Zero-shot Learning (ZSL) is one of the most recent advancements in Machine Learning aimed to train Deep Neural Network models to have higher generalisability on unseen data. One of the most prominent methods of training such models is to use text prompts that explain the task to be solved, along with all possible outputs.
The primary aim of using ZSL over supervised learning is to address the following limitations of training traditional supervised learning models:
Training supervised NLP models require substantial amount of training data.
Even with recent trend of fine-tuning large language models, the supervised approach of training or fine-tuning a model is basically to learn a very specific data distribution, which results in low performance when applied to diverse and unseen data.
The classical annotate-train-test cycle is highly demanding in terms of temporal and human resources.
In this article, we will show how to improve your training times by using Spark NLP Zero-shot Learning, and how even generate the required prompts automatically, reducing even more the required starting efforts.
Prompt Engineering
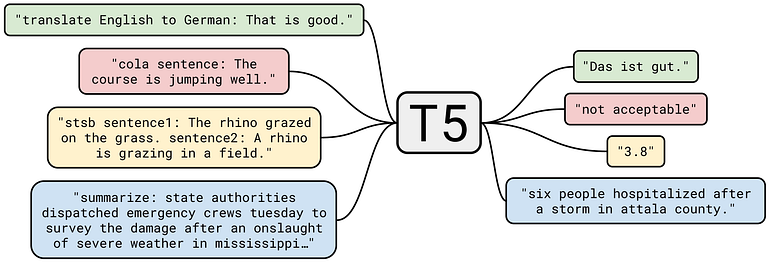
One of the most popular methods of training ZSL models is using prompts or textual string inputs which accumulate all the semantic information to help your model to identify or guide what to infer. There are many ways to model prompts, including prefixes about which task to accomplish (as in the example below, adding the description of the task you want to accomplish in T5 seq2seq model at the beginning of a sentence, followed by colon):
T5 prompt prefixes to carry out different seq2seq tasks
Other version of prompt engineering consist of providing with similar examples of what you want to retrieve. This is the approach we are going to follow in this article for Zero-shot NER and Zero-shot Relation Extraction.
Let’s see how we can use prompts to apply Zero-shot NER and Zero-shot Relation Extraction in Spark NLP.
Zero-shot Learning: NER
Named Entity Recognition is the NLP task aimed to tag chunks of information with specific labels.
NER has been historically carried out using rule-based approaches, machine learning and more recently, Deep Learning models, including transformers.
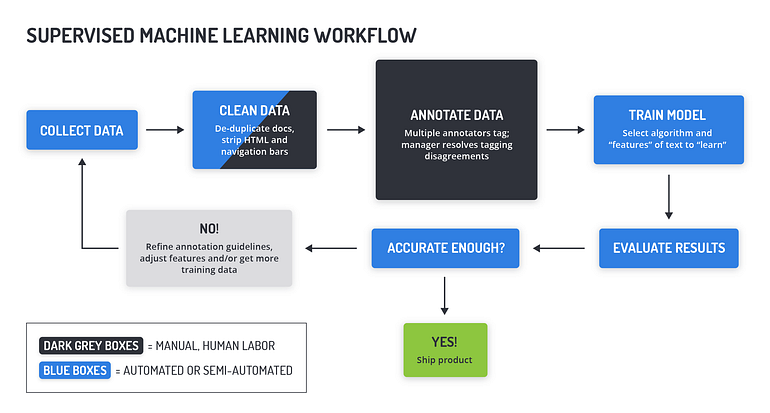
If we ignore the traditional rule-based approach, which consisted on having Subject Matter experts (SME) creating rules using regular expressions, vocabularies, ontologies, etc., the common steps for the rest of Machine Learning based NER approaches were:
Supervised Machine Learning Workflow proposed by Rossete Text Analytics
Collect and clean data;
Having SME annotating many documents;
Create features (only if using ML approaches, since Deep Learning does that feature extraction for you in most cases);
Train a model on a training dataset;
Evaluate on a test test;
If it is not accurate, go to step number 1.
This process takes a long time, specially if the nature of the use case is complex and requires many examples for the model to learn.
Thankfully, Zero-shot comes to help, since it does not require any training data, drastically speeding up the process. Zero-shot models can be:
It can be a model on it’s own, with average accuracy;
It can be used to preannotate the documents and speed up the process of annotations by SME;
Financial NLP includes Zero-shot NER, which uses prompts in form of questions, and retrieves the answers to those questions as tagged chunks of information.
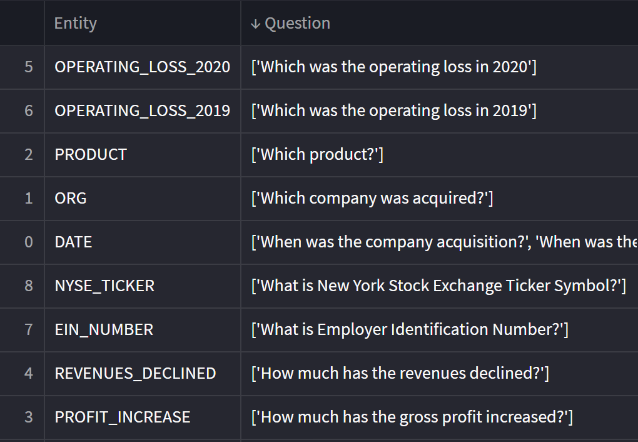
This is an example of Entity labels and some prompts.
Zero-shot prompts to carry out Named Entity Recognition
And this is the result of applying them with our Zero-shot Financial NER model.
Example of some entities extracted with the previous prompts
If you want to experiment with this model, visit the following demo webpage.
Zero-shot Relation Extraction
Similarly to Zero-shot NER, NLP Finance includes Zero-shot Relation Extraction. Relation Extraction models are those which identify if there is a relation between two entities, and what is the relation type. Let’s say, between an Operating Loss and the year when it happened, or the Company associated to (Operating Loss, Year and Company being NER tags).
Relation Extraction has it’s own annotation-training-evaluation-feedback cycle, as any other Machine Learning algorithm. The only difference is that we don’t annotate entities, we annotate relations between chunks of information / NER spans: {NER1} — relation_name — {NER2}.
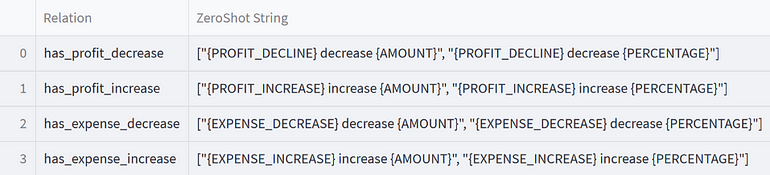
Financial NLP Zero-shot Relation Extraction speeds up the process of annotation and retrieves average-good models with just some prompts. In this case, the prompts are just textual patterns which mention two entities. Here are some examples:
Some Relation Extraction prompts
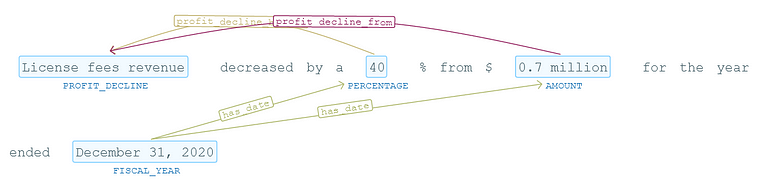
The pieces of text in brackets are the entity labels, and between them, we have for example, verbs. Those verbs will help the Zero-shot Relation Extraction understand that, if two entities are mentioned in the text when using those verbs, the relation should trigger. Let’s see an example:
Relations extracted using the previous prompts
As you can see, even there is not an exact match (the language model does only care about semantics — meanings), the Zero-shot Relation Extraction model is able to identify that, those entities in blue (NER tags — PROFIT_DECLINE, PERCENTAGE, AMOUNT, FISCAL_YEAR) are indeed connected by those relations we provide prompts for.
If you want to experiment with this model, visit the following demo webpage.
Going the extra mile: Automatic Prompt Generation
We have discussed so far the advantages of this new paradigm, Zero-shot Learning, which are clearly a step ahead towards reducing the cost of training NLP models. However, we still rely on generating those prompts to help our models carry out the inference.
In this article we propose a novel approach to automagically generate prompts, you can use for querying zero-shot NER and Relation Extraction (RE) models.
We can use either NER or a greedy-approach consisting in symbolic rules, to extract the information we need to create the prompt.
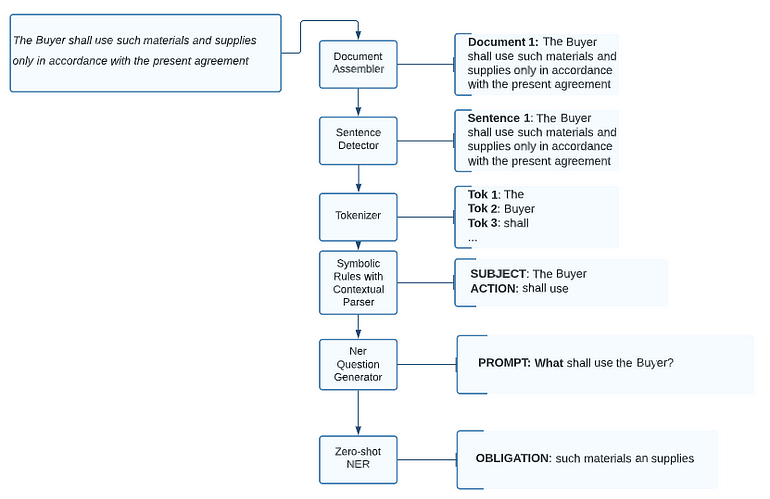
Let’s suppose we have an agreement and we need to extract the entity called “OBLIGATION” in the example below:
A proper prompt for Zero-shot NER would be:
What shall the Buyer use? (or easier to assemble, although not gramatically correct, What shall use the Buyer?
To do that, we need to extract the subject (“Buyer” — who) and and the action (“Shall use” — verb) . Our NER Question Generator module will assemble the question for you — What shall usethe Buyer?
There are two possible approaches we can follow to do that:
A rule-based approach. Consists in creating questions based on a pattern, for example: [WH-PRONOUN] [ACTION] [SUBJECT] [QUESTION MARK]. If we chose what as a wh-pronoun, we get What will obtain, record and provide the Company ? This may not sound like a natural English question, but the semantic is perfectly contained in the question nevertheless.
A seq2seq question-generation module. Given the Subject and the Action, you can use finetuned models for question generation, as the one available in the Spark NLP repository. Just by providing the concatenation of SUBJECT + ACTION (Company will obtain, record and provide) you will get (What will the Company obtain, record and provide?). The advantage of this approach is that you leave the work to seq2seq models, which are trained on real data, and language sounds more natural. The disadvantage — you have less control on the generated output.
Whatever approach you use, the idea behind is that, if you have pieces of information, you can combine them to generate a prompt.
This is an example pipeline about how to use Zero-shot NER with Automatic Prompt Generation.
Pipeline with Zero-shot NER and Automatic Prompt Generation
Spark NLP
John Snow Labs’ Spark NLP is the only natively scalable free & open-source NLP library, since it runs on the top of Spark Clusters. It’s core is Open Source, and it contains several domain-specific libraries to process Clinical, Bio, Healthcare, Finance and Legal domains.
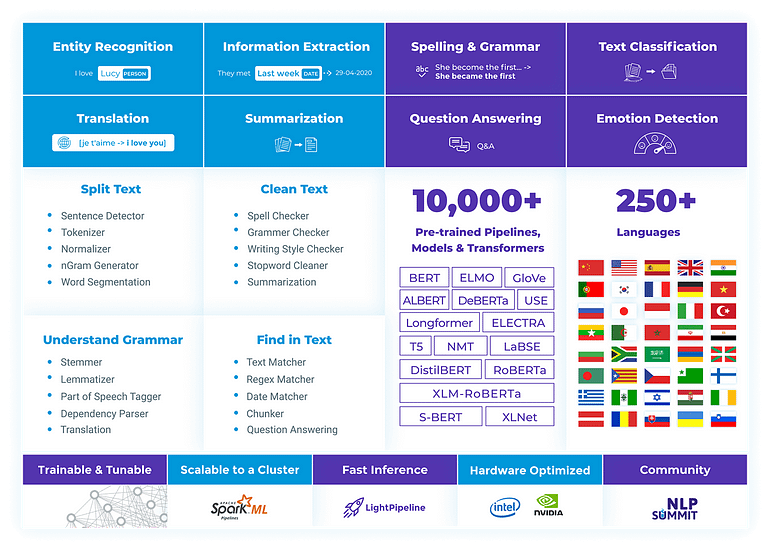
These are some of their capabilities, empowered by the use of State of the Art Transformers and Language models:
Information Extraction, including Name entity recognition and Pattern Matching;
Part-of-Speech, Dependency Parsing;
Binary, Multiclass and Multilabel Text Classification;
Question & Answering;
Machine Translation;
Sentiment Analysis;
… and even Image Classification with Visual Transformers!
Spark NLP 4.2.0 capabilities
We have more than 10K pretrained models, available in our Spark NLP models Hub, you can use out of the box. Demos are available as well showing more than 100 models in action.
Financial NLP
Financial NLP has been released, all along with Legal NLP, Oct 3rd, 2022. This is an addition to the Spark NLP ecosystem, including the Open Source core Spark NLP, Visual NLP and Healthcare NLP.
These licensed libraries work on the top of Spark NLP, which mean they are also scalable to clusters and include State-of-the-Art Transformer Architectures and models to achieve the best performance on Legal documents.
Spark NLP for Finance overview
Spark NLP for Finance, as well as Spark NLP for Legal and Healthcare, is based on 4 main pillars:
Domain-specific Entity Recognition;
Entity-linking, to normalize NER entities and link them to public databases / datasources, as Edgar, Crunchbase and Nasdaq. By doing that, you can augment Company Names, for example, with externally available data about them.
Assertion Status: to infer temporality (present, past, future), probability (possible) or other conditions in the context of the extracted entities
Relation Extraction: to infer relations between the extracted entities. For example, the relations of the parties in an agreement.
In addition to that, we include table understanding, sentiment analysis, deidentification, and the components we have highlighted in this article: Zero-shot Learning and Automatic Prompt Generation.
Juan Martinez is a Sr. Data Scientist, working at John Snow Labs since 2021. He graduated from Computer Engineering in 2006, and from that time on, his main focus of activity has been the application of Artificial Intelligence to texts and unstructured data. To better understand the intersection between Language and AI, he complemented his technical background with a Linguistics degree from Moscow Pushkin State Language Institute in 2012 and later on on University of Alcala (2014).
He is part of the Healthcare Data Science team at John Snow Labs. His main activities are training and evaluation of Deep Learning, Semantic and Symbolic models within the Healthcare domain, benchmarking, research and team coordination tasks. His other areas of interest are Machine Learning operations and Infrastructure.