity costs without cutting capacity.
- Cost per inference: Shows the cost of each AI-driven prediction. Watching this number drop over time confirms that new models, hardware, or optimization strategies are actually improving healthcare AI ROI.
- Latency: Tracks how quickly the model responds. Low latency supports timely diagnosis and treatment, while also avoiding wasted compute cycles.
- Carbon dioxide equivalent (CO₂e): Measures greenhouse gas emissions associated with running LLMs. Hospitals can track CO₂e per inference or per token to quantify the environmental impact of AI.
- Carbon density: Represents emissions per unit of computational work. This helps compare different models or deployment setups based on their relative environmental efficiency.
Key Takeaway for Hospital Leaders
Hospitals can reduce expenses and carbon footprints by implementing energy-efficient LLM practices. They can achieve this without compromising compliance or clinical reliability.
Key things to consider include:
- Energy-efficient AI is not a trade-off. Hospitals can reduce electricity use and hardware demands without compromising clinical outcomes.
- Sustainable AI in healthcare aligns with ESG goals. It should demonstrate responsible technology use to regulators, patients, and staff.
- Tracking clear metrics, such as cost per inference and latency, ensures ongoing improvements and measurable ROI.
- Practical deployment choices, like hybrid models and modern GPUs, can maximize efficiency while keeping sensitive patient data secure.
Your hospital AI strategy should include energy efficiency from the start. Acting now not only saves money and energy but positions you as a forward-thinking, sustainable leader in healthcare innovation.
Need help shaping a smarter, greener AI strategy for your hospital?
John Snow Labs offers state-of-the-art medical language models. Our experts can help you design and implement an AI system that will truly impact clinical practice and align with your sustainability and cost-efficiency objectives.
Schedule a demo today to learn how we can assist you.
FAQs
How can hospitals reduce the energy consumption of LLMs without losing clinical accuracy?
Hospitals can reduce the energy consumption of LLMs by using techniques like quantization and model distillation. They can also implement more efficient inference methods, such as RAG, batching, and caching.
Are quantization and model distillation safe for clinical applications?
Yes, if validated on hospital-specific datasets. They reduce energy with minimal accuracy loss while keeping models compliant and reliable.
Which is more energy-efficient for hospitals: on-premises deployment or cloud-based LLMs?
Cloud LLMs scale efficiently and benefit from energy-optimized data centers. On-premises can be efficient for heavy, continuous workloads if the hardware is modern.
How can hospitals measure the ROI of energy-efficient LLM initiatives?
Hospitals can use different metrics, such as tokens per joule and latency, to measure the ROI of their energy-efficient LLM initiatives. Metrics like carbon density and CO₂e can also help measure the energy efficiency of LLMs.
Can adopting energy-efficient AI help hospitals achieve sustainability and ESG goals?
Yes. Lower energy use and emissions support ESG reporting and demonstrate responsible, sustainable AI practices.



