Spark NLP is a free & open-source natural language processing library, built on top of Apache Spark and Spark ML. It provides an easy API to integrate with ML Pipelines and it is commercially supported by John Snow Labs. Spark NLP’s annotators utilize rule-based algorithms, machine learning and some of them Tensorflow running under the hood to power specific deep learning implementations.
The library covers many common NLP tasks, including tokenization, stemming, lemmatization, part of speech tagging, sentiment analysis, spell checking, named entity recognition, and more. The full list of annotators, pipelines, and concepts is described in the online reference. All of them are included as open-source and can be used by training models with your data. It also provides pre-trained pipelines and models, although they serve as a way of getting a feeling on how the library works, and not for production use.
Spark NLP library is written in Scala and it includes Scala and Python APIs for use from Spark. It has no dependency on any other NLP or ML library. For each type of annotator, we do an academic literature review to find the state of the art (SOTA), have a team discussion and decide which algorithm(s) to implement. Implementations are evaluated on three criteria:
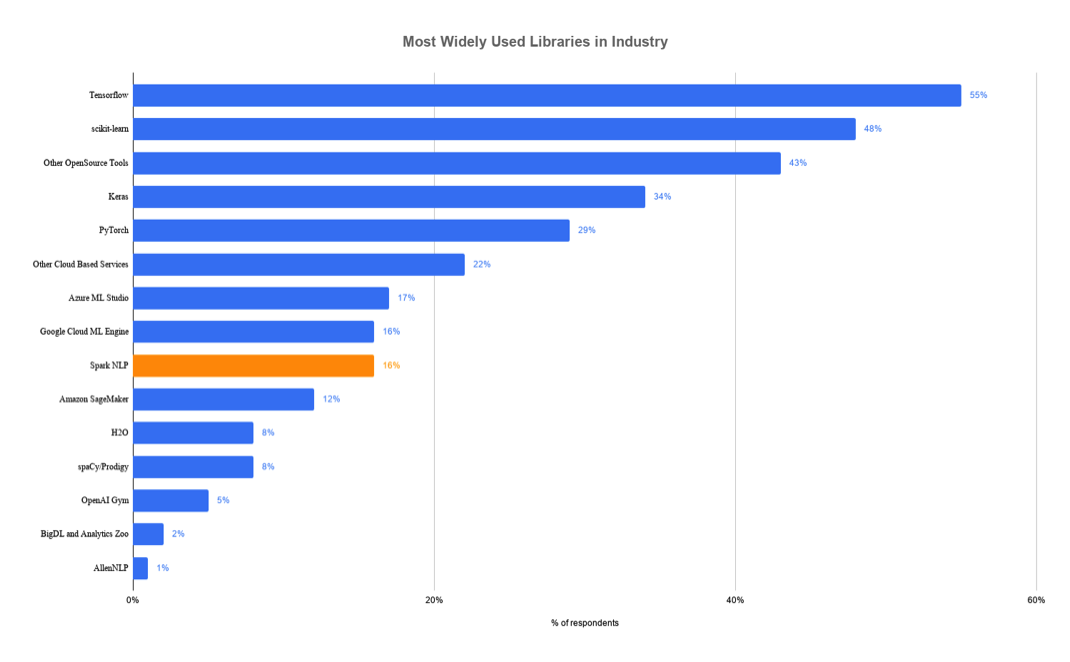
Spark NLP is geared towards production use in software systems that outgrow older libraries such as spaCy, NLTK, and CoreNLP. As of February 2019, the library is in use by 16% of enterprise companies and the most widely used NLP library by such companies.
- Accuracy — there’s no point in a great framework if it has sub-par algorithms or models.
- Performance — runtime should be on par or better than any public benchmark. No one should have to give up accuracy because annotators don’t run fast enough to handle a streaming use case, or don’t scale well in a cluster setting.
- Trainability or Configurability — NLP is an inherently domain-specific problem. Different grammars and vocabularies are used in social media posts vs. academic papers vs. electronic medical records vs. newspaper articles.
Built natively on Apache Spark and TensorFlow, the library provides simple, performant as well as accurate NLP notations for machine learning pipelines which can scale easily in a distributed environment. This library is reusing the Spark ML pipeline along with integrating NLP functionality.
In a recent annual survey by O’Reilly, it identified several trends among enterprise companies for adopting artificial intelligence. According to the survey results, Spark NLP library was listed as the seventh most popular across all AI frameworks and tools. It is also by far the most widely used NLP library — twice as common as spaCy. It was also found to be the most popular AI library after scikit-learn, TensorFlow, Keras, and PyTorch.
As a native extension of the Spark ML API, the library offers the capability to train, customize and save models so they can run on a cluster, other machines or saved for later. It is also easy to extend and customize models and pipelines, as we’ll get in detail during this article series. Spark NLP is open source with an Apache 2.0 license, so you are welcome to examine the full source code.
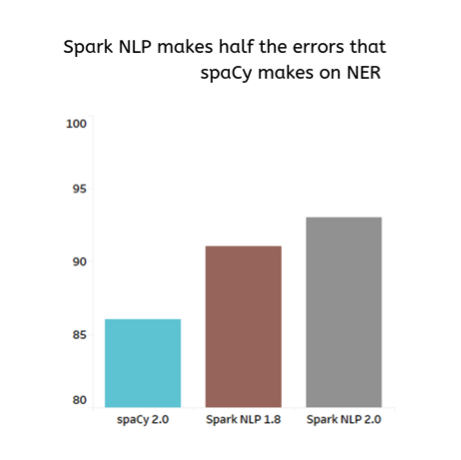
The rise of deep learning for natural language processing in the past few years meant that the algorithms implemented in popular libraries, like spaCy, Stanford CoreNLP, NLTK, and OpenNLP, are less accurate than what the latest scientific papers made possible.
Claiming to deliver state-of-the-art accuracy and speed has us constantly on the hunt to productize the latest scientific advances.
Optimizations are done to get Apache Spark’s performance closer to bare metal, on both a single machine and cluster, meant that common NLP pipelines could run orders of magnitude faster than what the inherent design limitations of legacy libraries allowed.
The most comprehensive benchmark to date, Comparing production-grade NLP libraries, was published a year ago on O’Reilly Radar. On the left is the comparison of runtimes for training a simple pipeline (sentence boundary detection, tokenization, and part of speech tagging) on a single Intel i5, 4-core, 16 GB memory machine.
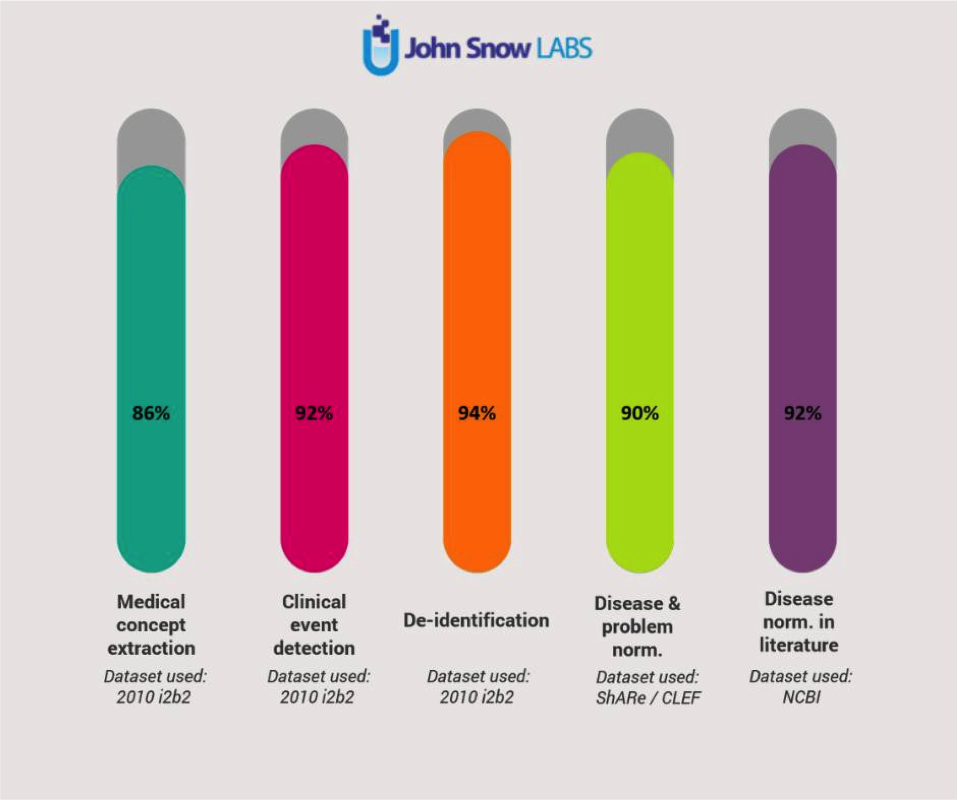
Being able to leverage GPU’s for training and inference has become table stakes. Using TensorFlow under the hood for a deep learning enables Spark NLP to make the most of modern computer platforms — from nVidia’s DGX-1 to Intel’s Cascade Lake processors. Older libraries, whether or not they use some deep learning techniques, will require a rewrite to take advantage of these new hardware innovations that can add improvements to the speed and scale of your NLP pipelines by another order of magnitude.
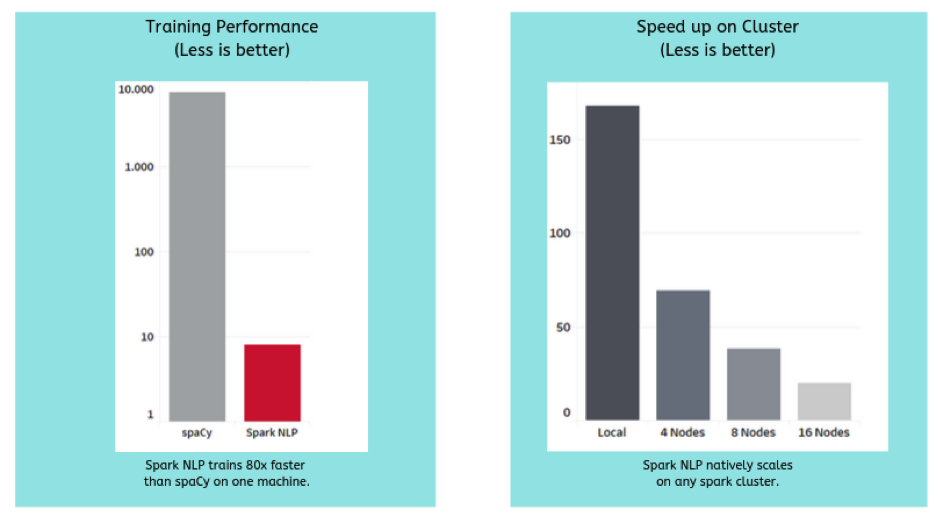
Being able to scale model training, inference, and full AI pipelines from a local machine to a cluster with little or no code changes has also become table stakes. Being natively built on Apache Spark ML enables Spark NLP to scale on any Spark cluster, on-premise or in any cloud provider. Speedups are optimized thanks to Spark’s distributed execution planning and caching, which has been tested on just about any current storage and compute platform.
This is how the functionality of the most popular NLP libraries compares:
Spark NLP also comes with an OCR package that can read both PDF files and scanned images (requires Tesseract 4.x+). This is the first NLP library that includes OCR functionality out-of-package.
By integrating Generative AI in Healthcare and enhancing the capabilities of a Healthcare Chatbot, organizations can streamline patient interactions, improve diagnostic accuracy, and harness the full potential of medical data, making healthcare more accessible and efficient.