






















































The latest version of Finance NLP adds an example notebook showing how to perform semantic search on vector stores.
Financial Semantic Search
The new notebook shows how to add Earning Calls transcripts into a vector store using sentence embeddings on the documents’ paragraphs, allowing for finding specific information and avoiding truncation of the long documents that occur because of the context length limit of the models.
The notebook is separated in a few steps:
- Load a sample Earning Calls dataset
- Split each document into paragraphs
- Apply the embedding transformation on each paragraph
- Add the information to the vector store
- Make queries
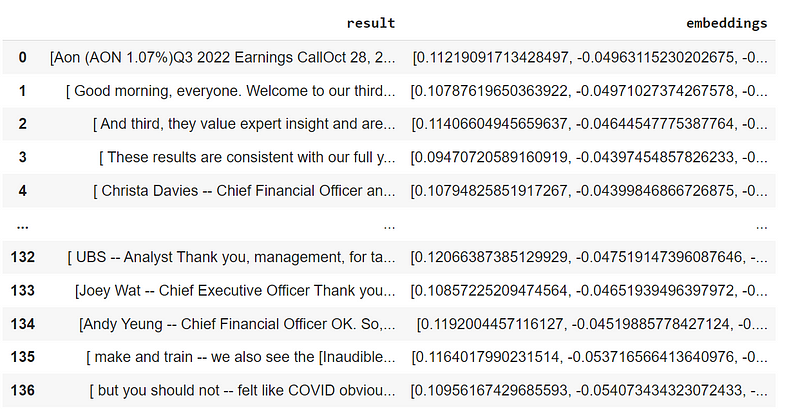
Example of paragraphs’ embeddings
To use the semantic search capability of the vector store, we showed how to process the query using the same embedding model and then perform the search using the Weaviate vector database.
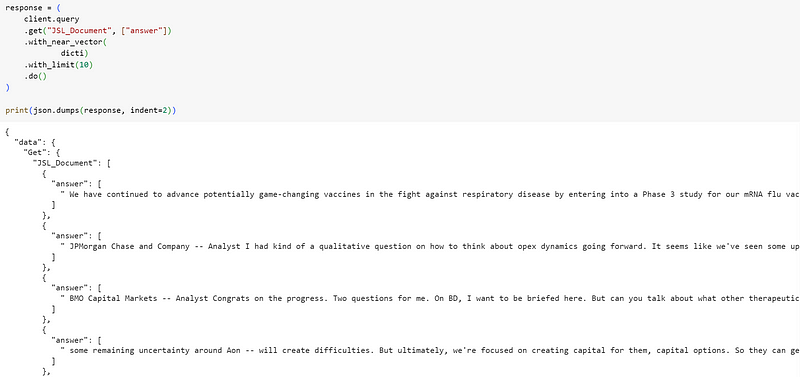
Semantic search on the vector store
With the specialized pretrained embedding models from Finance NLP and the capabilities of vector stores, it is easy to create and maintain a semantic search engine of financial texts. For details, check the notebook at the Workshop Repository.
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our financial team of technical and SME. This trial includes complete access to more than 150 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc. and 50+ financial language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
Don’t forget to check our notebooks and demos.
How to run
Finance NLP is quite easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
from johnsnowlabs import nlp nlp.install(force_browser=True)
Then we can import the Finance NLP module and start working with Spark.
from johnsnowlabs import finance # Start Spark Session spark = nlp.start()
For alternative installation methods of how to install in specific environments, please check the docs.




