






















































How to automatically identify different languages using out of the box pretrained models with Spark NLP in Python.

Language detection is the process of automatically identifying the language of a given piece of text. It is an important task in Natural Language Processing (NLP), especially for multilingual applications where the language of a given text is not always known in advance. Using Spark NLP, it is possible to identify the language with high accuracy.
A language detector in NLP is a tool or model that is designed to automatically identify the language of a given piece of text. This is an important task in NLP, especially for multilingual applications, where the language of a given text is not always known in advance. A language detector works by analyzing various features of the text, such as character set, word frequency, and n-grams, among others.
Typically, a language detector model is trained on a large corpus of text data (Spark NLP language detector models are trained on Wikipedia and Tatoeba datasets) in multiple languages, and it uses statistical methods to learn patterns that are specific to each language. Once trained, the language detector can be used to predict the language of a new piece of text by comparing its features to those learned during training.
Language detectors are commonly used in many NLP applications, such as machine translation, sentiment analysis, and information retrieval. They are also useful for tasks such as filtering spam messages and identifying the language of user-generated content on social media platforms. The accuracy of a language detector model is important for the success of NLP applications, and Spark NLP provides an open-source language detector (LanguageDetectorDL) annotator, which can achieve high levels of accuracy by deep learning models on a variety of languages.
LanguageDetectorDL is an annotator in Spark NLP that detects the language in a text, requiring only a few lines of code to set up and use. This annotator uses pre-trained deep learning models that are designed to automatically detect the language of a given text.
LanguageDetectorDL can also accurately detect language from documents with mixed languages by coalescing sentences and select the best candidate.
Overall, LanguageDetectorDL is a powerful and accurate language detection tool in Spark NLP, and is a valuable asset for any NLP application that involves multilingual text data.
In this post, you will learn how to use Spark NLP to perform language detection using pretrained models.
Please check language detector models at the John Snow Labs Models Hub.
Let us start with a short Spark NLP introduction and then discuss the details of language detection with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
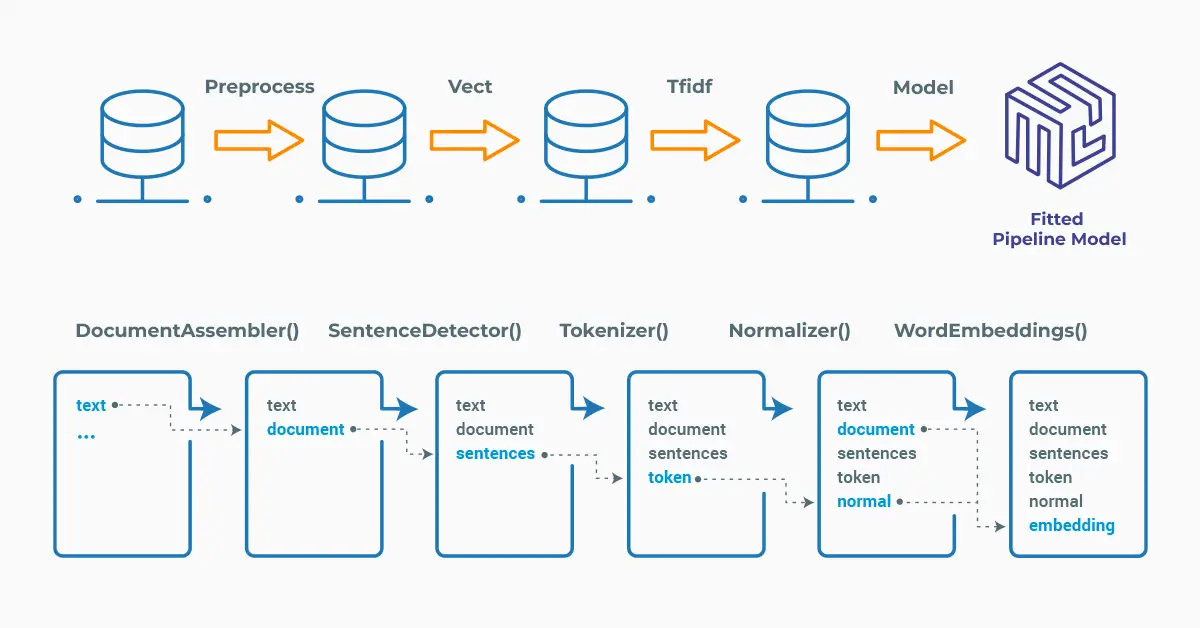 Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
LanguageDetectorDL
LanguageDetectorDL annotator is easy to use in Spark NLP, requiring only a few lines of code to set up and use. It can be used in conjunction with other Spark NLP components to build more complex NLP pipelines.
LanguageDetectorDL annotator expects DOCUMENT as input, and then will provide LANGUAGE as output.
Please check the details of the pipeline below, where we define a short pipeline and then designate the languages of the five sample texts:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
LanguageDetectorDL
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Determines the language of the text
languageDetector = (
LanguageDetectorDL.pretrained()
.setInputCols("document")
.setOutputCol("language")
)
nlpPipeline = Pipeline(stages=[document_assembler, languageDetector])
# Create a dataframe from the sample texts in different languages
data = spark.createDataFrame([
["Spark NLP is an open-source text processing library for advanced natural language processing for the Python, Java and Scala programming languages."],
["Spark NLP est une bibliothèque de traitement de texte open source pour le traitement avancé du langage naturel pour les langages de programmation Python, Java et Scala."],
["Spark NLP ist eine Open-Source-Textverarbeitungsbibliothek für fortgeschrittene natürliche Sprachverarbeitung für die Programmiersprachen Python, Java und Scala."],
["Spark NLP es una biblioteca de procesamiento de texto de código abierto para el procesamiento avanzado de lenguaje natural para los lenguajes de programación Python, Java y Scala."],
["Spark NLP é uma biblioteca de processamento de texto de código aberto para processamento avançado de linguagem natural para as linguagens de programação Python, Java e Scala"]
]).toDF("text")
After that, we get predictions by transforming the model:
result = nlpPipeline.fit(data).transform(data)
result.select("text", "language.result").show(truncate=100)

The original text and correctly estimated language are shown in the dataframe.
All the text languages were predicted correctly.
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run Language Detection with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
sample_text= "Spark NLP to biblioteka edytorów tekstu typu open source do
zaawansowanego przetwarzania języka naturalnego w językach programowania
Python, Java i Scala."
# Returns a pandas Data Frame, we select the desired columns
nlp.load('xx.classify.wiki_95').predict(sample_text, output_level='sentence')

After using the one-liner model, the result shows that the detected language is Polish
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.




