
























































In our previous article, JSL Vision: State-of-the-Art Document Understanding on Your Hardware, we benchmarked JSL Vision against leading open-source vision-language models on FUNSD and OmniOCR
In this follow-up, we address the natural next question we hear from enterprise teams:
How does JSL Vision compare to closed-source, frontier models like GPT-5 and other proprietary vision systems?

Task 1: Plain Text OCR (FUNSD)
Result: On Par with Closed-Source SOTA
For classical OCR, JSL Vision matches the accuracy of closed-source frontier systems on the FUNSD dataset while beeing up to 17x cheaper
Key evaluation choices:
- Natural human reading order (top-left → bottom-right)
- Character Error Rate (CER), not token similarity
- No layout-specific heuristics or post-processing
This matters because many OCR benchmarks over-optimize for token alignment rather than readability and downstream usability.
For this task we offer 2 models on Sagemaker and as Docker container:
- jsl_vision_ocr_1.0 which is 7.5x cheaper than the best alternative
- jsl_vision_ocr_1.0_light which is 17x cheaper the best alternative
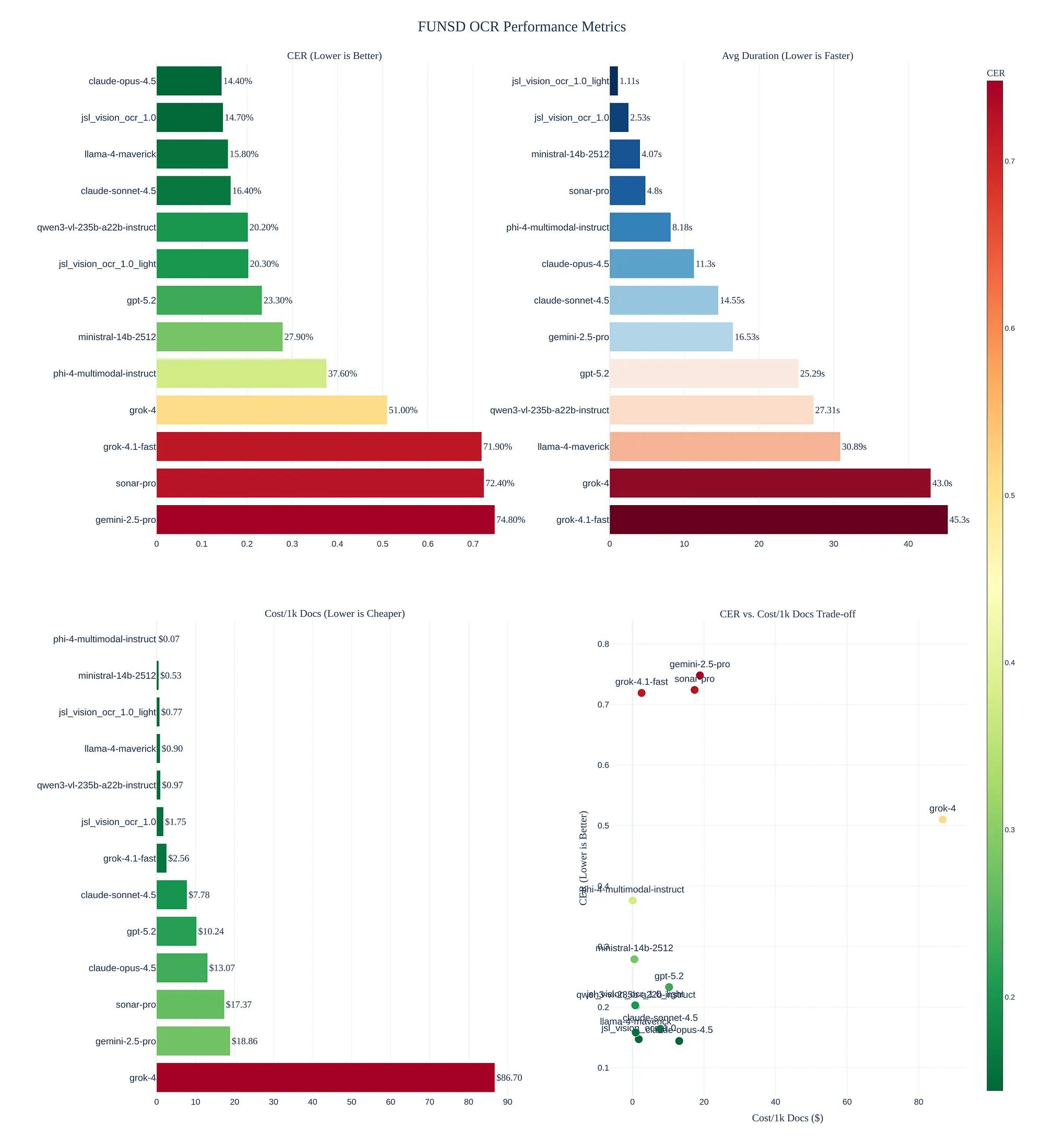
Costs are estimated with 2.5$/hour for a H100 for the JSL models and via OpenRouter for the closed source models
Why This Is Important
In production, plain OCR feeds:
- Search and retrieval
- Clinical summarization
- RAG pipelines
- Compliance audits
At this stage, there is no measurable accuracy advantage to using a closed source system for plain OCR — only operational downsides.
Task 2: JSON Schema–Based OCR (Structured Extraction)
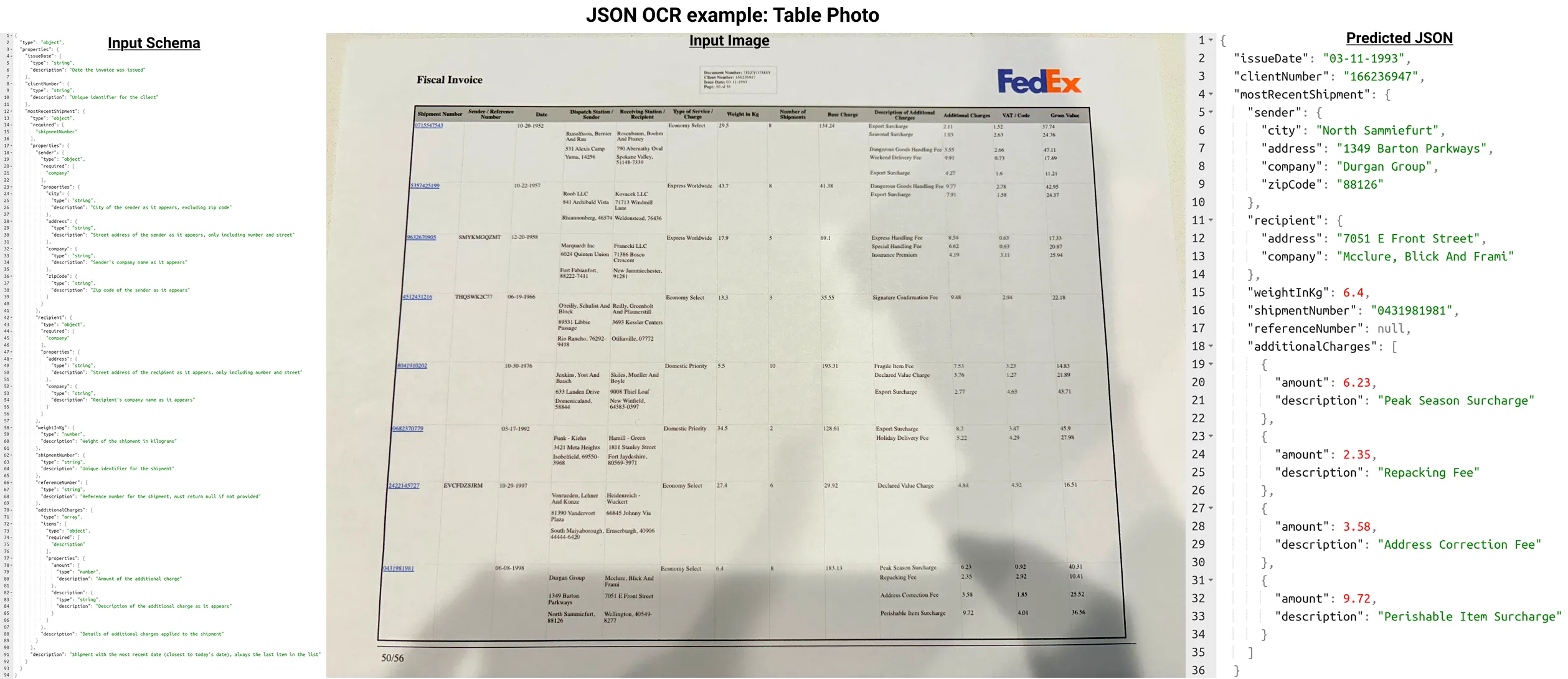
JSON Schema examples to extract the most recent shipment from a table
What JSL Vision Optimizes for Instead
JSL Vision takes a different approach:
- Explicit schema-aware generation
- Guaranteed valid JSON outputs
- No post-hoc repair, regex, or cleanup
- Deterministic, auditable behavior
In many enterprise workflows, invalid JSON is worse than slightly lower recall.
A model that produces:
- Broken JSON
- Hallucinated keys
- Schema drift across runs
…is operationally unusable, regardless of benchmark score.
For this task we offer 2 models on Sagemaker and as Docker container:
- jsl_vision_structured_ocr_1.0: which is 3.7x cheaper than the best alternative
- jsl_vision_structured_ocr_1.0_light which is 16.1x cheaper than the best alternative
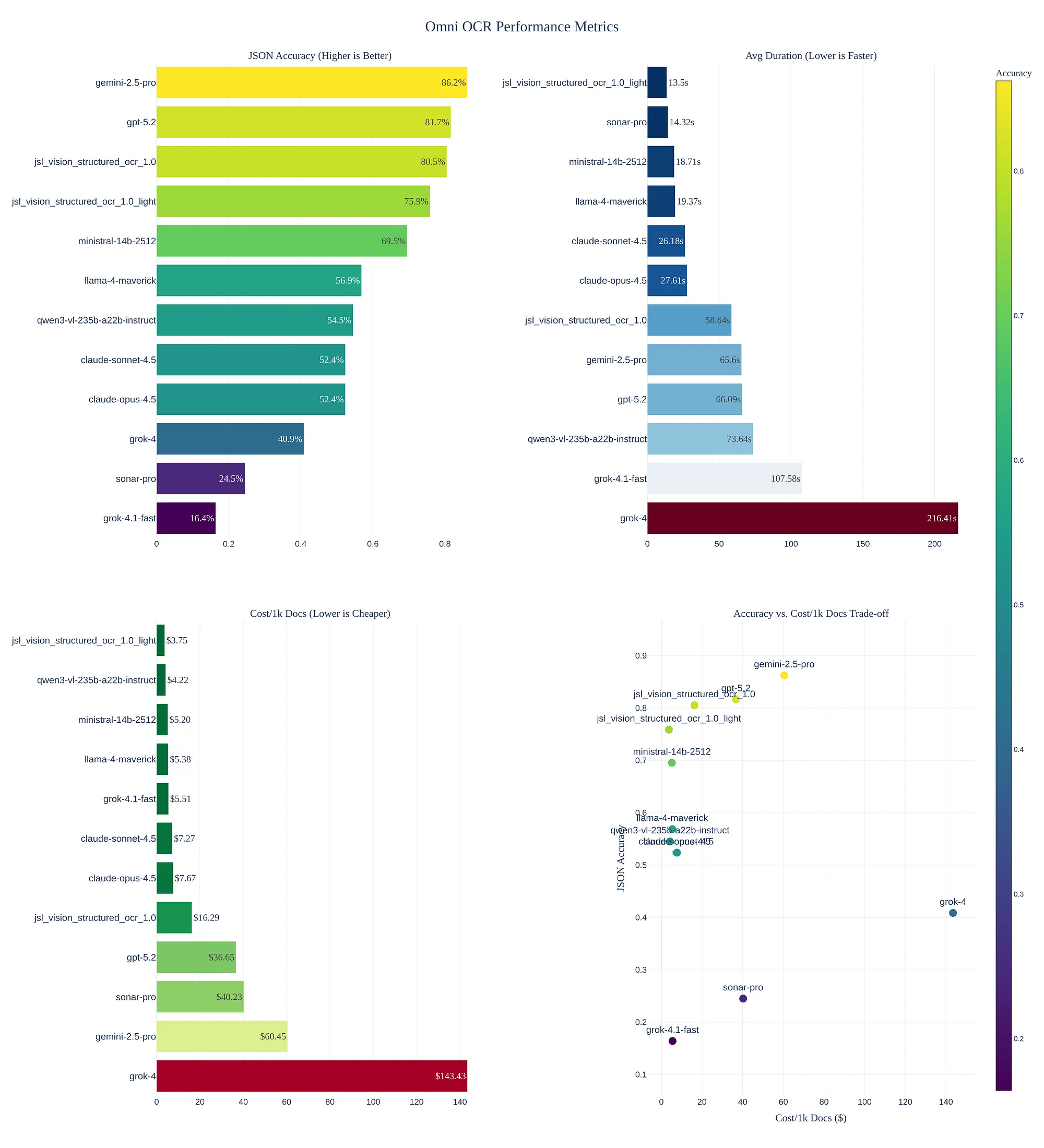
Costs are estimated with 2.5$/hour for a H100 for the JSL models and via OpenRouter for the closed source models.
What This Means for Enterprises
If you need:
- On-prem or private cloud
- HIPAA / GDPR / SOC2 compliance
- Deterministic JSON outputs
- Predictable performance and cost
JSL Vision delivers frontier level accuracy without compromising control.
State-of-the-art document understanding no longer requires giving up your data — or your infrastructure
What’s Next
In the future we will release tutorials and cover more benchmarks such as OmniDocBench, OmniMedVQA, PMC-VQA, GEMeX, MMLongBench-Doc, InfoVQA, AI2D, OCRBench, CharXiv and others.




