Large language models (LLMs) have showcased impressive abilities in understanding and generating natural language across various fields, including medical challenge problems. In a recent study by OpenAI, researchers conducted a thorough evaluation of GPT-4 on medical competency exams and benchmark datasets. GPT-4 is a versatile model, not specifically designed or trained for medical problems or clinical tasks. Assessment includes MultiMedQA and two sets of official USMLE (US Medical License Exam) practice materials, a three-step exam program for evaluating clinical competency and granting licensure in the US.
The study reveals that, without specialised prompting (zero-shot), GPT-4 surpasses the USMLE passing score by over 20 points and outperforms earlier general-purpose models (GPT-3.5) as well as those fine-tuned for medical knowledge (Med-PaLM, a prompt-tuned version of Flan-PaLM 540B). Furthermore, GPT-4 displays better calibration than GPT-3.5, indicating a significant improvement in its ability to predict answer correctness.
Experiments in another study evaluating LLM APIs on the Japanese national medical licensing examinations show that GPT-4 outperforms ChatGPT and GPT-3 and passes all six years of the exams, highlighting LLMs’ potential in a language that is typologically distant from English.
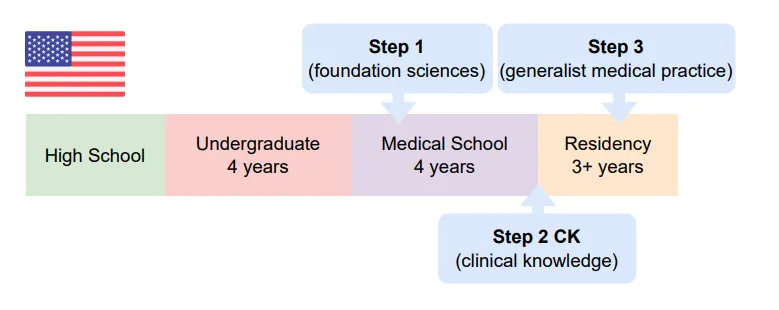
Standard timeline of USMLE (US Medical License Exam) that consists of three steps, which are taken over a period of time during medical school and residency
In another fascinating study, researchers set out to investigate the capabilities of ChatGPT, specifically the GPT-3.5 and GPT-4 models, when it comes to understanding complex surgical clinical information. They put the medical GPT models to the test using 280 questions from the Korean general surgery board exams conducted between 2020 and 2022. Results show that GPT-3.5 managed to achieve an accuracy of 46.8%, but GPT-4 stole the show with a whopping 76.4% accuracy rate, showcasing a significant improvement over its predecessor. GPT-4’s performance remained consistent across all surgical subspecialties, with accuracy rates ranging between 63.6% and 83.3%. While these results are undeniably impressive, the study reminds us to recognize the limitations of language models (all healthcare GPT models made mistakes) and to use them in tandem with human expertise and judgment, especially when it comes to something as crucial as surgical education and training.
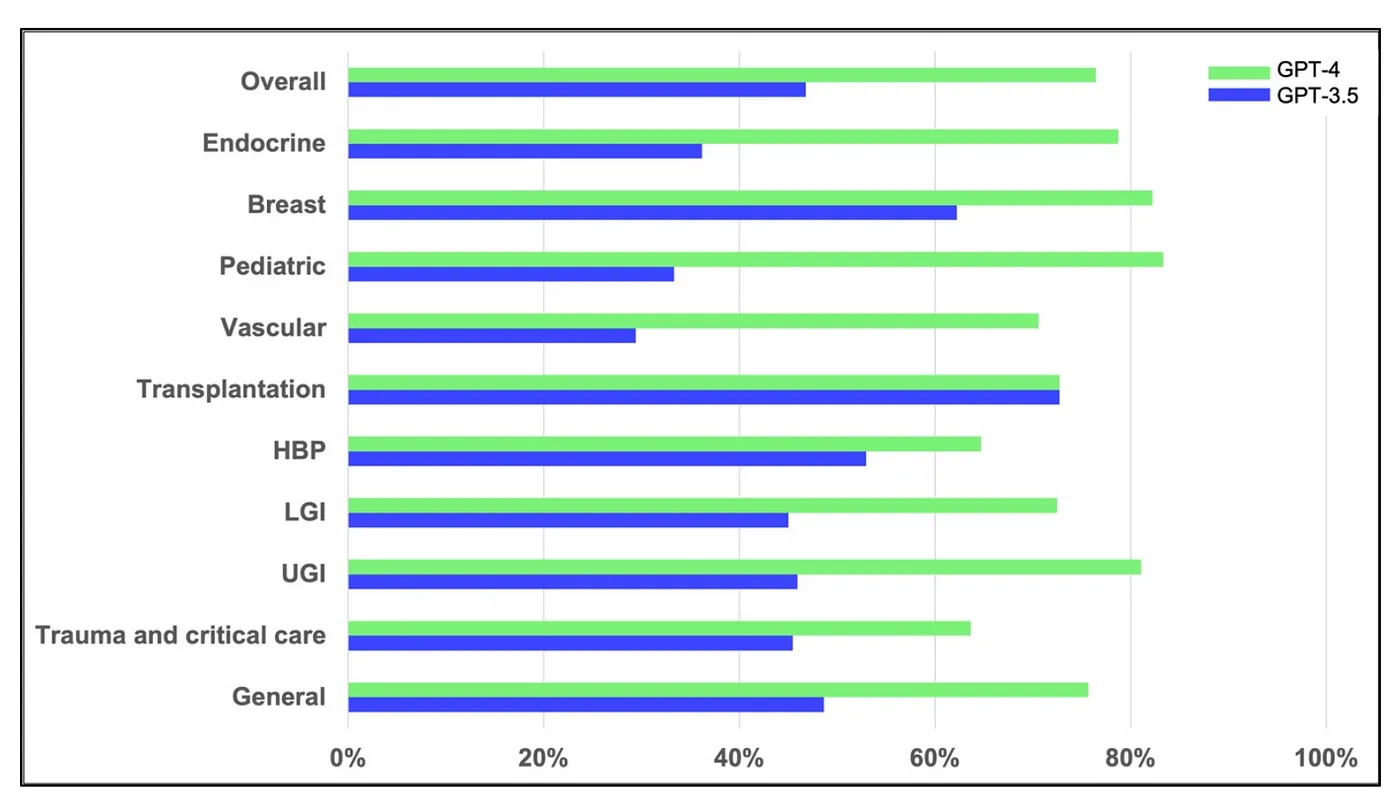
LLMs taking on Medical Challenge Problems: comparison of the performance of GPT-4 and GPT-3.5 with overall accuracy and accuracies according to its subspecialties. (source: ChatGPT Goes to Operating Room)
The benchmarks on academic medical benchmarks (MedQA, PubMedQA, MedMCQA and medical components of MMLU) also show promising results as shown below.
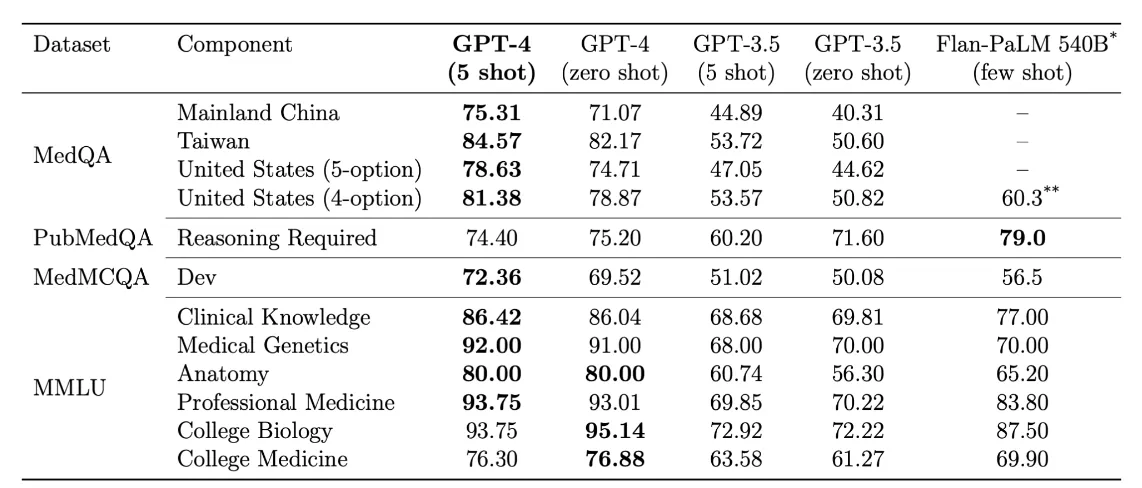
LLMs on medical challenges: Performance of different models on multiple choice components of MultiMedQA
In order to highlight the performance of GPT-4 on these datasets, lets compare these metrics with the performance of PALM and MedPALM LLMs released by Google.
- The highest score achieved by MedPALM is 67.6% on USMLE and 79% on PubMedQA.
- Flan version of PALM does better than GPT-4 on PubMedQA (79% vs 74.4%) but GPT-4 aces USMLE by a larger margin (81.38% vs %67.6).
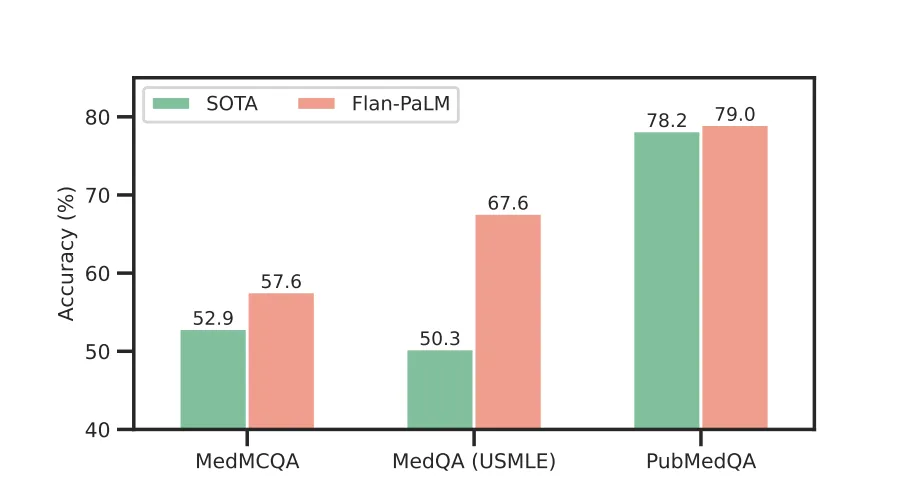
Performance of different models on multiple choice components of MultiMedQA
More information regarding the capabilities of GPT-4 on medical challenge problems can be found at an official OpenAI paper on the very same topic.
Then Google released Med-PaLM 2, an expert-level medical LLM, that closed this gap as shown below. Med-PaLM 2, consistently performed at an “expert” doctor level on medical exam questions, scoring 85%. This is an 18% improvement from Med-PaLM’s previous performance and far surpasses similar AI models; and also 4% improvement from GPT-4.
One of the reason for Med-PaLM doing better on medical datasets is because it is designed to operate within tighter constraints and has been trained on seven question-answering datasets that cover professional medical exams, research, and consumer inquiries about medical issues.
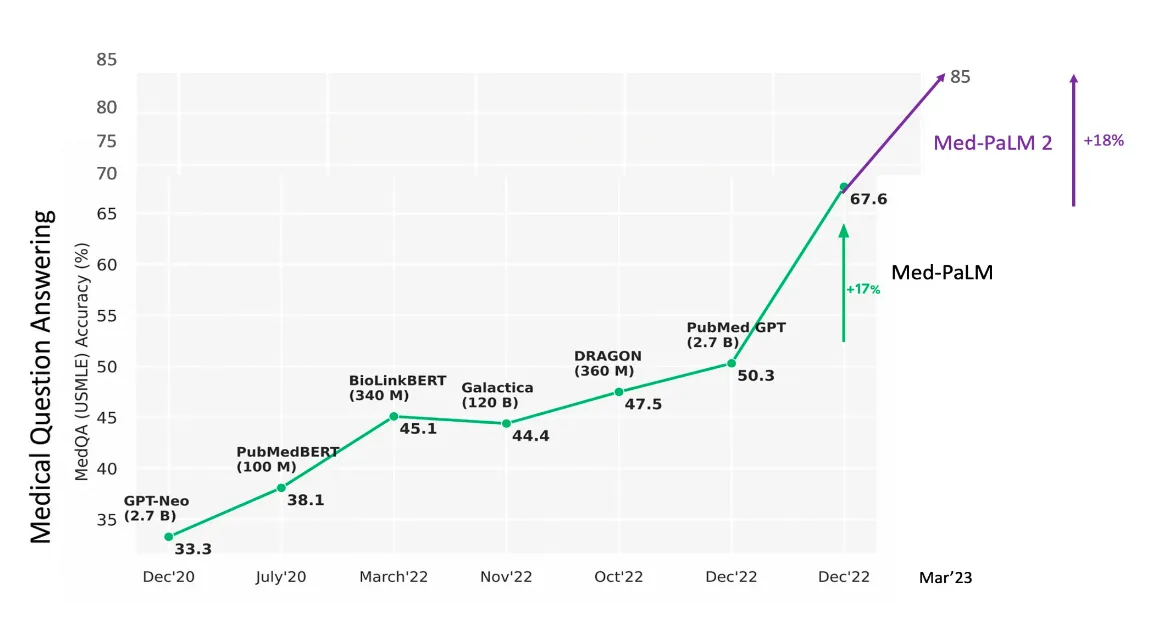
Med-PaLM 2, consistently performed at an “expert” doctor level on medical exam questions, scoring 85%. This is an 18% improvement from Med-PaLM’s previous performance
In Google’s official blogpost announcing MedPALM-2, it is stated that MedPALM is tested against 14 criteria — including scientific factuality, precision, medical consensus, reasoning, bias and harm — and evaluated by clinicians and non-clinicians from a range of backgrounds and countries. Through this evaluation, they found significant gaps when it comes to answering medical questions and meeting their product excellence standards.
Benchmark datasets fail to capture the needs of medical professionals
It has become increasingly evident that benchmark datasets are falling short in addressing the specific requirements of medical professionals. A recent analysis indicates that AI benchmarks with direct clinical relevance are limited in number and fail to encompass the majority of work activities that clinicians would like to see addressed. Notably, tasks related to routine documentation and patient data administration workflows, which carry a significant workload, are not represented in these benchmarks. Consequently, the AI benchmarks currently available are inadequately aligned with the desired targets for AI automation within clinical settings. To rectify this, it is crucial to develop new benchmarks that address these gaps and cater to the needs of healthcare professionals.
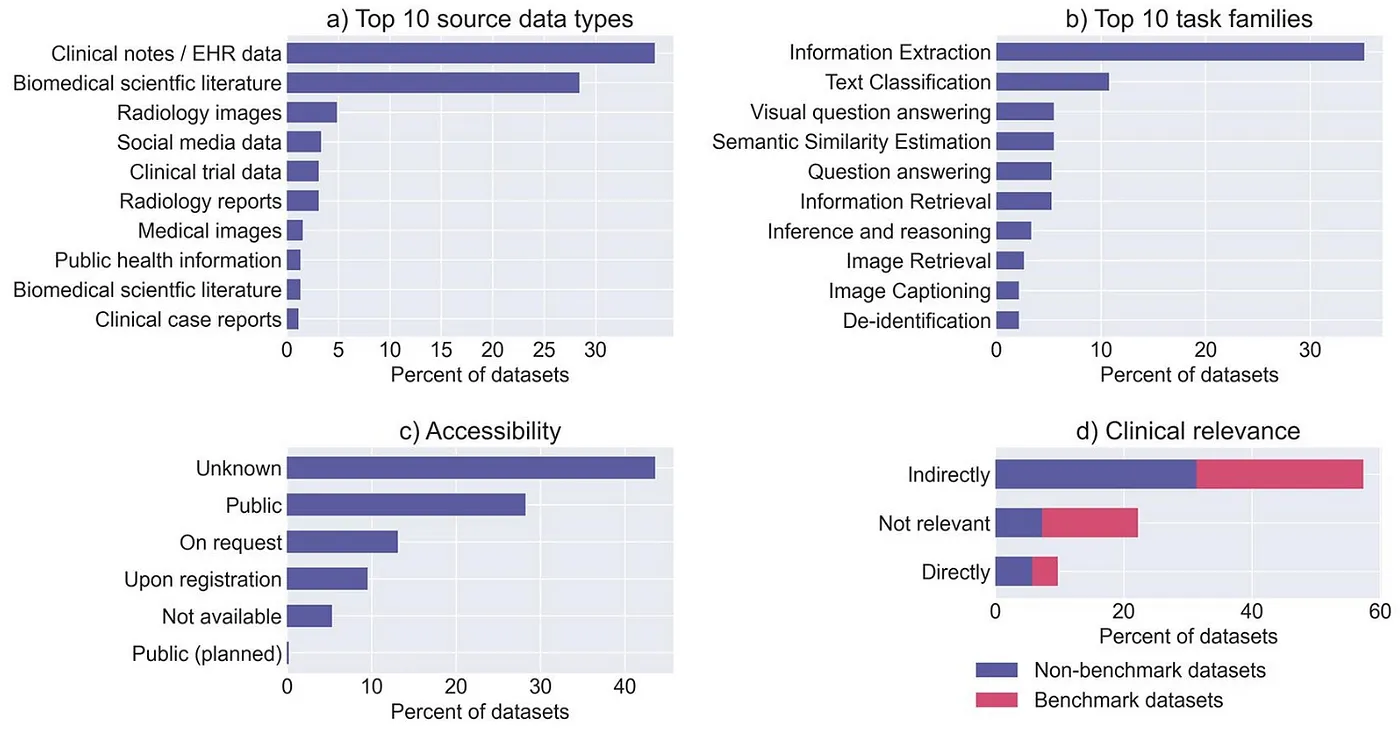
The characteristics of all datasets (i.e. benchmark datasets and non-benchmark datasets) included in the catalogue in terms of source data, task family, accessibility and clinical relevance (source: https://www.sciencedirect.com/science/article/pii/S1532046422002799#f0035)
In addition to evaluation concerns, another critical issue lies in the scarcity of openly available medical datasets or clinical notes. The proportion of these datasets, which are crucial for training LLMs for medical applications, is minuscule compared to the vast amount of other available datasets or open-source materials on the web that are typically used to train LLMs from scratch. This lack of specialized data hinders the development and fine-tuning of LLMs that could effectively meet the unique demands of medical professionals. As such, it is essential to prioritize the creation and dissemination of medical datasets and clinical notes that can be used to develop more targeted and effective AI solutions for the healthcare sector.
In summary, these systems were trained solely on openly available internet data, such as medical texts, research papers, health system websites, and publicly accessible health information podcasts and videos. Training data did not include privately restricted data, like electronic health records in healthcare organizations, or medical information exclusive to a medical school or similar organization’s private network.