
























































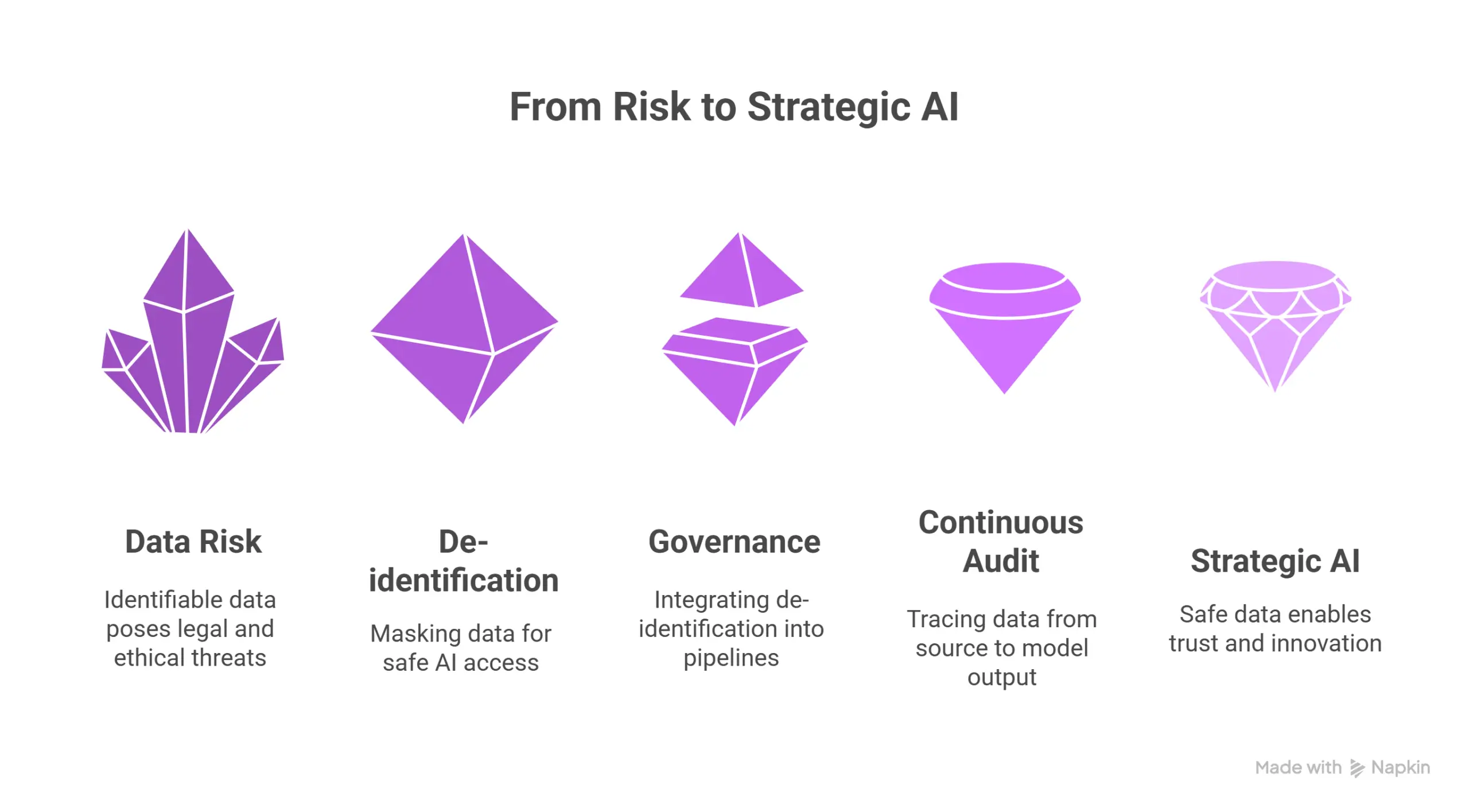
Why data de-identification is not optional in healthcare AI
In healthcare AI, the cornerstone isn’t just smart models. It’s trusted data. Without rigorous de-identification and governance, any AI initiative risks regulatory violation, data breach, or re-identification exposure. Put plainly: if your data is not de-identified (or properly pseudonymised and governed), you don’t have an AI strategy, you have a liability.
What are the core risks of insufficient data de-identification
- Regulatory non-compliance: Laws like HIPAA, GDPR, and emerging jurisdictions enforce strict rules on processing identifiable health data; penalties, delays, and audits follow mis-steps.
- Re-identification threat: Modern linking techniques (image + metadata + clinical text) make naive de-identification insufficient; weak masking may allow re-linking to individuals.
- Data breach and reputational damage: Health data is highly sensitive; a breach not only harms patients but destabilizes institutional trust and can damage AI adoption.
- Operational paralysis: If data pipelines are blocked by compliance fears or manual review burdens, AI workflows fail before even launching.
How to engineer a robust de-identification strategy
- Define the de-identification scope and target use-cases
- Classify data types: structured EHR, free-text clinical notes, imaging metadata, genomics.
- Determine whether full anonymisation, pseudonymisation or controllable synthetic data is required based on downstream use-cases (research, model training, production inference).
- Map data sources and flows.
- Build an auditable, automated de-identification pipeline
- Use tools that support entity recognition (names, dates, identifiers), context-aware masking, metadata sanitization, and consistent tokenization across visits.
- Ensure imaging metadata (DICOM headers), clinical notes (PHI in free text) and cross-linkage between modalities are addressed.
- Generate audit trails: what was masked, how, when, by whom; maintain logs for compliance and model governance.
- Apply model-ready transformations while preserving data utility
- Balance between de-identification and utility: retain clinical semantics, temporal relationships and cohort fidelity while removing re-identification risk.
- Use pseudonymization when linkage across encounters is required for longitudinal modeling, but apply governance around re-linking keys.
- Leverage synthetic data augmentation or differential-privacy techniques in selected cases.
- Integrate governance, monitoring and human oversight
- Define roles: data stewards, compliance officers, AI governance boards.
- Monitor de-identification performance: measure residual risk, external validation, re-identification testing.
- Embed human-in-the-loop checks, especially for free-text and edge-cases (e.g., rare diseases, small cohorts).
- Prepare for downstream AI pipelines and auditability
- Ensure traceability from raw data through processing to model input and output; document versioning and transformations.
- Connect de-identification logs to model governance systems, so any model output can trace back to input cohort and masking logic.
- Develop incident response and breach protocols: if re-identification occurs or data leak happens, remediation and notification must be defined.
How John Snow Labs supports data de-identification in healthcare
John Snow Labs offers advanced tools and frameworks tailored for healthcare de-identification and governed AI:
- Comprehensive clinical-text de-identification models which identify PHI entities (names, dates, providers, locations) and provide mask
- ing/pseudonymization pipelines.
- Additional anonymization methods beyond masking, as consistent obfuscation methods that reduce the probability of false negatives spotting by an attacker while preventing information loss in real world evidence (RWE) applications.
- Image metadata sanitization and DICOM header cleaning capabilities integrated into data ingestion pipelines, ensuring imaging datasets are PHI-safe before model training.
- Audit-ready processing logs, pipeline orchestration, human-in-the-loop correction workflows and integration with enterprise data platforms (Healthcare NLP) so that masking and traceability are baked into production pipelines.
- Governance frameworks and best-practice playbooks aligning with HIPAA, GDPR and AI regulatory regimes, enabling organizations to deploy AI with confidence rather than fear.
What happens if you skip the de-identification layer?
- AI projects stuck in “data sandbox” stage because production pipelines can’t access identifiable data safely.
- Regulatory audits uncover insufficient masking and models are disqualified from marketplace or forced offline.
- During model training and evaluation you have access to less data leading to biased or non-generalizable results, undermining trust.
- Data breach or re-identification event triggers not only penalties but erodes clinician, patient and stakeholder confidence, undermining all downstream AI investment.
Conclusion: De-identification is the foundation of your AI strategy
No matter how advanced your models or clever your use-cases, without robust de-identification and governance, you lack a viable AI strategy. The organizations that succeed will treat de-identification as core infrastructure, integrate it into data pipelines, audit continuously and trace from source to model output.
With John Snow Labs’ de-identification frameworks, masking pipelines and governance ecosystem, you can shift from risk-avoidance to strategic-enablement of AI. In healthcare, the first step in the AI journey is safe data. Because without it, everything else is built on sand.
FAQs
Q: Can synthetic data replace de-identification?
A: Synthetic datasets can supplement but not fully replace robust de-identified real-world data, especially for clinical modelling. De-identification and synthetic augmentation often go hand-in-hand.
Q: How do you measure re-identification risk?
A: Techniques include k-anonymity, l-diversity, membership-inference testing, external linkage attack simulations, and governance audits of pipeline logs and divergence metrics.




