We are happy to announce the release of Finance NLP 1.6
Finance NLP is a John Snow Lab’s product, launched 2022 to provide state-of-the-art, autoscalable, domain-specific NLP on top of Spark.
With more than 115 models, featuring Deep Learning and Transformer-based architectures, Finance NLP includes:
- Annotators to carry out Name Entity Recognition, Relation Extraction, Assertion Status / Understanding Entities in Context, Data Mapping to external sources, Deidentification, Question Answering, Table Question Answering, Sentiment Analysis, Summarization and much more, both training and inference!
- Zero-shot Name Entity Recognition and Relation extraction;
- 115+ pretrained Deep Learning / Transformer-based models;
- Fully integration with Databricks, AWS or Azure;
- 33+ notebooks and 25+ demos ready to showcase its features.
- Full integration with NLP Lab (former Annotation Lab) for managing your annotation projects and train your financial models in a zero-code fashion.
- Compatiblity with Visual NLP, to combine OCR/Visual capabilities, as Signature Extraction, Form Recognition or Table detection, to Finance NLP.
Document Classification in Finance NLP 1.6
- Classify between different filings and schedules, including
TO-C,13D,TO-T,14F1,14D9,14N,13G,TO-I,13E3,FORM-3FORM-4with finclf_sec_schedules_filings.
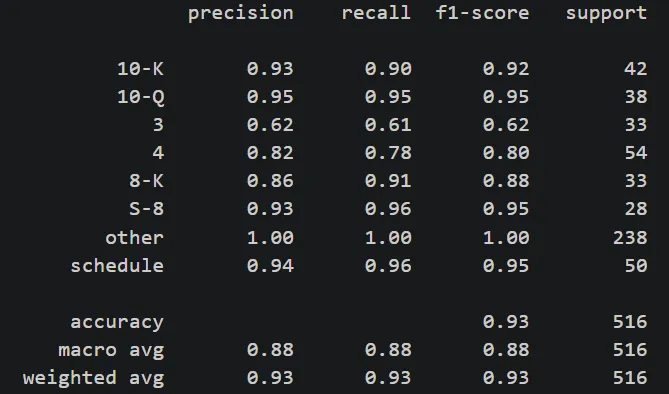
Offline and scalable Wikidata dumps
This is the first series of models, making available the usage of wikidata dumps inside Spark, in a scalable way.
We are including a dump for companies registered in English Wikipedia which are parent of other companies. With this, you can extract an ORG using NER and check if it has subsidiaries or it is a subdiary / acquisition of another parent company.
- finel_wikipedia_parentcompanies helps to normalize your NER ORG extractions to wikipedia version of the company names.
- finel_wikipedia_parentcompanies helps to get a ticker from a company using Wikipedia.
- finmapper_wikipedia_parentcompanies will retrieve, given an ORG entity, the parent company, subsidiaries, ticker, stock exchange, and other financial information.
- finmapper_wikipedia_parentcompanies_ticker will retrieve, given a TICKER entity, the parent company, subsidiaries, ticker, stock exchange, and other financial information.
Do you want to have other wikidata dumps available in Spark NLP? Let us know!
5 new Financial NER Models in Finance NLP 1.6
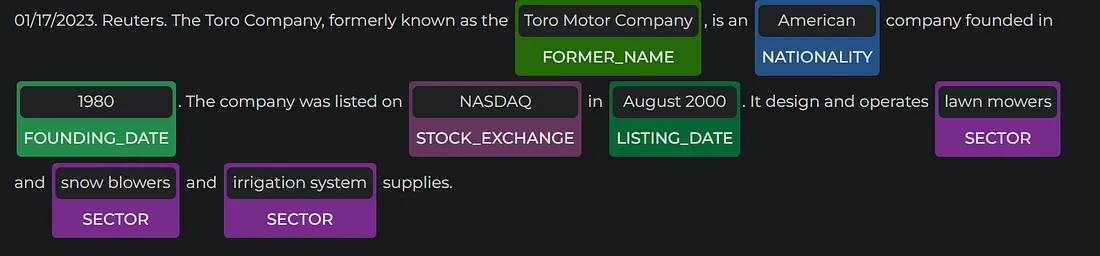
- finner_wiki_founding_dates: Helps you retrieve FOUNDING_DATE (founding or establishment date) or LISTING_DATE (date when a company was listed on a STOCK EXCHANGE) from Financial texts.
- finner_wiki_formername: Helps you retrieve FORMER_NAME (previous names of companies ) from Financial texts.
- finner_wiki_nationality: Helps you retrieve NATIONALITY, the original country a company was founded in, from Financial texts.
- finner_wiki_sector: Helps you identify in which SECTOR a company operates.
- finner_wiki_stockexchange: Helps you extract the STOCK_EXCHANGE a company is listed on.
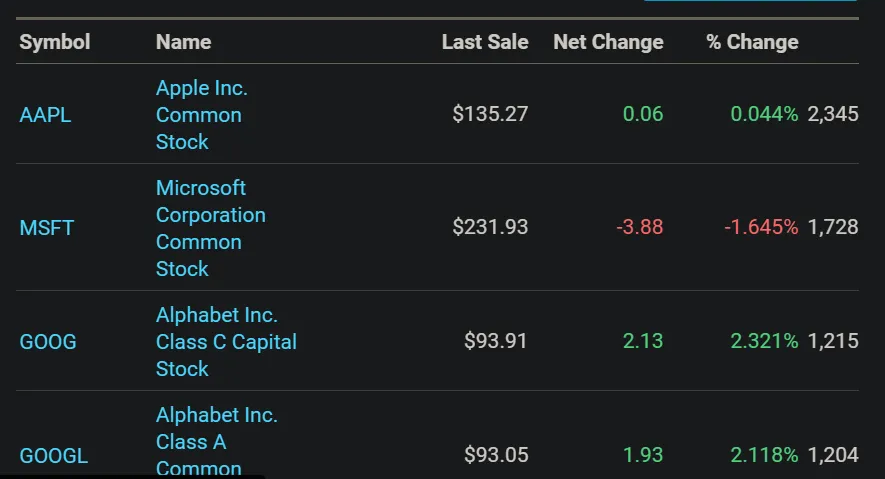
NASDAQ Screener Data Source for data augmentation
[Updated to Dec, 2022] New Entity Resolvers (company name normalization and ticker resolution) using NASDAQ data source:- finel_nasdaq_company_name_stock_screener: To obtain the name of an ORG detected in NER as it is registered in NASDAQ stock screener data source.
- finel_nasdaq_ticker_stock_screener: To obtain the ticker of an ORG detected in NER as it is registered in NASDAQ stock screener data source.
- finmapper_nasdaq_stock_screener: Retrieve information from NASDAQ by using an ORG extracted with NER. Don’t forget to use Entity Resolution to normalize your ORG to the format of company names in NASDAQ.
- finmapper_nasdaq_company_name_stock_screener_en: Retrieve information from NASDAQ by using a TICKER extracted with NER.
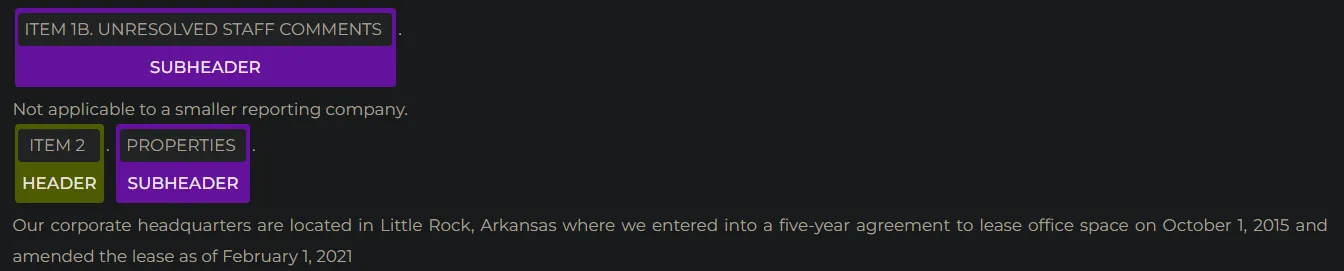
Contextual Parser (scalable rule-base NER)
- Detect HEADERs and SUBHEADERs in SEC filings, for splitting purposes. Included in
finpipe_header_subheaderall along with other DL-based models for a hybrid extraction approach.
Split filings into items / sections using pretrained pipelines
- Combine NER, Contextual Parser and ChunkSplitting models to split SEC filings into different sections automatically, using
finpipe_header_subheader
New notebooks
We have continued creating notebooks showcasing Finance NLP functionalities, with more than 33 notebooks available here. Some of the new ones include:
- Financial BertForTokenClassification training and inference, using any available Financial Bert model available in Hugging Face.
- ContextualParser for carrying out rule-based NER at scale, both training and inference.
- Binary, Multiclass and Multilabel classification of financial texts.
- Using NER to split a text with ChunkSentenceSplitting
How to run
Finance NLP is very easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
nlp.install(force_browser=True) nlp.start()
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our financial team of technical and SME. Just go to john snow labs pricing and follow the instructions!