
























































Experience powerful machine translation with Spark NLP and Python’s multilingual capabilities.
In this article, you will learn how to use the Marian machine translation model at scale using Spark NLP in Python. There are multiple pretrained models freely available that can translate in many languages ready to be added in your processing pipelines.
Neural Machine Translation is the capability to use algorithms or machine learning models to automatically translate texts from one language to another. In this article, we will introduce the deep learning model Marian and how to use it in the Spark ecosystem with the open-source library Spark NLP in Python.
Automatic machine translation can be used in many scenarios, including the capability to translate web pages from languages you are not fluent in to read into one that you are. It can also improve your productivity by adapting previous contents in one language to another and save time to write it from scratch.
In the next sections, we will introduce Spark NLP and how to use the implemented MarianTransformer to translate texts between languages.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
To install Spark NLP, you can simply use any package manager like conda or pip. For example, using pip you can simply run pip install spark-nlp. For different installation options, check the official documentation.
Spark NLP processes the data using Pipelines, a structure that contains all the steps to be run on the input data the same way Spark ML does.
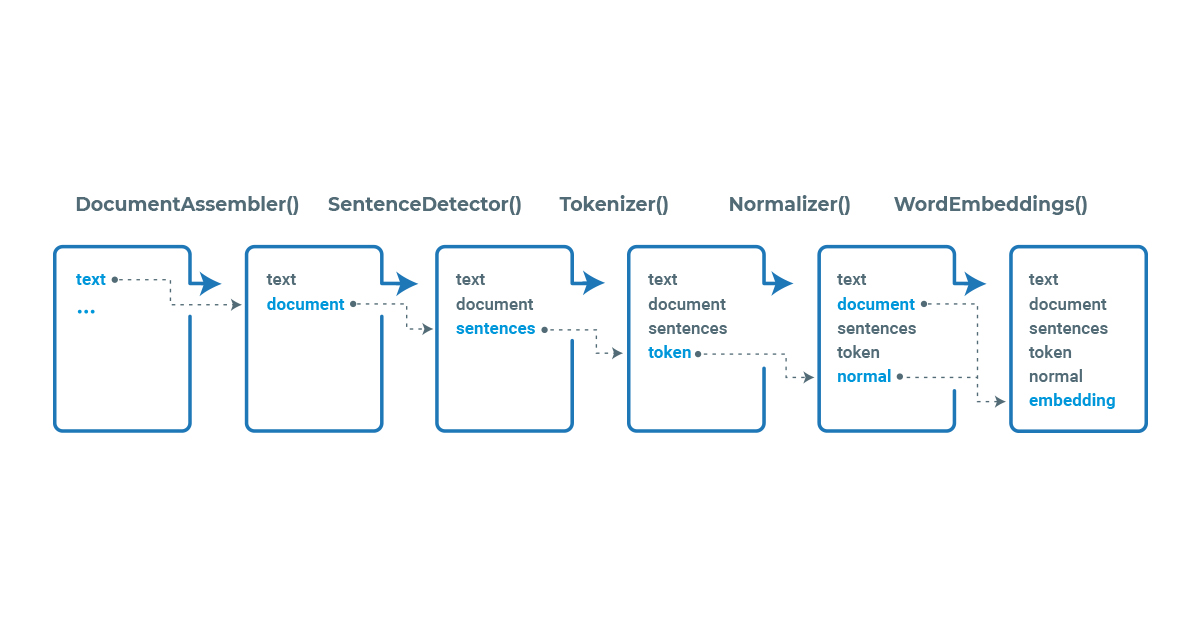
Example pipeline in Spark NLP
Each stage of the pipeline is created by an annotator that uses one or more of the previous information to create new annotation. Each annotator can be of two types, AnnotatorModel which can be used to make predictions based on pretrained models and the AnnotatorApproach which can be used to train new custom models. Pretrained models can be found in the NLP Models Hub.
As part of the spark ecosystem, before using the library we need to start a spark session, which can be done by:
import sparknlp spark = sparknlp.start()
Now that you know about Spark NLP basics, let’s see how to translate texts!
Background
MarianMT is an efficient, free Neural Machine Translation framework written in pure C++ with minimal dependencies. It was developed by the Microsoft Translator team and many academics (most notably the University of Edinburgh and in the past the Adam Mickiewicz University in Poznań) and commercial contributors help with its development.
The model is based on an encoder-decoder transformers architecture and achieved excellent results. It is still the core of the Microsoft Translate tool. In Spark NLP, the model is implemented by the MarianTransformer annotator and there are more than three hundred pretrained models available on NLP Models Hub.
Currently, the models can perform translations between English and more than 150 other langues and dialects. English is used as a bridge between languages because it is the language with the most resources to train models, and the most reliable one as well. By using these models in pipelines, we can obtain translations for most of the applications.
Let’s see how to use them!
Setup and Import Libraries
First, let’s import the required annotators and classes and start the spark session.
import sparknlp from sparknlp.base import LightPipeline, Pipeline, DocumentAssembler from sparknlp.annotator import SentenceDetectorDLModel, MarianTransformer from pyspark.sql import functions as F # Start the spark session spark = sparknlp.start()
LightPipeline and Pipeline create processing pipelines to execute the annotators in some sequence. DocumentAssembler transforms raw texts into DOCUMENT annotations, SentenceDetectorDLModel splits the documents into sentences and the MarianTransformer translates the sentences.
The translator annotator has a few parameters that is worth explaining:
langId: The language code (e.g., “en”, “fr”, “pt”, “tr” etc.) for the input language of multilanguage models that accepts many languages as input. (Default: “”)maxInputLength: Controls the maximum length for the tokenized input sequence (source language SentencePieces), by default 40.maxOutputLength: Controls the maximum length for the output sequence (target language texts), by default 40. If this parameter is smaller thanmaxInputLength, thenmaxInputLengthwill be used instead, meaning the the maximum output length will be the maximum value betweenmaxInputLengthandmaxOutputLength
The default model is "opus_mt_en_fr", default language is “xx” (meaning multi-lingual), if no values are provided, and any parameter can be set using the corresponding set method in CamelCase. For example, we can set the language maximum input length to 100:
marian_model = MarianTransformer.pretrained().setMaxInputLength(100)
Now let’s run some model in example sentences. First, we will translate English to French using the default model.
documentAssembler = DocumentAssembler().setInputCol("text").setOutputCol("document")
sentence = (
SentenceDetectorDLModel.pretrained("sentence_detector_dl", "xx")
.setInputCols("document")
.setOutputCol("sentence")
)
marian = (
MarianTransformer.pretrained()
.setInputCols("sentence")
.setOutputCol("translation")
.setMaxInputLength(30)
.setMaxOutputLength(30)
)
pipeline = Pipeline().setStages([documentAssembler, sentence, marian])
data = spark.createDataFrame(
[["What is the capital of France? We should know this in french."]]
).toDF("text")
result = pipeline.fit(data).transform(data)
result.selectExpr("explode(translation.result) as translation").show(truncate=False)
+-------------------------------------+ |translation | +-------------------------------------+ |Quelle est la capitale de la France ?| |On devrait le savoir en français. | +-------------------------------------+
We can see that the sentences were split by the SentenceDetectorDLModel and we have both translated to French. Now, let’s see how to use a multilanguage model to translate to an example sentence in Turkish to English. We will use the opus_mt_mul_en model (xx stands for multilanguage):
marian = (
MarianTransformer.pretrained("opus_mt_mul_en", "xx")
.setInputCols("document")
.setOutputCol("translation")
.setLangId("tr")
)
pipeline = Pipeline().setStages([documentAssembler, sentence, marian])
Let’s send an example sentence to a spark data frame to use the model in it:
data = spark.createDataFrame(
[["Bu adam 50 yaşında ve çok çalışkan"]]
).toDF("text")
result = pipeline.fit(data).transform(data)
result.selectExpr("explode(translation.result) as translation").show(truncate=False)
Obtaining the translation:
+-----------------------------------------------+ |translation | +-----------------------------------------------+ |This guy is 50 years old and working very hard.| +-----------------------------------------------+
Usage with LightPipeline
- LightPipelineis a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference to execution does not hold to Spark principles, instead, it computes everything locally (but in parallel) to achieve faster inference when dealing with lesser amounts of data. This means, we don’t have to Spark data frame, but a string or an array of strings instead, to be annotated. To create LightPipelines, you need to input an already trained (fit) Spark ML Pipeline.
- It’s
transform()stage is converted intoannotate()orfullAnnotate()
Let’s create a pipeline with MarianTransformer, and run it with LightPipeline and see the results with an example text. This time, we will use a model to translate Italian to English.
text = """La Gioconda è un dipinto ad olio del XVI secolo creato da Leonardo. Si tiene al Louvre di Parigi."""
marian = (
MarianTransformer.pretrained("opus_mt_it_en", "xx")
.setInputCols(["sentences"])
.setOutputCol("translation")
)
nlp_pipeline = Pipeline(stages=[documentAssembler, sentencerDL, marian])
empty_df = spark.createDataFrame([['']]).toDF('text')
pipeline_model = nlp_pipeline.fit(empty_df)
lmodel = LightPipeline(pipeline_model)
We first use the .fullAnnotate() method to obtain the translations and keep the annotation objects. The inference is done directly on the string, without the need to create a spark data frame. The output format is a list of dictionaries containing the annotations.
res = lmodel.fullAnnotate(text)
for i, sentence in enumerate(res[0]['translation']):
print(f"Translation of sentence {i}:")
print (f"\t{sentence.result}")
print("Metadata:\n")
print(f"\t{sentence. Metadata}")
Translation of sentence 0:
La Gioconda is an oil painting of the sixteenth century created by Leonardo.
Metadata:
{'sentence': '0'}
Translation of sentence 1:
It's held at the Louvre in Paris.
Metadata:
{'sentence': '1'}
If the metadata present in the annotation objects is not relevant for your application, then you can use the .annotate() method to obtain the .result part of the annotations only:
res = lmodel.annotate(text)
print('Translated:\n')
for sentence in res['translation']:
print(sentence)
Original: La Gioconda è un dipinto ad olio del XVI secolo creato da Leonardo. Si tiene al Louvre di Parigi. Translated: La Gioconda is an oil painting of the sixteenth century created by Leonardo. It's held at the Louvre in Paris.
Note 1: We used the SentenceDetectorDL annotator to split the texts into sentences. This is optional as the model can translate full texts too (remember to set the maxInputLength accordingly).
Note 2: In some cases, you may be interested in first detecting the input language to then apply the translator associated to that language. For this scenario, it is possible to use another annotator called LanguageDetectorDL that is based in a deep learning architecture to identify more than two hundred languages.
Conclusion
We introduced the MarianTransformer annotator in Spark NLP and showed how to perform neural machine translation tasks in the spark ecosystem that could be easily scaled. The MarianMT model achieves excellent results in translation between many languages, and with the amount of pretrained models most of the NMT applications can be implemented in Spark NLP.
References:
- Documentation: MarianTransformer
- Python Docs: MarianTransformer
- Scala Docs: MarianTransformer
- For academic reference, see Marian: Fast Neural Machine Translation in C++.
- For additional information, see NMarianNMT at GitHub.




