
























































Version 1.20.0 of the library has an optimized sentence embedding model for RAG application in the Finance domain and aspect-based sentiment analysis of financial entities in context.
Sentence Embedding Model
The new model is a large version of the previously released model based on the E5 architecture. The large version is trained on a larger corpus and contains more parameters (1024 embedding size versus 768 of the base version).
The E5 models are among the best for retrieval augmented generation (RAG). To use the model on a Spark NLP pipeline, simply download the pretrained model and apply directly on DOCUMENT annotations:
Create DOCUMENT annotations from raw texts:
documenpt_assembler = (
nlp.DocumentAssembler().setInputCol("text").setOutputCol("document")
)
Download the pretrained model and define the pipeline:
E5_embedding = (
nlp.E5Embeddings.pretrained(
"finembedding_e5_large", "en", "finance/models"
)
.setInputCols(["document"])
.setOutputCol("E5")
)
pipeline = nlp.Pipeline(stages=[document_assembler, E5_embedding])
Then, we can transform texts into vector representations with:
data = spark.createDataFrame(
[["What is the best way to invest in the stock market?"]]
).toDF("text")
result = pipeline.fit(data).transform(data)
We can then obtain the vector arrays with:
result.select("E5.embeddings").show(truncate=100)
Obtaining:
+----------------------------------------------------------------------------------------------------+ | embeddings| +----------------------------------------------------------------------------------------------------+ |[0.8358813, -1.30341, -0.576791, 0.25893408, 0.26888973, 0.028243342, 0.47971666, 0.47653574, 0.4...| +----------------------------------------------------------------------------------------------------+
Aspect-based Sentiment Analysis
We are improving the aspect-based sentiment analysis models (NER + Assertion) as we increase the in-house annotation of data. This is a medium model trained in earning call transcripts and aimed to identify relevant information (entities) and their financial aspects (financially positive, financially negative, or neutral).
To use the models, we create a Spark NLP pipeline with all the required stages:
documentAssembler = (
nlp.DocumentAssembler().setInputCol("text").setOutputCol("document")
)
# Split the document in sentences
sentenceDetector = (
nlp.SentenceDetector()
.setInputCols(["document"])
.setOutputCol("sentence")
)
# Tokenizer splits words in a relevant format for NLP
tokenizer = (
nlp.Tokenizer().setInputCols(["sentence"]).setOutputCol("token")
)
# Word Embedding model finetuned on SEC fillings
bert_embeddings = (
nlp.BertEmbeddings.pretrained("bert_embeddings_sec_bert_base", "en")
.setInputCols("document", "token")
.setOutputCol("embeddings")
.setMaxSentenceLength(512)
)
# The new NER model
finance_ner = (
finance.NerModel.pretrained(
"finner_aspect_based_sentiment_md", "en", "finance/models"
)
.setInputCols(["sentence", "token", "embeddings"])
.setOutputCol("ner")
)
# Convert NER annotations to CHUNK
ner_converter = (
finance.NerConverterInternal()
.setInputCols(["sentence", "token", "ner"])
.setOutputCol("ner_chunk")
)
# The new Assertion model
assertion_model = (
finance.AssertionDLModel.pretrained(
"finassertion_aspect_based_sentiment_md", "en", "finance/models"
)
.setInputCols(["sentence", "ner_chunk", "embeddings"])
.setOutputCol("assertion")
)
# Build the pipeline
nlpPipeline = nlp.Pipeline(
stages=[
documentAssembler,
sentenceDetector,
tokenizer,
bert_embeddings,
finance_ner,
ner_converter,
assertion_model,
]
)
# Fit on empty data to obtain the PipelineModel for predictions
empty_data = spark.createDataFrame([[""]]).toDF("text")
model = nlpPipeline.fit(empty_data)
The relevant annotators are the NER model (NerModel + NerConverterInternal) and the Assertion model (AssertionDLModel) that download the pretrained models from NLP Models Hub.
We can use the model on a given text, for example:
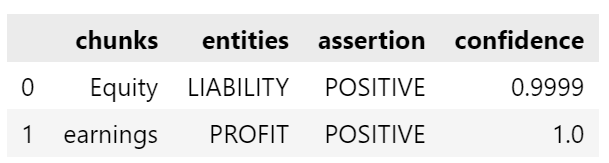
“Equity and earnings of affiliates in Latin America increased to $4.8 million in the quarter from $2.2 million in the prior year as the commodity markets in Latin America remain strong through the end of the quarter.”
We can identify the entities and their sentiment:
Fancy trying?
We’ve got 30-day free licenses for you with technical support from our financial team of technical and SMEs. This trial includes complete access to more than 150 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc., and 50+ financial language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
Don’t forget to check our notebooks and demos.
How to run
Finance NLP is quite easy to run on both clusters and driver-only environments using johnsnowlabs library:
Install the johnsnowlabs library:
pip install johnsnowlabs
Then, on Python, install Finance NLP with
from johnsnowlabs import nlp nlp.install(force_browser=True)
Then, we can import the Finance NLP module and start working with Spark.
from johnsnowlabs import nlp, finance # Start Spark Session spark = nlp.start()
For alternative installation methods of how to install in specific environments, please check the docs.




