
























































Nearly 80% of enterprise intelligence remains locked inside documents — PDFs, scanned forms, lab reports, insurance claims, and medical records. These documents contain critical context that modern AI systems need, yet most organizations still rely on brittle OCR pipelines or cloud-only services never designed for regulated environments.
At John Snow Labs, we introduce JSL Vision: a family of state-of-the-art document understanding models built for enterprise workflows in healthcare, life sciences, and other regulated environments.
In recent years, the document understanding landscape has seen a rapid increase in new tasks and benchmarks for vision-language models, including OmniOCR, FUNSD, OmniDocBench, OmniMedVQA, PMC-VQA, GEMeX, MMLongBench-Doc, InfoVQA, AI2D, OCRBench, CharXiv and many others.
In this article, we focus on FUNSD and OmniOCR, which represent two core production settings: standard OCR and schema-constrained (JSON-based) OCR.
In the future we will cover more of these benchmarks.
Our models exceed the accuracy reported in recent industry benchmarks while running entirely on your own hardware — at competitive speed.
Why JSL Vision Is Different
JSL Vision was designed from day one for Healhcare organizations needs:
- On-premise or private cloud deployment
- Strict compliance requirements (HIPAA, GDPR, SOC2)
- Structured outputs ready for downstream systems
- Predictable performance at scale
No data leaves your environment. No black-box pipelines.
Two Core Capabilities, One Unified Vision
JSL Vision focuses on the two document understanding tasks that matter most in production. For each task, we release off-the-shelf ready to use models available in speed-optimized and accuracy-optimized variants.
- Classical OCR (Plain Text Extraction)
Designed for clean, human-readable text extraction from documents such as:
- Clinical notes
- Lab reports
- Discharge summaries
- Insurance documents
Available models on Sagemaker and Docker
- jsl_vision_ocr_1.0 : Our most accurate frontier OCR model
- jsl_vision_ocr_1.0_light : 2.3x faster and cheaper, 6% less accurate
Accuracy That Reflects Human Reading
Many benchmarks inflate OCR accuracy by optimizing for token-level similarity rather than real usability.
JSL Vision is trained and evaluated using:
- The widely adopted FUNSD dataset
- Natural human reading order (top-left → bottom-right)
- Character Error Rate (CER), a metric that better reflects real-world readability
The result: clean, human-style text that works reliably for search, summarization, and clinical reasoning.
We train on the FUNSD dataset, normalizing labels into natural reading order (top-left → bottom-right) with Character Error Rate (CER) as metric
This makes benchmarking more reflective of real human reading.
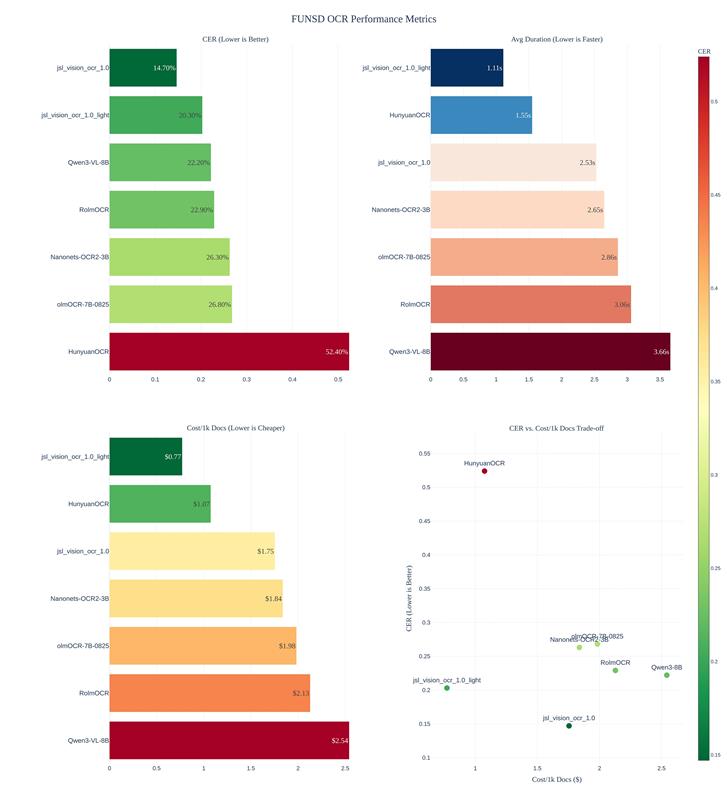
Costs are estimated with 2.5$/hour for a H100
These models focus on pure OCR: clean, human-style plain text extraction.

Sample noisy document scan and OCR prediction
- JSON Schema–Based OCR (Structured Extraction)
Many medical and enterprise workflows don’t just need text — they need structured data.
These models extract information directly into a predefined JSON schema, making them ideal for:
- EHR ingestion
- Claims automation
- Clinical trial data capture
- Downstream analytics and decision systems
- Diagram and form parsing
Available models on Sagemaker and Docker
- jsl_vision__structured_ocr_1.0: Our most accurate JSON OCR frontier model
- jsl_vision__structured_ocr_1.0_light: 4.3x faster and cheaper, 5% less accurate
Guaranteed Structured Outputs — Not Post-Processing
Unlike traditional OCR pipelines that rely on fragile post-processing rules, JSL Vision uses schema-aware generation.
You provide:
- A document image
- A JSON schema defining exactly what you need from the document
The model returns valid, schema-compliant JSON — without regex, custom parsers, or error-prone cleanup.
Structured outputs are guaranteed.
JSON Schema OCR accuracy
We evaluate using the Omni OCR JSON dataset together with their recommended JSON-diff metric. This is a well-defined popular dataset and metric for this problem
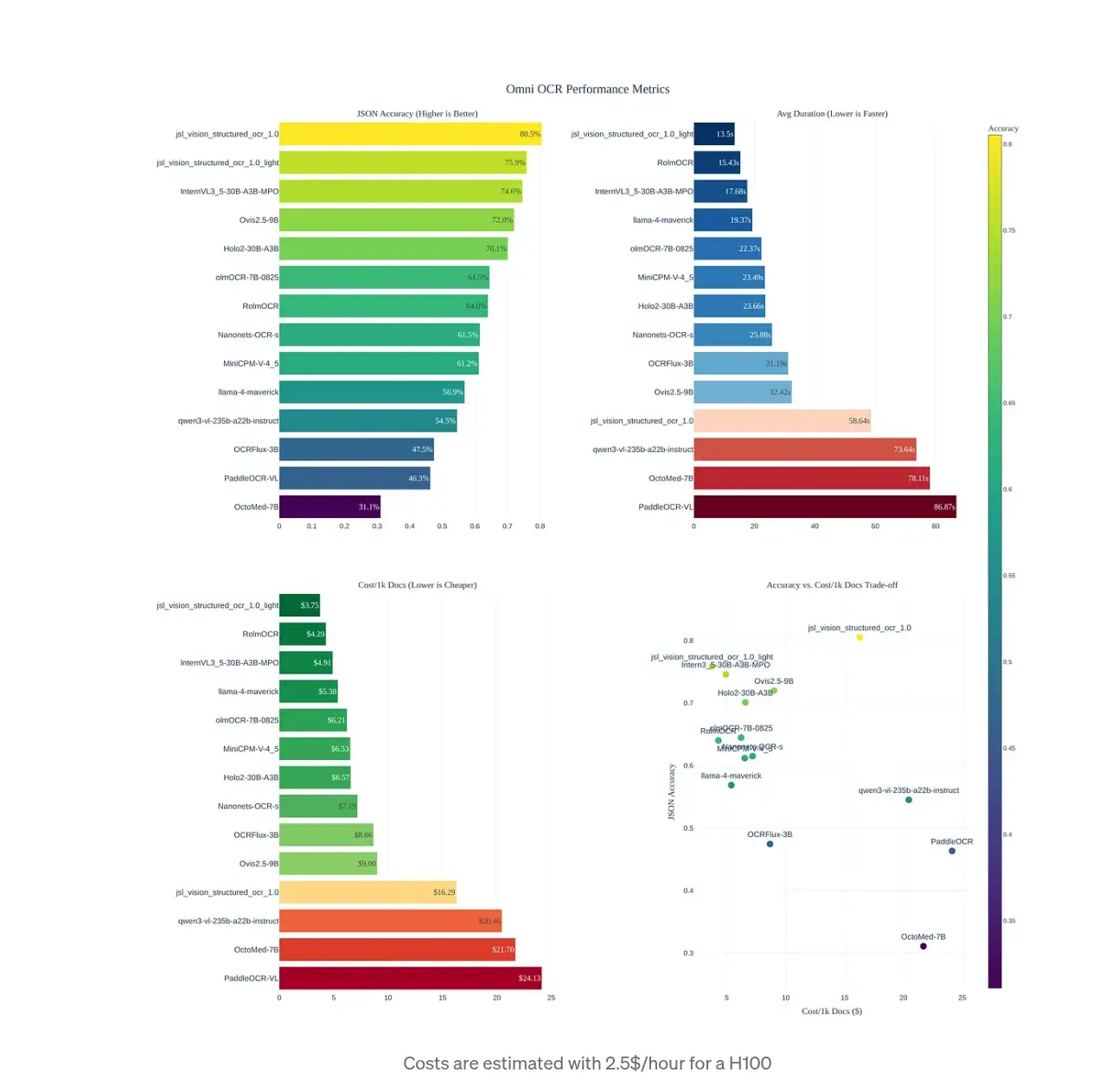
Costs are estimated with 2.5$/hour for a H100
The model is provided with an image and a schema that enforces predictions to be valid, schema-defined JSON.

Sample Input Schema+Image and model JSON prediction for it
Built for Enterprise Deployment
All JSL Vision models are:
- Deployable via Docker or Amazon SageMaker
- Optimized for high-throughput production workloads
- Tested on enterprise-grade GPUs (single-node setups)
Benchmarking Scope
In this article, we report benchmarks and comparisons against publicly available open-source models.
Evaluations against proprietary, closed-source systems (e.g., GPT-5) will be included in a future release.
Benchmarks were run on a single NVIDIA H100, demonstrating that state-of-the-art document intelligence no longer requires massive distributed infrastructure.All models support any image-convertible format, including PDF, PNG, and JPG.
Demos, and notebooks will follow.




