We are experiencing the golden age of NLP, triggered by different key factors:
- More and more documents being digitalized or directly processed in digital format. This was a big issue for those documents which required a signature, specially legal documents. But as electronic signatures become the daily standard for signing documents, the data availablity increases.
- The advancements in Deep Learning, with specific mention to Transformers. What started with Google’s release of Bert Language Model, has evolved into a whole new range of different transformer architectures., to be added to earlier DL proposals (as LSTM with charNN for NER, for example), or even earlier statistical approaches as Naive Bayes, SVM, Random Forest / Ensembling methods, etc.
- Governments Open Data iniciatives;
- A big Open Source community sharing resources;
Some business areas have made a bigger progress than others, as if we compare Financial Services, where AI is a reality, to the Legal sector, where it is just beginning.
However, datasources as SEC’s Edgar (public), Lawinsider (propietary) and many other initiatives have triggered the inclusion of NLP in Legal Platforms, including of those for Contract Lifecycle Management (CLM), as Docux, Docusign, Juro, etc.
Low latency NLP in Legal CLMs
Contract Lifecycle Management requires a quick interaction, real-time response to the user requests. Although some asynchronous batch-processing may be relevant, if a user uploads a document to a CLM, they will look for quick NLP insights (2s–4s) on their documents.
Image from https://www.docusign.com/products/clm
Unfortunately, most of the State of the Art architectures, as Transformers, have a big latency, due to the complex computations they rely on. There are several actions we can take here to reduce latency:
- Apply Teacher-Student approaches (also known as Distillation) to get bigger architectures (as Bert) “teach” smaller ones, as DistilBert. Check this article about Knowledge Distillation.
- Apply Quantization (reducing the dimensionality of the weights in the Neural Network). This has an impact on the accuracy, as the Distillation, but the improvement may be worth it.
- Use lighter architectures, instead of Transformers or use low-dimensionality embeddings.
- And of course, parallelize the inference.
John Snow Labs Legal NLP
Legal NLP was released on Oct, 2022 by John Snow Labs.

Legal NLP by John Snow Labs
Legal NLP is part of the Spark NLP ecosystem, a set of cluster-ready libraries.
Cluster Vertical and Horizontal scalability
We call vertical scalability to the capability of a cluster to manage a batch request with huge volumes of data in an optimal way.
We call horizontal scalability to the capability of a cluster to process a huge number of requests concurrently, with a very low volume of data each.
While Spark is the best option to work on batches, it’s not the option to work with real-time, concurrent requests.
Spark NLP LightPipelines
To provide horizontal scalability, there is a specific Pipeline class in Spark NLP called LightPipeline. It’s totally optimized to run very quickly on small volumes of data. You can check an article about LightPipelines here.
Our proposal: a gRPC cluster with LightPipelines
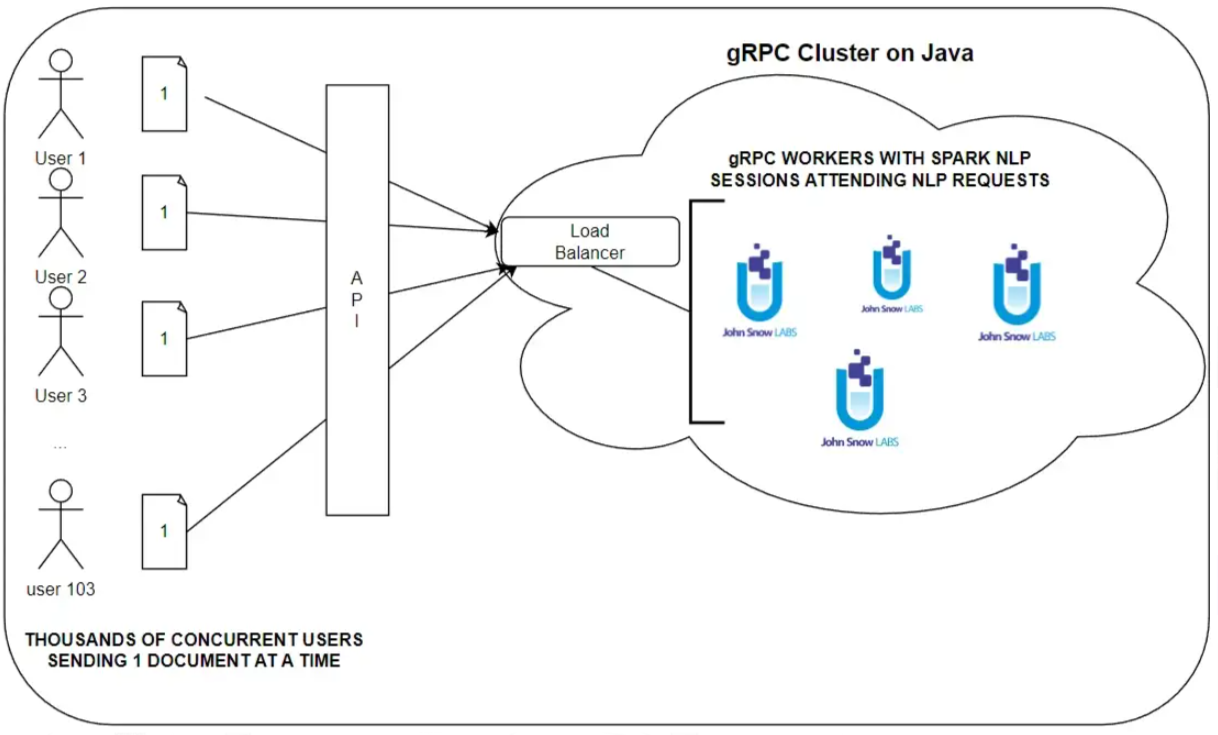
A gRPC cluster, with several workers running Legal Spark NLP sessions, communicating with the user via API
Let’s suppose now we have 103 users accessing concurrently my CLM platform. All of them need NLP insights in an interval from 2 to 4 seconds. How can we achieve that?
A gRPC cluster…
From grpc.io:
gRPC is a modern open source high performance Remote Procedure Call (RPC) framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking and authentication.
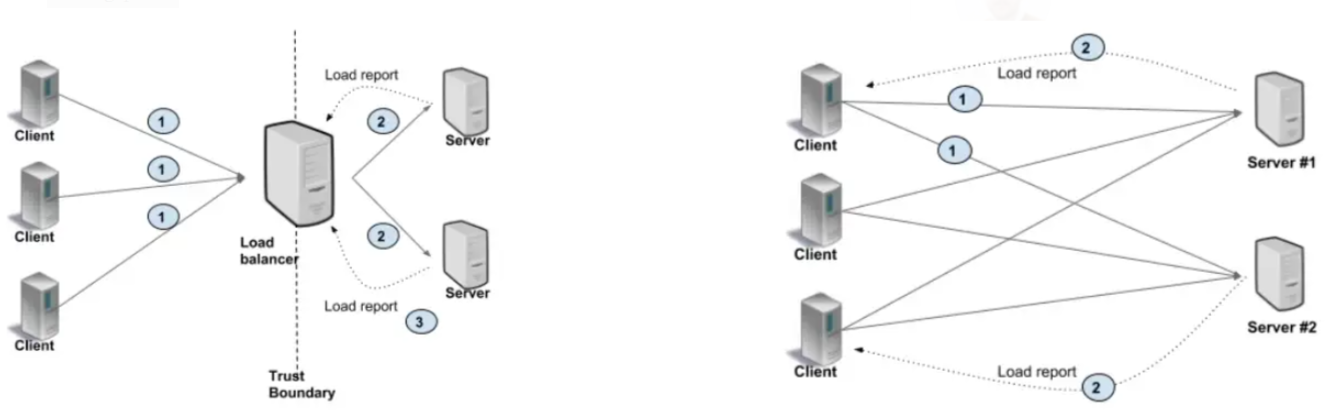
Left: client-side LB. Right: server-side LB.
Although is out of the scope of this article to configure a Load Balancer, you can find more information about it in here.
…with preloaded LightPipelines
Every worker will load and run inference using LightPipelines, loaded in memory. To do that, we need to try to minimize:
- The dimensions of the embeddings we are using. In our examples we will be using Sentence Bert (512d);
- Use only one type of embedding, and the rest of the components (Text Classification, NER, Relation Extraction, etc) should be run on the top of those embeddings (as classification layers). This is very easy to do with Legal NLP by John Snow Labs.
- Don’t use heavy Transformer architectures: use instead good, lighter models, as Legal NLP’s NerDL, ClassifierDL, RelationExtraction — all of them Deep Learning models, but non-transformer based.
- Split properly the texts and only run the models on those pieces of texts relevant for them.
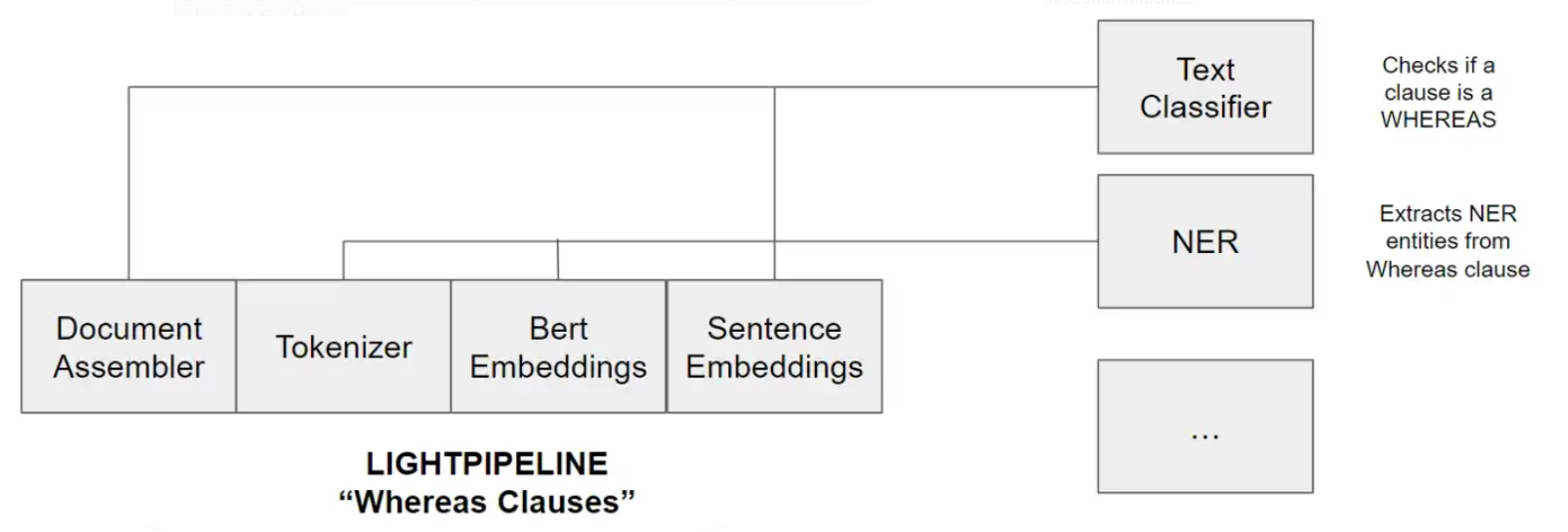
Example of one pipeline for classifying a clause as “Whereas” or not (Binary) and carry out NER on that clause
The size of ClassifierDL, NER and Relation Extraction models is very small, so you can plug in several modes in one pipeline, or even have several pipelines preloaded in memory.
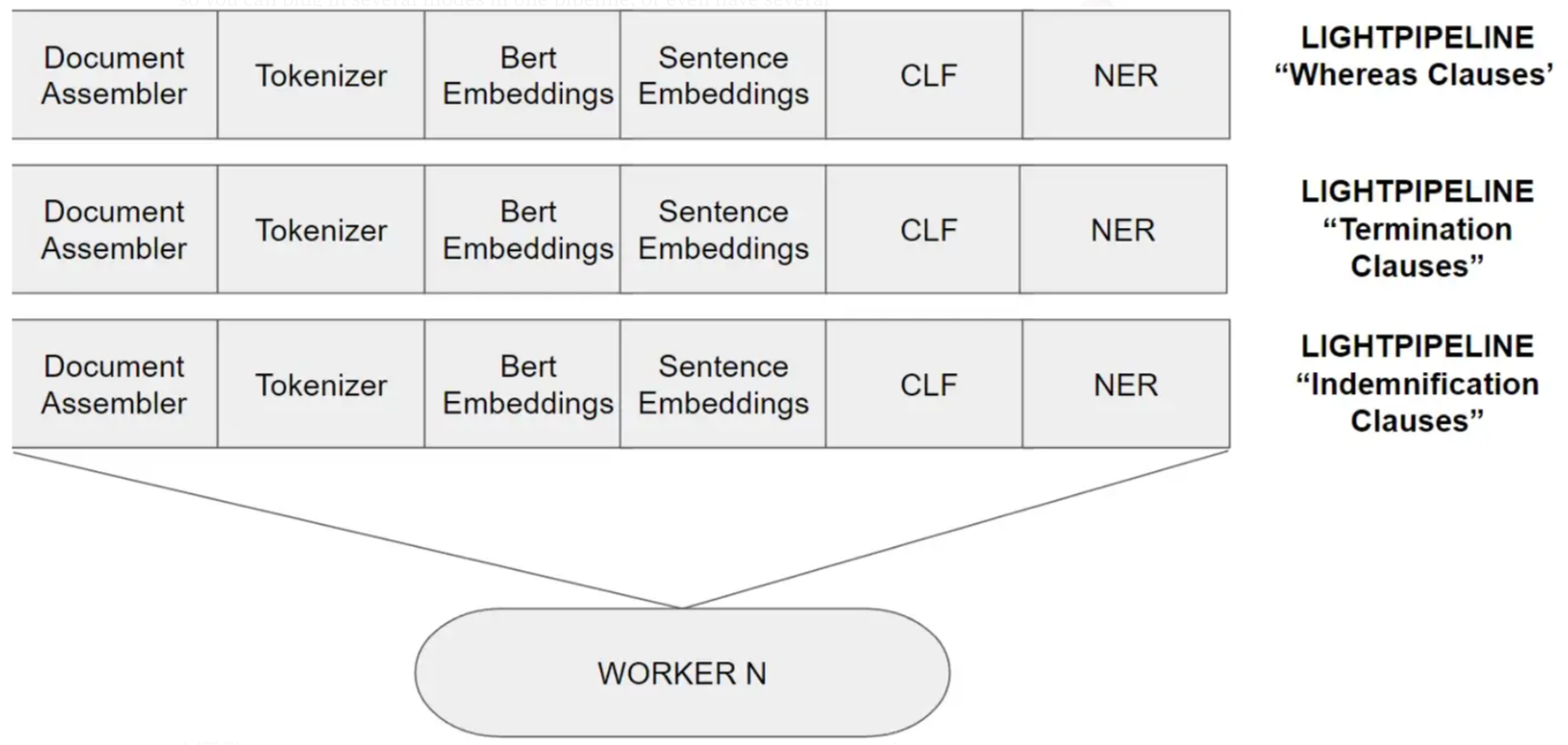
3 pipelines loaded in a worker
…attending requests via API
You can use API frameworks as Quarkus API in Java, to provide very low latency response times. Connect your front-end to the API Server in your cluster, ask the Load Balancer about the best worker to send the request to, and carry out NLP using the proper LightPipeline loaded in memory.
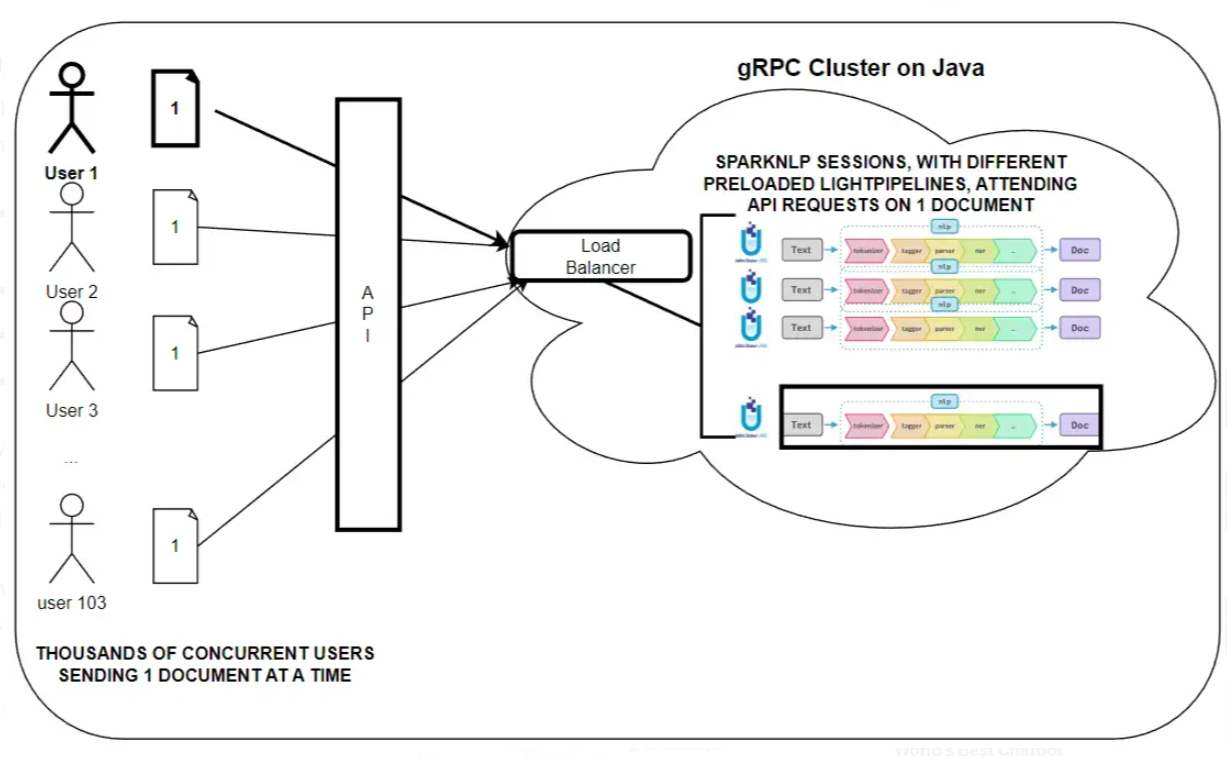
User 1 sends s request to the gRPC cluster to run a pipeline
Updated: Times
This is the benchmark showing inference times and latency in a grpc cluster in Java with the following specs:
- Processor Intel(R) Core(TM) i5–10300H CPU @ 2.50GHz, 2496 Mhz, 4 Core(s), 8 Logical Processor(s)
- System Type x64-based PC
- 16GB
- Spark 3.1.0, Scala 2.12, Java 1.8.0
We were able to fit in memory 1 Sentence Bert Embeddings model and 52 Deep Learning Classifiers, returning an inference time on a paragraph (1078 characters) of 0.5s per grpc request.
Evidently, the times are smaller as the fewer models are in the pipeline. This is how the progression looks like:
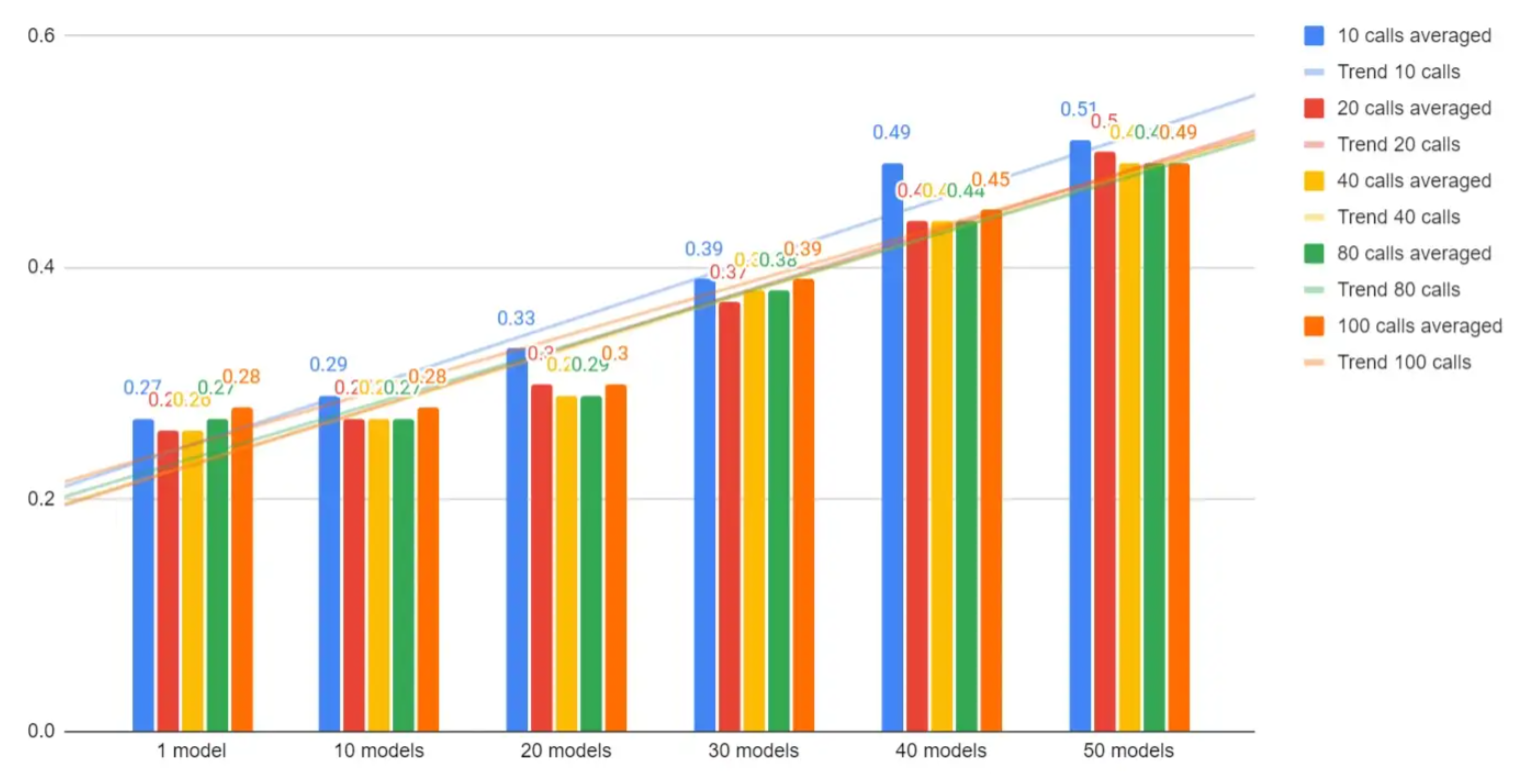
The times were calculating triggering 10, 20, 40, 80 and 100 calls each time. In the chart you can also see the trend modeled as linear.
gRPC code example
You can check a small example of serving gRPC in Java, without a load balancer or an API, just gRPC, to check the processing times we showed in the previous section here.

Logs from Legal NLP on grpc
Do you want to create a real-time Legal NLP module for your platform?
Contact us in Slack (#legal channel) or reach out to us in support@johnsnowlabs.com.