
























































Annotation Lab is now the Generative AI Lab – the Free No-Code NLP Model Tuning & Validation by John Snow Labs with the ability to annotate documents.
The Data Annotator & Active Learning enables human experts to efficiently label text, image, audio & video data for training AI models with support for active learning, teamwork, and enterprise-grade security.
John Snow Labs is announcing the general availability of his enterprise-grade Data Annotator, which is now included at no additional cost with all its software subscriptions.
High-quality labelled training data empowers machine learning and deep learning, but labels can be time-consuming and expensive to generate. This is particularly true in domains such as healthcare, where data security & privacy concerns, along with the expertise needed to label data – for example, extract & normalize tumour characteristics from a pathology report – prevent crowd-sourcing from being a viable choice.
Given the scarcity and cost of human experts, a successful data annotation tool must optimize each user’s productivity and flow. The next challenge is to enable teams to work effectively together – not only by supporting projects, versioning, and role-based access but also by enabling workflows that ensure very high agreement between experts.
The nlp annotation work must then be fully integrated as part of a complete “human-in-the-loop” AI workflow: model pre-training, human annotation, model re-training, evaluation, and selection of the next questions to ask the human experts (a.k.a. active learning). There are three things we focus on for the human experts, in order to make this closed-loop AI work.
Speed: Keeping annotators “in the zone”
The Annotator is designed to keep a human expert as productive as possible. We’re minimized the number of mouse clicks, keystrokes, and eye movements in the main workflow, based on iterative feedback from daily users.
Keyboard shortcuts are supposed for all annotations – to enable having one hand on keyboard, one hand on mouse, and eyes on screen at all time. One-click completion and automated switching to the next task keeps experts in flow.
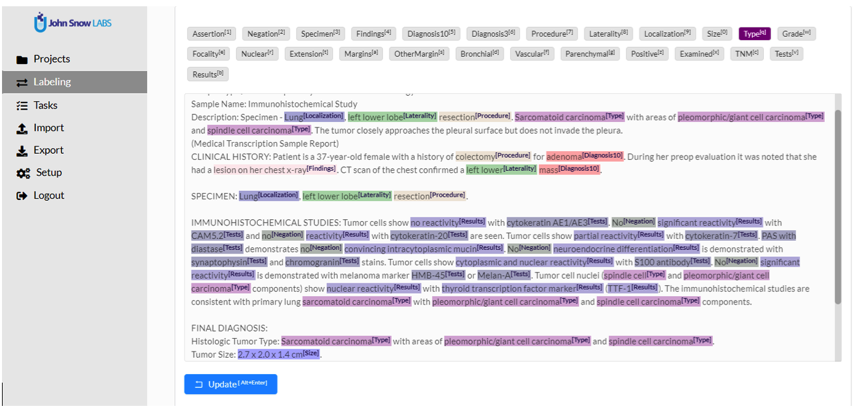
Versatility: Text, Images, Audio, and Video
While the Annotator is primarily integrated with Spark NLP Library when labeling text, it can also be used for other popular annotation use cases, and connected to other machine learning backends. The annotator was originally based on the LabelStudio open-source project, known as a “swiss-army knife of data labeling and annotation” and supporting a variety of use cases:
- Text – entity recognition, relationship extraction, document classification, summarization, translation
- Images – object detection, polygon segmentation, image classification (here you can find full scale image annotation tool)
- Audio – identify multiple speakers, emotion segmentation, transcription, audio classification
- Video – Video classification

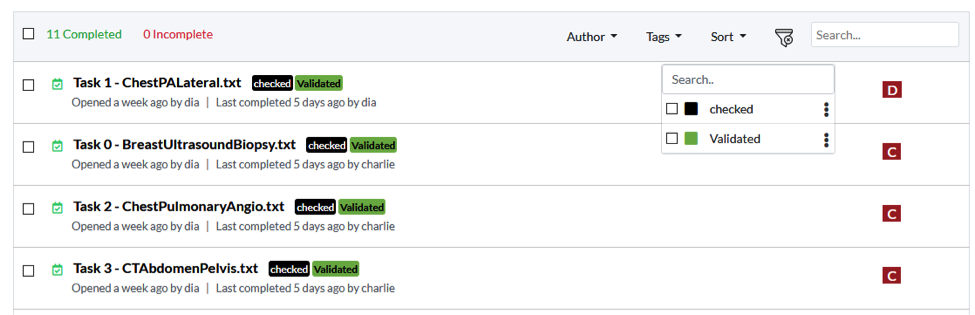
Teamwork: Projects, Workflows, Roles, Versioning & Audit
A team of people can work together on a large annotation project. This is critical for complex projects which require training many models (for multiple languages, specialties, or outcomes) quickly. The annotator centers all work around the concept of projects and teams, and then adds the following features to help them deliver effectively together:
- Configurable workflows: Use tags and permissions to implement workflows that include first-level annotators, second-level reviewers, splitting work across a team, and so on.
- Role-based access control: Enterprise-grade authentication, authorization, and fine-grained permissions ensure that every person only has access to what they need.
- Full audit trail: Each saved entry is stored along with an authenticated user and a time stamp, and the user interface includes a visual comparison between versions.
John Snow Labs’ Data Annotator has been in daily use by our enterprise customers for several months. It has now proven to address large, complex, real-world healthcare data labeling challenges. We are excited to share it with our entire customer community – and help them deliver on the promise of healthcare AI faster.
Best Practices & Tools for Accurate Document Annotation and Data Abstraction Webinar
If you’re working on machine learning tasks such as sentiment analysis, named entity recognition, text classification, image classification, or audio segmentation, then don’t miss the webinar on May 27th at 2 pm EST on ‘Best Practices & Tools for Accurate Document Annotation and Data Abstraction’.
This webinar will cover best practices for setting up an annotation team, the workflows that need to be in place for guaranteeing high accuracy and labeler agreement, and the tools that will help you optimize productivity and accuracy.
By integrating the Data Annotator for Human-in-the-Loop AI with all subscriptions, John Snow Labs enhances the power of Generative AI in Healthcare, enabling more accurate data processing and empowering a Healthcare Chatbot to deliver improved, real-time patient support.




