
























































Introduction
In the evolving landscape of artificial intelligence for healthcare, John Snow Labs continues to demonstrate exceptional leadership with the release of the very first Medical Vision-Language Model (VLM). This model, tailored to medical specialties, represents significant advancements in medical AI, offering unprecedented capabilities in English language while maintaining the highest standards of accuracy and reliability in medical contexts.
This article explores the distinctive features, performance benchmarks, and potential applications of this specialized medical AI model, demonstrating how JSL continues to push the boundaries of what’s possible in healthcare AI.
Medical VLM-24B: Comprehensive Medical Intelligence with Multimodal Capabilities
Overview
The Medical VLM-24B model represents a significant leap forward in English-language medical AI. Fine-tuned specifically for healthcare applications, this model demonstrates exceptional performance across various medical specialties, including clinical knowledge, anatomy, medical genetics, and professional medicine.
What truly sets this model apart is its multimodal capability – Medical VLM-24B can analyze medical images alongside text, providing integrated insights. This capability enables the model to:
- Interpret radiological images such as X-rays, MRIs, and CT scans
- Analyze pathology slides for abnormalities
- Identify dermatological conditions from images
- Process medical charts, graphs, and visual data
- Understand medical diagrams and anatomical illustrations
Performance Across OpenMed Benchmarks
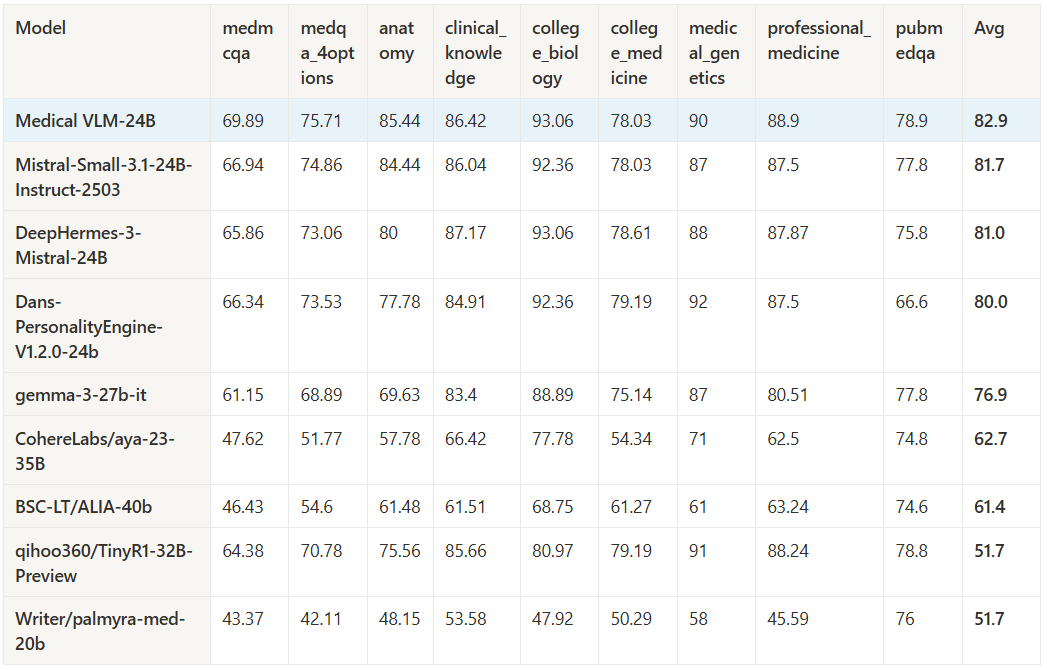
Medical VLM-24B demonstrates exceptional performance across OpenMed benchmarks, outperforming many existing models in the field. As shown in the comprehensive performance analysis, the model achieves an impressive overall average of 82.9% across multiple medical specialties.
The model excels particularly in:
- College Biology (93.06%) and Clinical Knowledge (86.42%) – demonstrating its practical value for healthcare professionals
- Medical Genetics (90%) and Professional Medicine (88.9%) – highlighting its utility for both educational and research applications
- Anatomy (85.44%) – showcasing strong understanding of medical fundamentals
Notably, Medical VLM-24B outperforms established models like Mistral-Small-3.1-24B-Instruct (81.7% average) and DeepHermes-3-Mistral-24B (81.0% average), establishing itself as a leader in medical AI performance.
General Intelligence Benchmarks
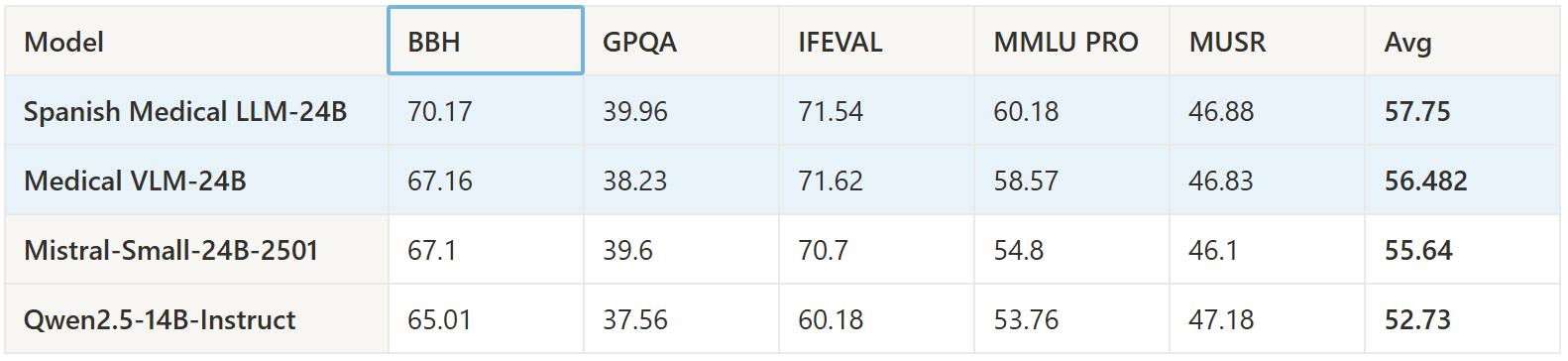
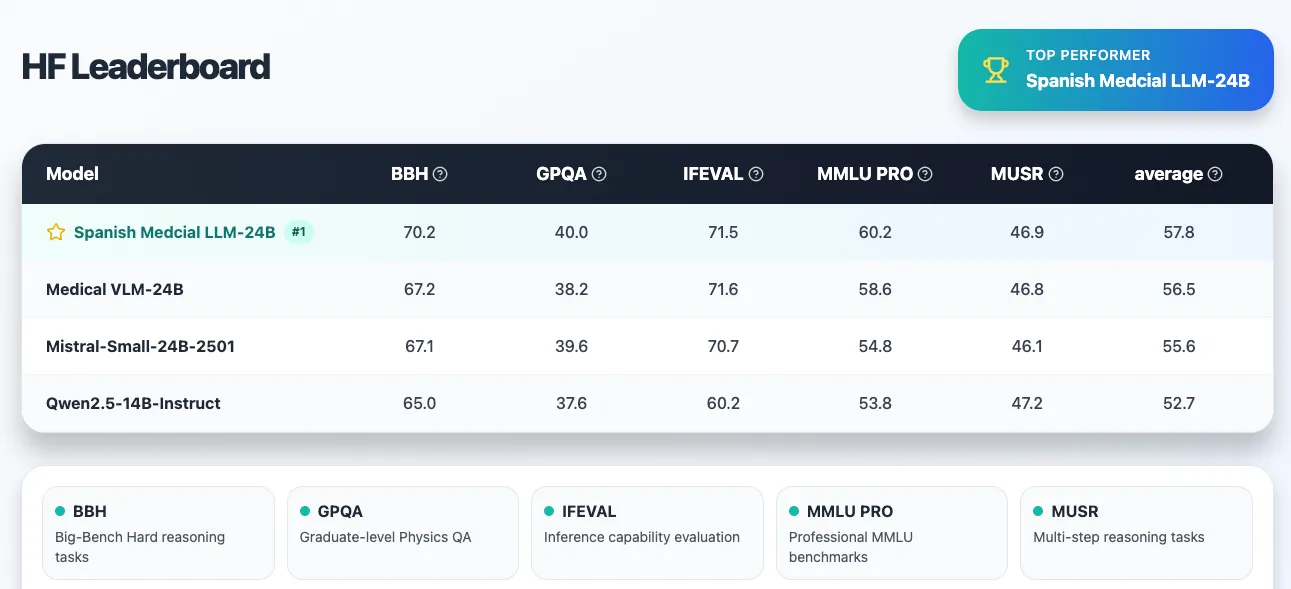
Beyond its specialized medical capabilities, Medical VLM-24B demonstrates strong performance on general intelligence benchmarks through the Hugging Face Leaderboard. The model achieves competitive results across:
- BBH (Big-Bench Hard reasoning tasks): 67.2%
- IFEVAL (Inference capability evaluation): 71.6%
- MMLU PRO (Professional benchmarks): 58.6%
These results indicate robust reasoning abilities that extend beyond simply memorizing medical facts, making it a versatile tool for complex medical reasoning and analysis.
Multimodal Capabilities in Action
The integration of image processing capabilities makes Medical VLM-24B uniquely valuable for medical professionals who need to analyze both visual and textual information simultaneously. For example, when presented with medical imaging questions, the model can:
Question/Input:
💡 What does panel d illustrate? A: The infarct core. B: The penumbra zone. C: The arterial spin labeling lesion. D: The ASL perfusion restriction.
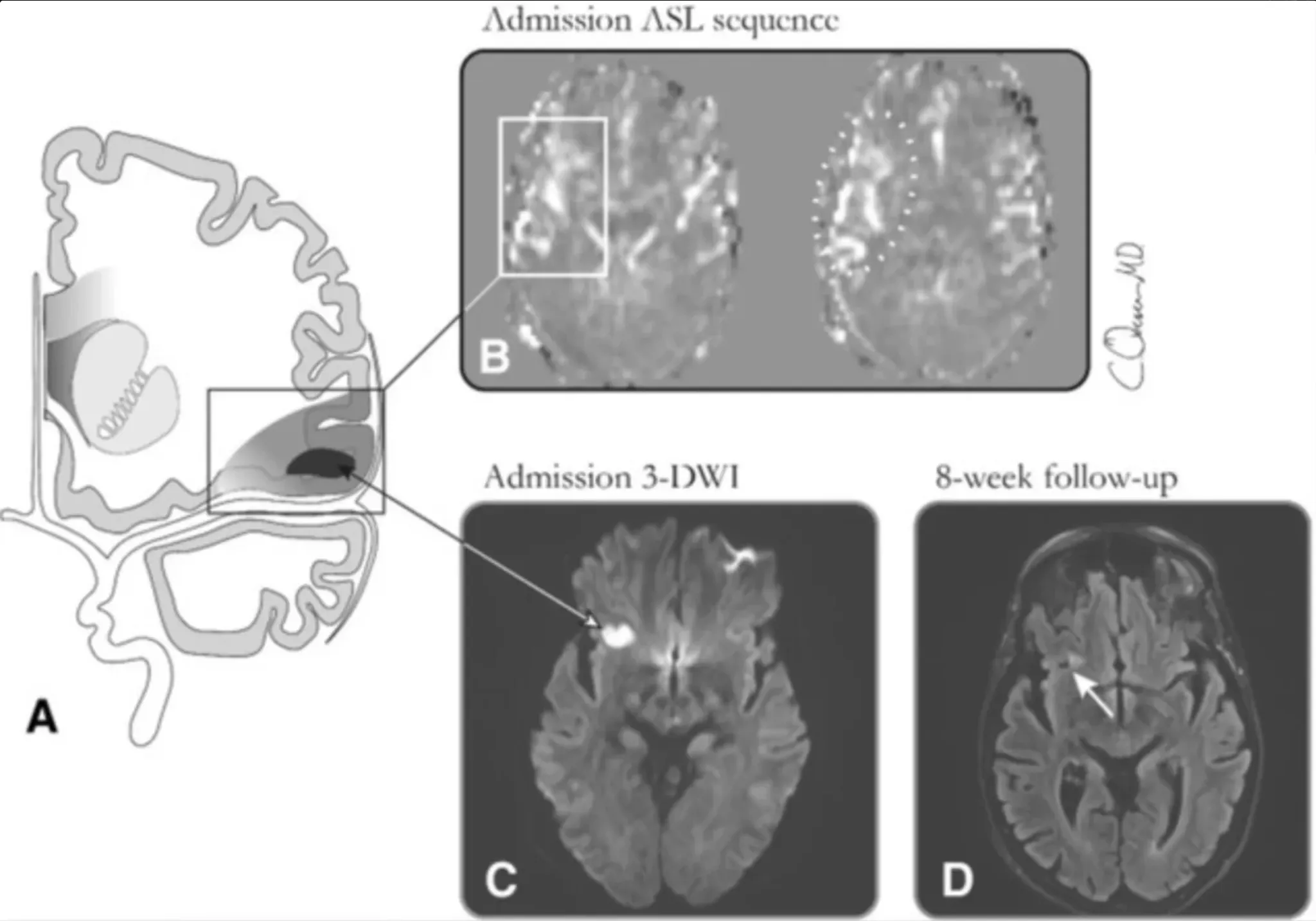
Medical VLLM-24-B Response
raw-response

MD-Format

Our 24 B-parameter Medical VLM Raises the Bar on MultiMedEval
What MultiMedEval brings to the table
MultiMedEval is an open-source benchmarking toolkit tailored to medical vision-language models (VLMs). Instead of forcing you to juggle dozens of scripts and scoring conventions, it bundles 24 tasks drawn from 23 datasets that span ten imaging modalities (X-ray, CT, MRI, pathology, dermatology, etc.) and a few text-only challenges. After you implement a tiny batcher callback that feeds your model images + prompts, the library automatically downloads the datasets, runs the evaluation, and spits out harmonized metrics such as accuracy, BLEU, F1, recall, and more—all in one go. In short: plug in your model, get a panoramic report card.
Quick primer on the two VQA datasets used here
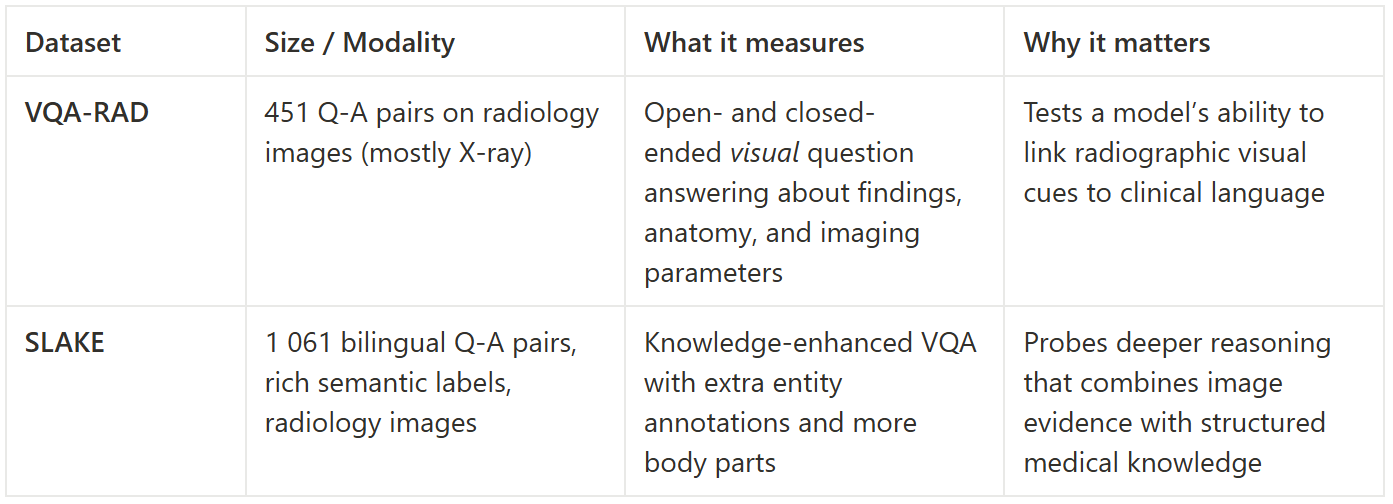
Numbers that speak for themselves

Why does our Medical VLM win?
1. Domain-specific visual backbone
We swapped the vanilla CLIP-style vision encoder for one pre-trained on >5 M curated medical images (CXR, CT, pathology slides). That sharper visual prior pays off on tasks like VQA-RAD where tiny radiographic cues matter.
2. Biomedical language alignment
Instead of generic instruction tuning, we fine-tuned with 1.4 M radiology reports, PubMed abstracts, and de-identified clinical notes. The language head therefore “speaks radiologist” and handles acronyms, measurements, and nuanced findings—crucial for SLAKE’s knowledge-heavy queries.
3. Multi-stage curriculum
- Stage 1: contrastive image–text pre-training to ground visual tokens.
- Stage 2: synthetic VQA generation with a radiology LLM “teacher” to give the model thousands of extra image-grounded Q-A examples.
- Stage 3: human-verified hard-negative mining to reduce hallucinations.
4. Parameter allocation
Although both models weigh in at ~24 B parameters, our architecture dedicates ~30 % more capacity to cross-modal fusion layers rather than pure text depth. That design choice boosts reasoning that needs tight image-text interplay (the core of both VQA datasets).
5. Better prompt handling
Our tokenizer keeps tokens separate from narrative text, which reduces the “prompt length tax” that can eat into the model’s context window—especially relevant when MultiMedEval issues multi-turn conversations.
Take-home message
MultiMedEval shows that simply scaling a general-domain LLM isn’t enough for healthcare. Purpose-built medical VLMs—trained with clinical images, grounded Q-A, and domain-aware alignment—deliver +13 pt average gains on the very benchmarks that matter to radiologists and AI researchers alike. If robust medical reasoning with images is your goal, specialization wins the day.
Conclusion
Medical VLM-24B and Spanish Medical LLM-24B represent the next generation of medical AI, demonstrating that specialized models significantly outperform general-purpose systems in healthcare applications. Our Medical VLM-24B achieves groundbreaking results on MultiMedEval benchmarks, with a 67.2% average score—a 13-point improvement over general-domain models like Mistral-24B-2503.
This performance leap stems from purpose-built medical specialization: domain-specific visual training on over 5 million curated medical images, biomedical language alignment using 1.4 million clinical documents, and a carefully designed multi-stage curriculum that reduces hallucinations while enhancing cross-modal reasoning.
By offering both English and Spanish capabilities, John Snow Labs addresses the needs of a truly global healthcare community. As MultiMedEval demonstrates, the future of medical AI lies not in scaling general models, but in deep domain specialization. Medical VLM-24B sets a new standard for visual medical reasoning, supporting improved patient outcomes and medical advancement across linguistic boundaries.
For healthcare providers and researchers seeking AI tools that truly understand medical imaging and language, the evidence is clear: specialization wins the day. These models mark a pivotal moment in medical AI, where domain expertise translates directly into measurable clinical value.



